




 本文探讨了多种PyTorch优化器对模型训练的影响,包括Adagrad、Adam、Adamax、ASGD、LBFGS、RMSprop、Rprop和SGD。特别地,LBFGS优化器需要一个闭包来反复计算损失,而其他优化器的使用则相对直接。通过绘制损失变化图像,展示了不同优化器在训练过程中的表现差异。
本文探讨了多种PyTorch优化器对模型训练的影响,包括Adagrad、Adam、Adamax、ASGD、LBFGS、RMSprop、Rprop和SGD。特别地,LBFGS优化器需要一个闭包来反复计算损失,而其他优化器的使用则相对直接。通过绘制损失变化图像,展示了不同优化器在训练过程中的表现差异。
作业内容:使用不同优化器训练模型,画出不同优化器的损失(Loss)变化图像。
- torch.optim.Adagrad
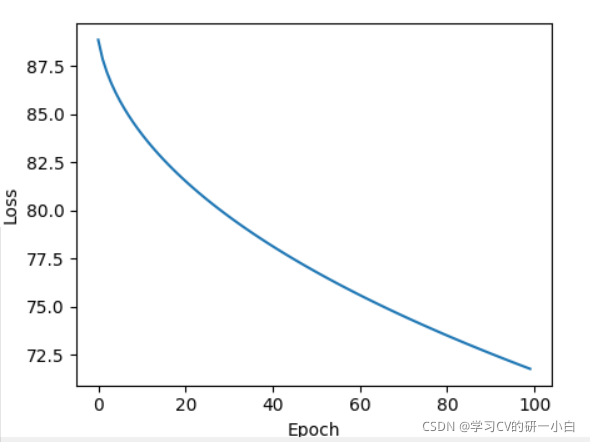
- torch.optim.Adam
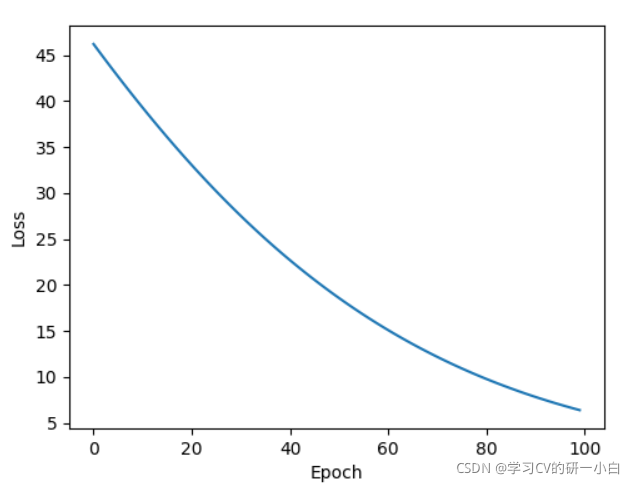
- torch.optim.Adamax
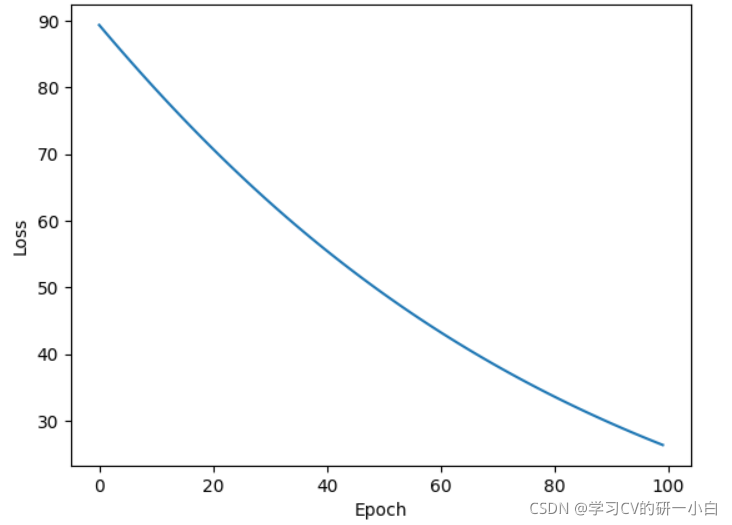
- torch.optim.ASGD
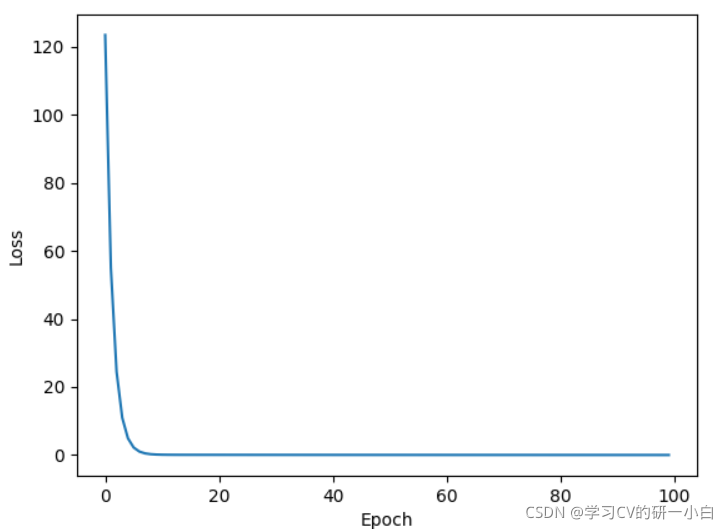
- torch.optim.LBFGS
注意:LBFGS优化器与本篇其他所有优化器不同,需要重复多次计算函数,因此需要传入一个闭包,让他重新计算你的模型,这个闭包应当清空梯度、计算损失,然后返回损失。
闭包代码如下:
def closure():
optimizer.zero_grad()
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
loss.backward()
return loss此时更新函数的代码不再是简化版本:optimizer.step( ),变成如下代码:
#传入闭包closure
optimizer.step(closure)利用LBFGS优化器的Loss变化图像如下图:
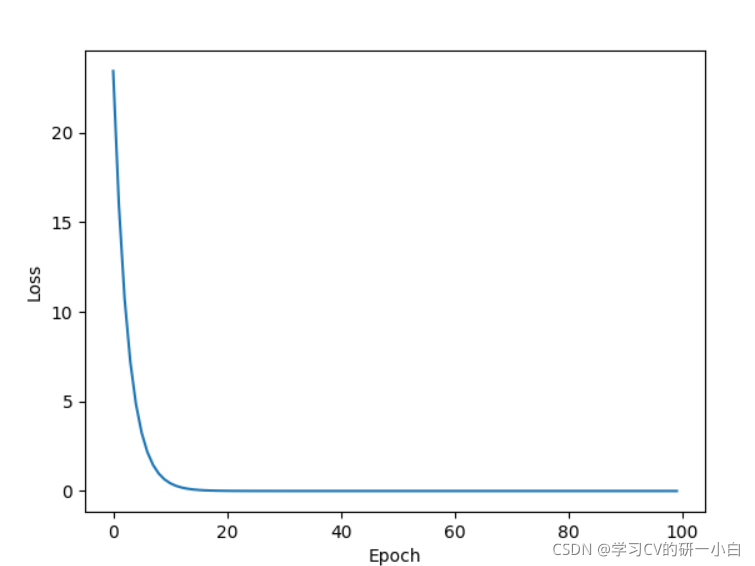
- torch.optim.RMSprop
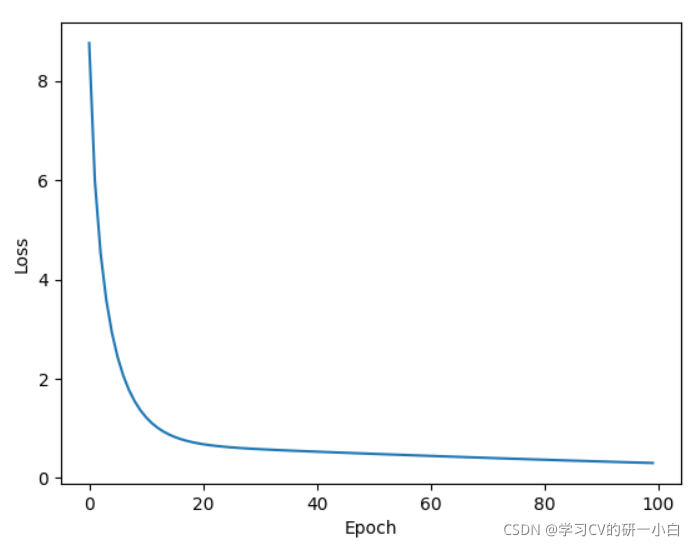
- torch.optim.Rprop
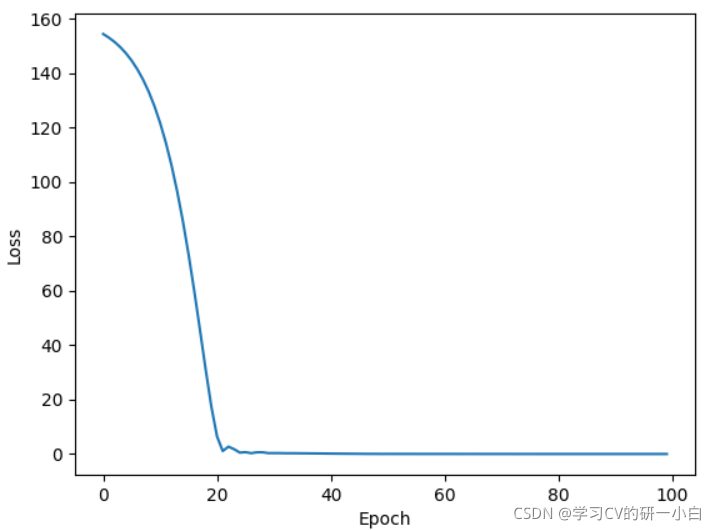
- torch.optim.SGD
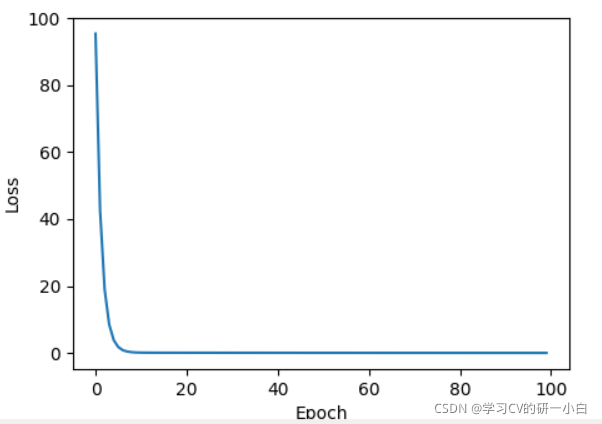
除了LBFGS优化器,其他优化器的使用和P5学习笔记中的代码一样,可以参考链接深度学习——用PyTorch实现线性回归(B站刘二大人P5学习笔记)_Learning_AI的博客-优快云博客
挖一个坑,优化器在函数训练中的作用。



















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











