




文章目录
1 要点
题目:基于知识感知的动态图表示
代码:https://github.com/WonderLandxD/WiKG
已有问题:
- 已有的MIL方法过度依赖关键实例,忽视实例之间的结构联系;
- 当前主流GNN方法的图结构基于空间位置,限制了远程交互;
- 传统GNN和MIL忽略了边的信息建模。
研究目标:
旨在针对病理全切片图像(WSI)分析中存在的建图僵化、语义交互不足与泛化性能低等问题,提出一种融合动态有向图构建与知识感知注意力机制的端到端方法——WiKG。通过图结构的自适应建模与更细粒度的信息聚合策略,推动 WSI 分类任务在准确性与泛化性两个维度的性能突破:
- 构建一种适用于WSI的动态图建模机制;
- 设计一个知识感知的注意力机制来提升信息聚合能力;
- 提升WSI分类模型的性能与泛化能力。
. 数据集
- TCGA-ESCA(食管癌)
- TCGA-KIDNEY(肾癌)
- TCGA-LUNG(肺癌)
- FROZEN-LUNG(冷冻肺癌样本)
2 摘要
组织病理学的全切片图像 (WSI) 分类在医学显微图像处理中成为了一个基本任务。主流方法涉及将WSI作为实例包进行表征学习,其侧重于识别关键实例,但难以去捕捉实例间的交互关系。此外,传统的图像表示方法利用显式空间位置去构建拓扑结构,这限制了相距较远实例之间的灵活交互能力。对此,我们提出一个新颖的动态图表示算法,即将WSI建模为类似知识图像的结构。具体而言,我们基于实例之间的“头实体”和“尾实体”关系动态构建邻居与有向边的嵌入;随后,设计了一种知识感知注意力机制,它可以通过学习每个邻居和边的联合注意力分数来升级头节点特征表示;最后,通过全局池化升级头节点来获得一个图像级嵌入,用于WSI分类的隐式表示。
3 引入
传统组织病理学诊断是通过光学显微镜人工检查病理切片来完成的。然而,由于环境改变和老龄人口增长等社会因素的影响,这种诊断方法正在面临重大挑战。随着数字扫描技术的发展,物理切片现在可以被转化成高分辨率WSI,它可以保存完整的病理组织信息。这一技术极大地提升了病理学的工作效率,同时也激发了对智能WSI诊断工具的需求。
近年来,多项研究通过不断探索深度学习在WSI的应用取得了显著结果。然而,对WSI的专业解释及其大规模数据种类使获得像素级别的人工标注极为困难。为了缓解这个问题,研究人员开发了弱监督算法,它可以只需要切片级别标签就能被训练。当前,大多数WSI研究都基于嵌入式的多示例学习 (MIL) 框架,该方法把WSI分割成多个图像块并对其嵌入信息进行聚合。然而,MIL过度关注每个实例对整体表征的影响而忽略了实例之间的关系。这些相互关联往往能揭示肿瘤潜在的发展趋势,提供病理学家更深度的关系见解,有助于肿瘤微环境的建造。例如,癌细胞和炎症细胞间的相互作用有助于分析肿瘤包和临床预后。图神经网络 (GNN) 正逐渐成为WSI分析的有力工具,这主要是因为他们更关注实体拓扑结构内的局部相似性。GNN把WSI表示为图结构,把组织切片看作节点,通过节点间的相互传递并聚合切片的特征信息,最终获得获得图级别的表征。
基于图结构的WSI分析方法目前主要通过切片的空间位置关系进行建模。尽管这些方法已经取得一些成功,但他们仍存在一些缺陷:
- 显式的空间拓扑限制了远距离实体间的信息交互能力;
- WSI中的GNN通常被建模为无向图,忽略了相邻实体的方向性贡献;
- 在WSI分析中的GNN的过度参数化可能导致过度适配,会减少普化能力。
为此,我们提出了一种基于知识感知注意力的动态图像表示方法 (WiKG),它充分利用实体间的相互作用来分析WSI:
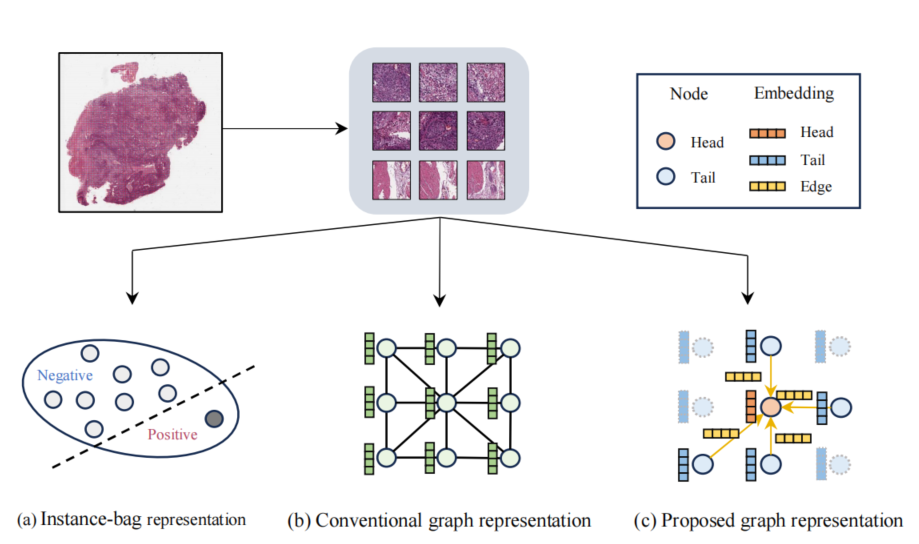
- 为每个图像块分别构建头尾嵌入来模拟WSI中的有向图结构,图1表现了我们的方法与传统建图方式的区别;
- 基于头尾实体间的相互作用设计了边嵌入,并构建了一个知识感知注意力机制来聚合相邻信息。这个机制将头实体、尾实体与边嵌入整合为相邻知识属性,使更多有价值的实体能传播更实用的信息。
为了验证方法的有效性,在3个公共TCGA基准数据集进行广泛的评估,包括食管癌,良性肿瘤和肺癌的分型与分期;收集了内部冷冻切片肺癌全切片图像用于外部测试来展示方法的普适化能力。通过对比各种最先进的WSI分析方法,证明了WiKG在WSI分析任务中的优越性。
4 相关工作
4.1 MIL在WSI中的应用
鉴于MIL理论和病理学家的诊断过程的高度一致性,开发用于WSI分析的MIL算法已成为主要的研究趋势,这类模型以实例包的形式构建。最早,研究人员尝试基于实例评分生成WSI预测。随着基于嵌入的MIL方法的发展,因其更稳定的收敛性和更优的性能,研究趋势逐渐转向该方法。传统的基于嵌入的MIL方法将WSI压缩为嵌入表征,并聚合为WSI级别特征以进行最终预测。例如,ABMIL通过学习每个实例的注意力分数,执行加权聚合来获得该表征。Lu等人通过引入聚类约束损失和单/多实例分支注意力机制改进ABMIL。Li等人提出双流网络去捕获在最可疑正例和其他实例之间的潜在关系。Shao等人将Transformer引入到MIL框架来实现更高效的实例表征更新。Zhang等人基于ABMIL,引入伪包概念来加强注意力信息,并提出特征蒸馏策略,以在伪包级别来融合表征。尽管这些方法尝试提升WSI的分类表现,但仍然缺乏对组织切片信息交互的表征能力。
4.2 数字病理学中的图表示方法
通过组织学表型和拓扑分布特征决定的肿瘤微环境,在病理学诊断中至关重要。基于图的深度学习方法在编码表征和捕获节点内外交互上表现良好,已在数字病理学中获得广泛关注。
例如,Zhou等人和Chen等人通过细胞的空间位置构建边,并结合手工特征形成细胞图像表征。
由于深度学习的高效特征提取能力,在细胞层级训练神经网络可以提升细胞图性能。部分研究通过整合组织区域和细胞的表征来构建拓补结构。
例如,HACT-Net结合组织和细胞图表征,对乳腺癌亚型组织病理学关注区域进行分类。SHGNN构建了空间的分层GNN框架,在组织与细胞结构上联合表征学习。
随着WSI分析需求的增长,以图像区块作为基本单元的图表示方法也被广泛讨论。
例如,Chen等人通过分层聚合WSI的特征,对肿瘤微环境建模局部和全局拓扑结构。Zheng等人结合WSI的空间表征和Transformer来预测疾病等级。Hou等人开发了一种具有高分辨属性的异构图,用于建模不同尺度的空间关系。Zhao等人构建了一个基于GNN和Transformer的多任务学习框架。Chan等人利用不同细胞核之间的关系,将WSI表示为异构图。
虽然这些方法取得了较好的成果,但大都依赖固定空间构图方式来创造边,限制了模型自由探索相互信息的能力。同时,他们未能充分考虑图像块间交互的方向性与复杂性。
5 方法
在这个部分,我们介绍提出的WiKG,包括动态图构建和知识感知注意力机制,如图2。

5.1 动态图构建
与传统方法利用空间位置关系构建图结构不同,我们的方法致力于利用可学习的隐式特征来量化图像块之间的位置关系。对于给定的WSI,首先使用Otsy阈值算法区分前景组织区域,并通过滑动窗口操作将其划分为不重叠的图像块:
X
=
{
x
1
,
x
2
,
…
,
x
n
}
(1)
\tag{1} X=\{x_1,x_2,\dots,x_n\}
X={x1,x2,…,xn}(1)这些图像块被定义为图节点。接着使用特征编码器
f
f
f (例如基于ImageNet预训练的ViSion Transformer模型) 获取其嵌入表示。随后使用2个不同的线性层,把这些嵌入分别映射为头部和尾部嵌入结构。头部用于探索图像块和它之间的协调性,尾部用于探索当前图像块对其他图像块的贡献:
h
i
=
W
h
f
(
x
i
)
,
t
i
=
W
t
f
(
x
i
)
(2)
\tag{2} h_i = W_h f(x_i), \quad t_i = W_t f(x_i)
hi=Whf(xi),ti=Wtf(xi)(2)
h
i
h_i
hi和
t
i
t_i
ti分别表示第
i
i
i个图像块的头部和尾部嵌入。通过点乘计算所有图像块的头部和尾部之间的相似性,并使用softmax函数对其进行归一化:
ω
i
,
j
=
h
i
T
t
j
∑
j
=
1
N
h
i
T
t
j
(3)
\tag{3} \omega_{i,j} = \frac{h_i^T t_j}{\sum_{j=1}^N h_i^T t_j}
ωi,j=∑j=1NhiTtjhiTtj(3)
ω
i
,
j
\omega_{i,j}
ωi,j表示第
i
i
i个图像块的头部
i
i
i和第
j
j
j个图像块的尾部之间的相似性分数。对于每一个图像块
i
i
i,选择相似度得分最高的前
k
k
k个图像块作为其邻居:
N
(
i
)
=
{
j
∈
V
∣
ω
i
,
j
∈
Top
k
{
ω
i
,
j
}
j
=
1
N
}
(4)
\tag{4} \mathcal{N}(i) = \{ j \in V \mid \omega_{i,j} \in \text{Top}_k\{\omega_{i,j}\}_{j=1}^N \}
N(i)={j∈V∣ωi,j∈Topk{ωi,j}j=1N}(4)
V
V
V表示所有图像块的集合,
∣
V
∣
=
N
|V|=N
∣V∣=N,
∣
N
(
i
)
∣
=
k
|N(i)|=k
∣N(i)∣=k。
每条有向边可以分配一个边嵌入,用于表达从图像块
j
j
j到
i
i
i的信息流关系:
r
i
,
j
=
ω
i
,
j
t
j
+
(
1
−
ω
i
,
j
)
h
i
,
∀
j
∈
N
(
i
)
(5)
\tag{5} r_{i,j} = \omega_{i,j} t_j + (1 - \omega_{i,j}) h_i, \quad \forall j \in \mathcal{N}(i)
ri,j=ωi,jtj+(1−ωi,j)hi,∀j∈N(i)(5)该边嵌入是头部节点和尾部节点的加权组合,通过上述操作,WSI可以表示为动态图结构:
G
=
(
V
,
E
,
F
,
R
)
(6)
\tag{6} G = (V, E, F, R)
G=(V,E,F,R)(6)V表示图像块集合,E表示边集合,F表示头尾嵌入集合,R表示有向边嵌入集合。
进一步三元组集合可以定义为:
ε
=
(
h
,
r
,
t
)
:
(
h
,
t
)
∈
F
,
r
∈
R
(7)
\tag{7} ε = {(h, r, t) : (h, t) ∈ F, r ∈ R}
ε=(h,r,t):(h,t)∈F,r∈R(7)用于描述每条有向边的头节点、尾节点以及其对应的边嵌入。
5.2 知识感知注意力机制
为了充分利用上述图结构节点间的关系,受推荐系统启发,提出知识感知注意力机制,用于实现节点间信息的传播和聚合。 对于图像块
i
i
i,计算其邻居
N
(
i
)
N(i)
N(i)尾部节点嵌入线性组合,来表征其一阶连接结构:
h
N
(
i
)
=
∑
j
∈
N
(
i
)
π
(
h
i
,
r
i
,
j
,
t
j
)
⋅
t
j
(8)
\tag{8} h_{\mathcal{N}(i)} = \sum_{j \in \mathcal{N}(i)} \pi(h_i, r_{i,j}, t_j) \cdot t_j
hN(i)=j∈N(i)∑π(hi,ri,j,tj)⋅tj(8)
π
(
h
,
r
,
t
)
π(h,r,t)
π(h,r,t)是权重因子,用于指导每个来自尾部节点的信息被传播到头部节点的程度。使用三元组的非线性组合来计算
π
(
h
,
r
,
t
)
π(h,r,t)
π(h,r,t):
π
(
h
i
,
r
i
,
j
,
t
j
)
=
t
j
⊤
tanh
(
h
i
+
r
i
,
j
)
(9)
\tag{9} \pi(h_i, r_{i,j}, t_j) = t_j^\top \tanh(h_i + r_{i,j})
π(hi,ri,j,tj)=tj⊤tanh(hi+ri,j)(9)
tanh
(
⋅
)
\tanh(\cdot)
tanh(⋅)是双曲正切激活函数,既能保留正向信息也能保留负向信息,有助于实现合适的梯度流。该组合方式能够评估尾节点与头节点之间的“接近程度”,从而区分不同邻居的重要性。
接着,使用softmax函数对所有邻居节点的评分进行归一化:
π
(
h
i
,
r
i
,
j
,
t
j
)
=
exp
(
π
(
h
i
,
r
i
,
j
,
t
j
)
)
∑
j
∈
N
(
i
)
exp
(
π
(
h
i
,
r
i
,
j
,
t
j
)
)
(10)
\tag{10} \pi(h_i, r_{i,j}, t_j) = \frac{\exp(\pi(h_i, r_{i,j}, t_j))}{\sum_{j \in \mathcal{N}(i)} \exp(\pi(h_i, r_{i,j}, t_j))}
π(hi,ri,j,tj)=∑j∈N(i)exp(π(hi,ri,j,tj))exp(π(hi,ri,j,tj))(10)通过这种方式,将三元组中的关系建模为边知识信息,使头节点能被感知和接收来自尾节点的信号,并有效地捕获它们。图3展示了提出的知识感知注意力机制的实现方式。最终,融合邻居聚合信息与原始信息来形成一个新的头表征。采取一种双向交互机制来促进更多节点间的信息交换:
h
i
=
σ
1
(
W
1
(
h
i
+
h
N
(
i
)
)
)
+
σ
2
(
W
2
(
h
i
⊙
h
N
(
i
)
)
)
(11)
\tag{11} h_i = \sigma_1(W_1(h_i + h_{\mathcal{N}(i)})) + \sigma_2(W_2(h_i \odot h_{\mathcal{N}(i)}))
hi=σ1(W1(hi+hN(i)))+σ2(W2(hi⊙hN(i)))(11)
σ
\sigma
σ表示激活函数,如LeakyReLU,
W
W
W表示可学习的变换矩阵,
⊙
\odot
⊙表示逐元素乘法。
最后,使用全局池化操作 (Readout) 生成图级嵌入,并通过softmax函数输出WSI的预测结果:
Y
^
=
Softmax
(
Readout
(
G
)
)
(12)
\tag{12} \hat{Y} = \text{Softmax}(\text{Readout}(G))
Y^=Softmax(Readout(G))(12)Readout表示均值池化或最大池化之类的全局池化层,
Y
^
\hat{Y}
Y^表示预测概率。
在训练过程中,我们采用交叉熵损失函数作为 WSI 分类任务的目标函数,定义如下:
L
c
e
=
−
1
M
∑
m
=
1
M
∑
c
=
1
C
Y
m
,
c
ln
(
Y
^
m
,
c
)
(13)
\tag{13} \mathcal{L}_{ce} = -\frac{1}{M} \sum_{m=1}^{M} \sum_{c=1}^{C} Y_{m,c} \ln(\hat{Y}_{m,c})
Lce=−M1m=1∑Mc=1∑CYm,cln(Y^m,c)(13)
C
C
C表示类别数量,
M
M
M表示训练样本数,
Y
Y
Y表示one-hot编码的标签。
6 实验
本节介绍提出的WiKG方法与其他先进WSI算法在3个公开组织病理学基准数据集上的性能表现。此外,还进行了消融实验,探讨了边构建方式、知识感知注意力机制、邻居节点的数量、模型收敛性和运行效率。最后,使用内部测试集做额外的实验来展示训练模型的泛化能力。
6.1 数据集
3个来自TCGA项目的公开临床基准数据集被用于性能评估,分别是ESCA,KIDNEY,和LUNG。针对每个数据集进行肿瘤类型和肿瘤分期的二分类实验。TCGA-ESCA包含375例食管癌队列,包括腺癌 (类别1) 和鳞状细胞癌 (类别2)。
TCGA-KIDNEY包含一个肾癌病例队列,共1233例,包括嗜酸细胞型肾癌(类别1)、透明细胞型肾癌 (类别2) 和乳头状肾细胞癌 (类别3)。TCGA-LUNG包含一个肺癌病例队列,共2121例,包括鳞状细胞癌 (类别1) 和腺癌 (类别2)。
在肿瘤分期任务中,所有病例根据TNM分期标准被划分为 I、II、III 和 IV 四个阶段。
在预处理阶段,将每张WSI图像放大20倍,被分为256*256非重叠的图像块。所有实验均报告AUC指标,因为它具有全面性和且对类别不平衡不敏感性。此外,还报告了准确性和加权FI-score的。这些评估指标基于0.5的阈值进行计算。通过4折交叉验证获得所有基于TCGA数据集中的结果,每项指标均以百分比形式呈现,并附有标准误差。可视化Camelyon16数据集中构建的图结构,该数据集具有像素级的的肿瘤掩膜注释,适合用于图结构的展示。为了更好地评估提出的方法泛化能力,还在一个内部测试集上进行了实验。该测试集包含170例真实的冰冻切片WSI,均来自中山大学第一附属医院,包括鳞状细胞癌 (类别1) 和腺癌 (类别2),命名为FROZEN-LUNG。
6.2 实施细节
所提出的方法在Nvidia RTX3090 GPU上使用Python中的Pytorch库实现。为采用单块GPU并便于后续研究,我们使用了一个在ImageNet上预训练的ViT Small模型作为编码器。关于使用病理学图像上训练的领域特定编码器进行的对比实验,请参考补充材料。为每个图像块提取了384维的特征向量,然后通过一个全连接层扩大它至512维,形成图像块的最终特征表征。批量大小设为1,表示每次迭代只处理一张切片。在Top-k中, k k k值设为6,意味着每个图像块将与其他6个图像块建立连接关系。设置训练周期数为100,并使用Adam来更新模型权重,其学习率为 1 0 − 4 10^{-4} 10−4和权重衰减率为 1 0 − 5 10^{-5} 10−5。在获得图级嵌入表示前,应用了0.3的丢失率。所有其他基线方法均采用相同参数配置进行实验。
6.3 与其他已有工作的比较
在表1和表3中,分别展示了3个公开数据集的肿瘤分型和分期结果,并用接下来的9种前沿的方法进行对比:(1) ABMIL,一种MIL框架,它通过注意力机制聚合实例信息来获得包级嵌入。(2) CLAM-SB,采用聚类约束损失优化的单门控注意力MIL框架。(3) CLAM-MB,CLAM-SB的加强版,使用多门控注意力机制。(4) DSMIL,一种双流MIL方法,通过非局部注意力池化和最大化池化聚合图像块嵌入。(5) TransMIL,一种采用Transformer和多尺度位置编码模块的类MIL范式。(6) DTFD-MIL,一种双层MIL框架,通过引入伪包和特征蒸馏开发。(7) HIPT,一种利用金字塔式WSI结构的层级化视觉Transformer架构。(8) GTP,整合图结构与Transformer的图表示方法。(9) Patch-GCN,基于层级图结构的WSI生存预测方法,采用全局注意力池化作为图表示模型。我们方法展示了比MIL和图像表征更优的表现,这表明WiKG可能能更好地捕获图像块之间的相互作用,从而获得更多综合的全局信息。尤其在肿瘤分期任务中,F1分数的提升明显高于准确率指标,这表明WiKG模型在细分肿瘤恶性程度界定方面有显著优势。必须承认,影响WSI的分期的因素通常包括肿瘤种类,它的尺寸,攻击其他相邻组织器官的范围,癌症细胞在用于淋巴结中的数量以及是否存在远处转移。目前该领域采用的大多数算法都是从打字任务开发的算法该进而来。在接下来的工作中,我们将探讨用于肿瘤分期的深度学习方法。

6.4 提出边构建的有效性
构建基于头部和尾部关系的有向边的策略,在建立拓补结构方面展现出高效率。在表4中,报告了我们的方法和两种传统的动态边构建算法的对比分析,性能指标为AUC。具体而言,k-NN(距离)和k-NN(余弦)分别通过计算特征嵌入之间的欧氏距离和余弦相似度来识别相似度最高的前k个索引,并保持其他结构不变。值得注意的是,我们方法在3个数据集的两种WSI分析任务中,比其他2个基于k-NN方法表现更好,领先1%-3%,这表明边构建策略可能更符合组织的微环境的表征。

6.5 知识感知注意力机制的有效性
我们与其他主流的GNN架构进行一个对比优势分析,以进一步证实WiKG模型的优越表现。用4种不同的GNN架构替代了原有的知识感知注意力机制更新策略,这4种架构分别是:图卷积网络(GCN)、图同构网络(GIN)、GraphSage(SAGE)以及图注意力网络(GTA)。模型的所有其他结构保持不变。表5展示了WiKG方法与不同GNN架构的性能对比,证明了我们方法在3种WSI分型任务中、AUC指标下的优越性。尤其在食管癌分析中,所提出方法的准确率提升了近2%。值得注意的是,GAT同样是一种通过注意力分数聚合节点特征的GNN框架。尽管如此,其表现仍不及WiKG,这表明WiKG在捕捉邻居节点有效信息方面可能更具优势。
6.6 相邻节点数量的影响
我们还对不同数量的邻居节点进行了分析实验。图4描述了WiKG方法在3种TCGA数据集上,针对不同邻居节点数量在分型和分期任务中的准确度和AUC分数。总体而言,邻居节点数量对WiKG的性能影响不大。尽管在TCGA-ESCA的分期实验中,准确度指标存在波动,但考虑到各分期样本数量不均,这种波动是合理的。与此同时,这也可能与食管癌固有的形态多样性和复杂性有关。

6.7 收敛性和时间效率
过度参数化的问题会导致GNN收敛性的不稳定以及增加训练时间。我们在TCGA-ESCA分期任务中对比Patch-WiKG和GTP。图5对比了收敛曲线和每个训练周期的耗时。WiKG在训练过程中快速收敛且未出现Patch-GCN and GTP中过拟合现象。同时,在单个周期的训练速度方面,WiKG也是最迅速的,且参数量最小。

6.8 可视化和进一步实验
通过WiKG构建有向图结构的可视化,我们得以直观理解细胞斑块间的潜在关联,进一步帮助建立了组织内癌细胞的关系网络且丰富了肿瘤微环境的表征。图6展示了基于Camelyon16数据集的可视化结果。我们观察到,含有转移癌的病理切片更倾向于选择包含大量淋巴细胞的邻近切片作为相邻区域,并以部分脂肪和纤维组织作为补充。值得注意的是,具有最高知识感知注意力分数 (编号5) 的切片含有更高密度的淋巴瘤,这表明包含转移癌的切片会更多地关注含有更多病灶特征的区域。我们还在FROZEN-LUNG数据集上对TCGA-LUNG数据集训练好的模型进行了进一步测试实验,旨在评估各方法的泛化性能与应用前景。表6提供了与其他方法的对比分析,证明WiKG具有更优的综合性能。同时,还展示了各类别的Accuracy指标结果,如图7所示。具体而言,WiKG对两种肺亚型均具有优异的识别能力,且各类别的标准差也远小于其他方法。但其他MIL方法的泛化能力均无法与WiKG相提并论。



在这个实验中可以观察到一些有趣的结果。对于大多数方法,尤其是TransMIL,在AUC和准确度/FI分数中有很大的不同。虽然它的准确度和FI分数相对低,但是它的AUC通常很高,尤其是针对鳞状细胞癌,其准确率提高了近44%比腺癌细胞。这可能因为训练数据的规模不平衡所致,即训练集中特定类别越多,它的测试准确率就越高。然而,除TransMIL、ABMIL和DTFD-MIL外,其他方法均显示出相反的结果。我们也观察到其他方法通常遇到两个问题:不同类别间准确率存在显著差异和特定类别准确率的高标准差。这表明某些已有的研究可能存在拟合问题,并对特定类别表现出更高的敏感性。相比之下,WiKG方法显著缓解了这两个问题。
7 总结和未来研究
在这篇文章,我们介绍了一种新的动态图表示方法 (即WiKG) 来分析WSI。通过建模头尾嵌入相互关系,并构建一种知识感知注意力机制来聚合相邻信息,WiKG释放了图像块探索其拓扑结构中相互关系的能力,并使用实体间的定向贡献来增强图像块的相互作用,来获得更好地WSI分析性能。通过对三个公共基准数据集和内部测试集的大量实验与消融研究,证明了WiKG的有效性和更优异的泛化性能。在未来的工作中,我们将重点关注WiKG在WSI中的可解释性,并探索图池化对WSI的影响。我们还将深入探究全切片图像分析任务的泛化性问题,因为现有研究方法可能不具备良好的泛化性能。

















 764
764

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









