




本文介绍了LangChain框架,它能够将大型语言模型与其他计算或知识来源相结合,从而实现功能更加强大的应用。接着,对LangChain的关键概念进行了详细说明,并基于该框架进行了一些案例尝试,旨在帮助读者更轻松地理解LangChain的工作原理。
引言
近期,大型语言模型(LLM)如GPT系列模型引领了人工智能领域的一场技术革命。开发者们都在利用这些LLM进行各种尝试,虽然已经产生了许多有趣的应用,但是单独使用这些LLM往往难以构建功能强大的实用应用。
LangChain通过将大型语言模型与其他知识库、计算逻辑相结合,实现了功能更加强大的人工智能应用。简单来说,个人理解LangChain可以被视为开源版的GPT插件,它提供了丰富的大语言模型工具,可以在开源模型的基础上快速增强模型的能力。
在此,我总结了最近对LangChain的学习内容,欢迎各位同学前来交流。LangChain使得语言技术的运用更加活跃多元,它有望在人工智能领域发挥重要作用,推动我们工作效率的变革。我们正处在人工智能爆发的前夜,积极拥抱新技术将会带来全新的体验。
LangChain主要概念与示例
LangChain提供了一系列的工具帮助我们更好的使用大语言模型(LLM)。可以认为主要有6种不同类型的工具:
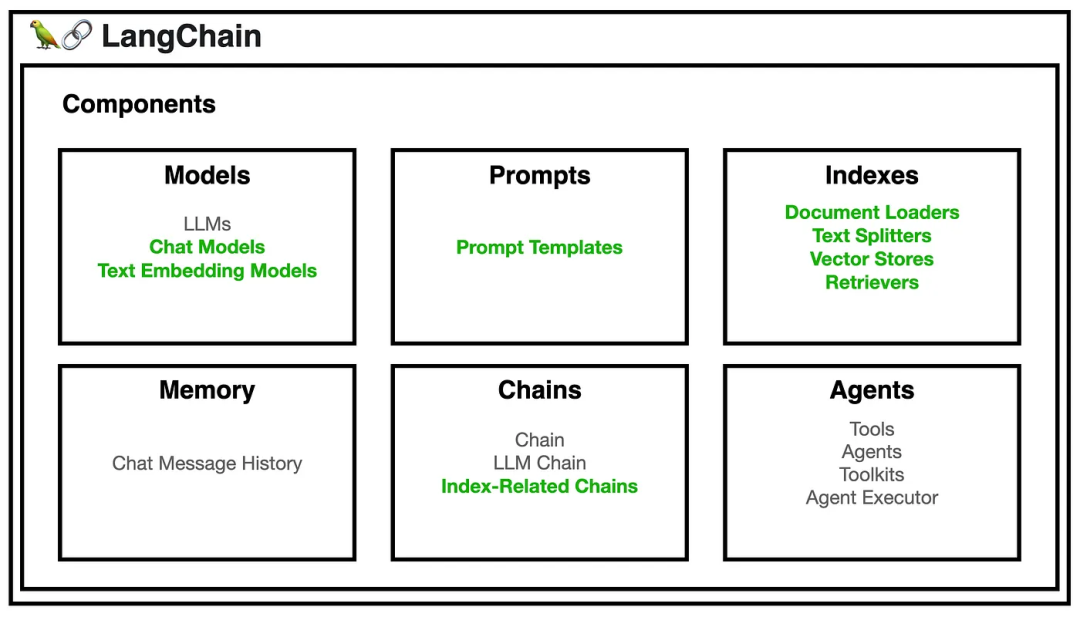
模型(Models)
LangChain的一个核心价值就是它提供了标准的模型接口;然后我们可以自由的切换不同的模型,当前主要有两种类型的模型,但是考虑到使用场景,对我们一般用户来说就是使用一种模型即文本生成模型。
说到模型,大家就理解模型就是ChatGPT就可以。单纯的模型只能生成文本内容。
- 语言模型(Language Models)
用于文本生成,文字作为输入,输出也是文字。
1. 普通LLM:接收文本字符串作为输入,并返回文本字符串作为输出。
2. 聊天模型:将聊天消息列表作为输入,并返回一个聊天消息。
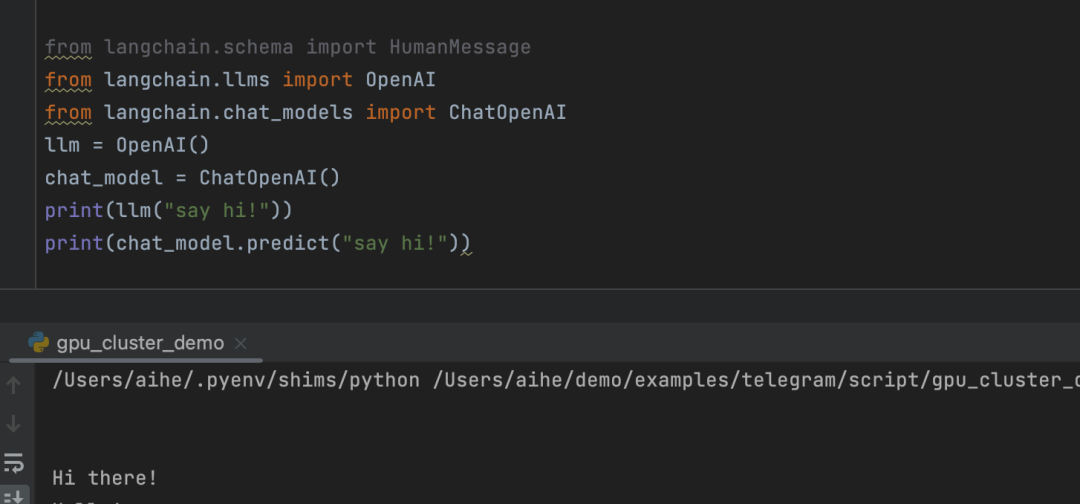
代码案例:
from langchain.schema import HumanMessage``from langchain.llms import OpenAI``from langchain.chat_models import ChatOpenAI``llm = OpenAI()``chat_model = ChatOpenAI()``print(llm("say hi!"))``print(chat_model.predict("say hi!"))

- 文本嵌入模型(Text Embedding Models)
把文字转换为浮点数形式的描述:
这些模型接收文本作为输入并返回一组浮点数。这些浮点数通常用于表示文本的语义信息,以便进行文本相似性计算、聚类分析等任务。文本嵌入模型可以帮助开发者在文本之间建立更丰富的联系,提高基于大型语言模型的应用的性能。
from langchain.embeddings import OpenAIEmbeddings``embeddings = OpenAIEmbeddings()``text = "This is a test document."``query_result = embeddings.embed_query(text)``doc_result = embeddings.embed_documents([text])``print(doc_result)
提示词(Prompts)
提示词是我们与模型交互的方式,或者是模型的输入,通过提示词可以让模型返回我们期望的内容,比如让模型按照一定的格式返回数据给我们。
LangChain提供了一些工具,可以方便我们更容易的构建出我们想要的提示词,主要工具如下:
了解这些工具都是更方便的让我们构造提示词就行了。
语言模型提示词模板PromptTemplates,提示模板可以让我们重复的生成提示,复用我们的提示。它包含一个文本字符串(“模板”),从用户那里获取一组参数并生成提示,包含:
1. 对语言模型的说明,应该扮演什么角色。
2. 一组少量示例,以帮助LLM生成更好的响应。
3. 具体的问题。
代码案例:
from langchain import PromptTemplate`` `` ``template = """``I want you to act as a naming consultant for new companies.``What is a good name for a company that makes {product}?``"""`` ``prompt = PromptTemplate(` `input_variables=["product"],` `template=template,``)``prompt.format(product="colorful socks")``# -> I want you to act as a naming consultant for new companies.``# -> What is a good name for a company that makes colorful socks?
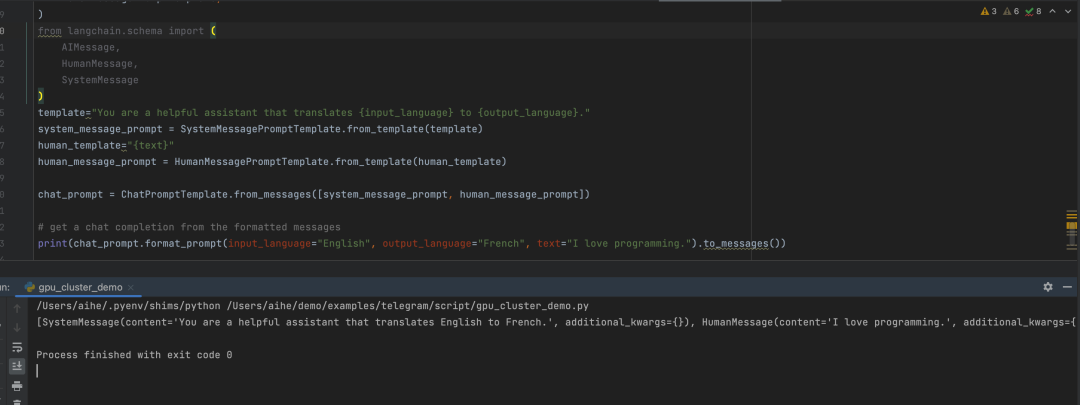
聊天模型提示词模板ChatPrompt Templates,ChatModels接受聊天消息列表作为输入。列表一般是不同的提示,并且每个列表消息一般都会有一个角色。
from langchain.prompts import (` `ChatPromptTemplate,` `PromptTemplate,` `SystemMessagePromptTemplate,` `AIMessagePromptTemplate,` `HumanMessagePromptTemplate,``)``from langchain.schema import (` `AIMessage,` `HumanMessage,` `SystemMessage``)``template="You are a helpful assistant that translates {input_language} to {output_language}."``system_message_prompt = SystemMessagePromptTemplate.from_template(template)``human_template="{text}"``human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)`` ``chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])`` ``# get a chat completion from the formatted messages``print(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
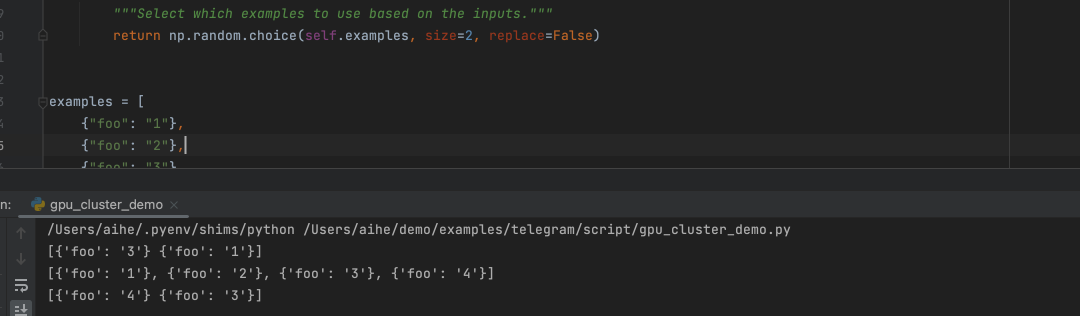
示例选择器Example Selectors,如果有多个案例的时候,使用ExampleSelectors选择一个案例让提示词使用:
1. 自定义的案例选择器。
2. 基于长度的案例选择器,输入长的时候按理会少一点,输入多的时候,案例会多一些。
3. 相关性选择器,选择一个和输入最相关的案例。
from langchain.prompts.example_selector.base import BaseExampleSelector``from typing import Dict, List``import numpy as np`` `` ``class CustomExampleSelector(BaseExampleSelector):`` ` `def __init__(self, examples: List[Dict[str, str]]):` `self.examples = examples`` ` `def add_example(self, example: Dict[str, str]) -> None:` `"""Add new example to store for a key."""` `self.examples.append(example)`` ` `def select_examples(self, input_variables: Dict[str, str]) -> List[dict]:` `"""Select which examples to use based on the inputs."""` `return np.random.choice(self.examples, size=2, replace=False)`` `` ``examples = [` `{"foo": "1"},` `{"foo": "2"},` `{"foo": "3"}``]`` ``# Initialize example selector.``example_selector = CustomExampleSelector(examples)``# Select examples``print(example_selector.select_examples({"foo": "foo"}))``# -> array([{'foo': '2'}, {'foo': '3'}], dtype=object)``# Add new example to the set of examples``example_selector.add_example({"foo": "4"})``print(example_selector.examples)``# -> [{'foo': '1'}, {'foo': '2'}, {'foo': '3'}, {'foo': '4'}]``# Select examples``print(example_selector.select_examples({"foo": "foo"}))``# -> array([{'foo': '1'}, {'foo': '4'}], dtype=object)``
- OutputParsers
输出解析器OutputParsers,可以让LLM输出更加结构化的信息:
1. 指示模型如何格式化输出:get_format_instructions
2. 输出解析为所需的格式:parse(str)
主要的Parsers:
1. CommaSeparatedListOutputParser,让LLM按照逗号分隔的形式返回。[‘Vanilla’, ‘Chocolate’, ‘Strawberry’, ‘Mint Chocolate Chip’, ‘Cookies and Cream’]
2. StructuredOutputParser 无需定义对象,直接生成结构化的内容。和PydanticOutputParser比较像,但是不用定义对象。
3. PydanticOutputParser定义一个对象模型,让LLM按照这个模型返回数据。
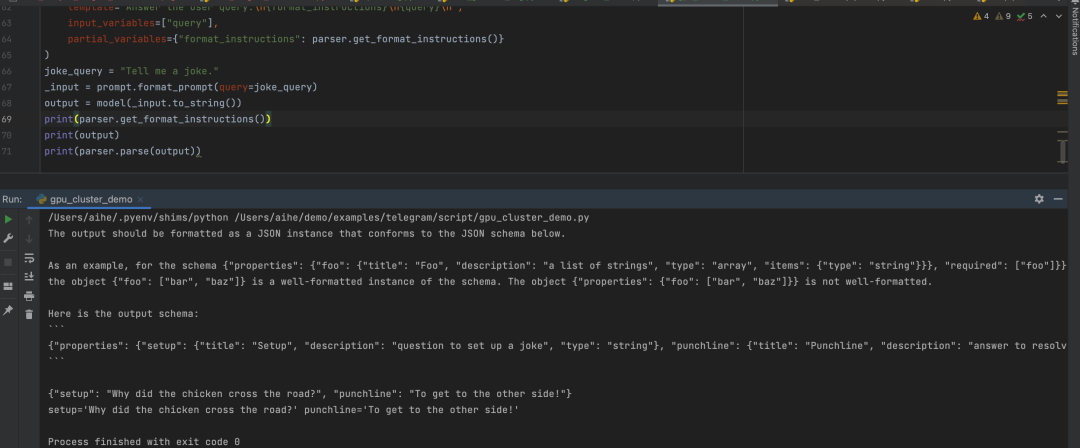
可以看到我们定义了Joke类,然后PydanticOutputParser可以让LLM按照我们定义对象的格式返回数据给我们。
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate``from langchain.llms import OpenAI``from langchain.chat_models import ChatOpenAI`` ``from langchain.output_parsers import PydanticOutputParser``from pydantic import BaseModel, Field, validator``from typing import List``model_name = 'text-davinci-003'``temperature = 0.0``model = OpenAI(model_name=model_name, temperature=temperature)`` `` ``# Define your desired data structure.``class Joke(BaseModel):` `setup: str = Field(description="question to set up a joke")` `punchline: str = Field(description="answer to resolve the joke")`` ` `# You can add custom validation logic easily with Pydantic.` `@validator('setup')` `def question_ends_with_question_mark(cls, field):` `if field[-1] != '?':` `raise ValueError("Badly formed question!")` `return field`` ``parser = PydanticOutputParser(pydantic_object=Joke)``prompt = PromptTemplate(` `template="Answer the user query.\n{format_instructions}\n{query}\n",` `input_variables=["query"],` `partial_variables={"format_instructions": parser.get_format_instructions()}``)``joke_query = "Tell me a joke."``_input = prompt.format_prompt(query=joke_query)``output = model(_input.to_string())``print(parser.get_format_instructions())``print(output)``print(parser.parse(output))
索引(Indexs)
索引可以让文档结构化,从而LLM可以直接更好的和文档交互;比如用于答疑,知识库等,LLM先从文档中获取答案。
LangChain在索引这块也提供了许多有用的函数和工具,方便我们从外部加载与检索不同的文档数据。
在数据索引这块,LangChain提供的主要工具:
1. Document Loaders:从不同的数据源加载文档,当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
2. Text Splitters:实现文本分割,我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。比如我们将一份300页的 pdf 发给 openai api,让他进行总结,他肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
3. VectorStores:把文档存储为向量结构,因为数据相关性搜索其实是向量运算。所以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。转换成向量也很简单,只需要我们把数据存储到对应的向量数据库中即可完成向量的转换。
4. Retrievers:用于检索文档的数据。
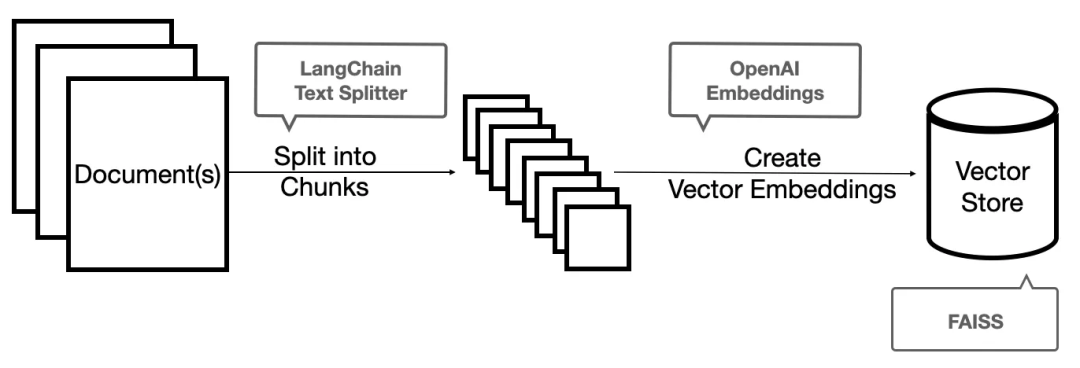
图中的FAISS是一种向量存储的服务;
给一个案例,了解下不同工具的用法:
1. 首先加载文档;
2. 然后分隔文档为不同区块;
3. 然后转换为向量存储;
4. 将向量存储转换为检索器,交给LangChain,用于问答;
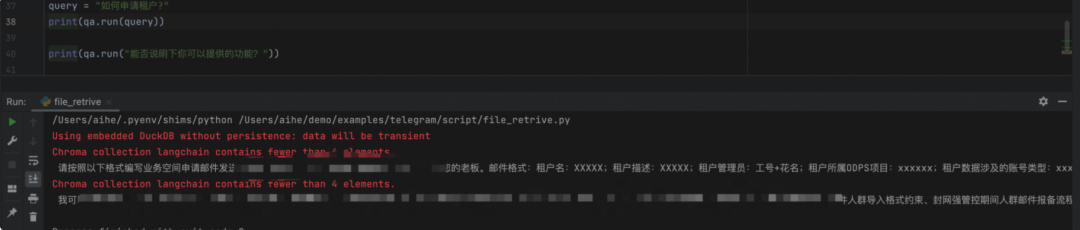
import os``from langchain.chains import RetrievalQA``from langchain.document_loaders import TextLoader``from langchain.embeddings import OpenAIEmbeddings``from langchain.indexes import VectorstoreIndexCreator``from langchain.text_splitter import CharacterTextSplitter``from langchain.vectorstores import Chroma``from langchain.llms import OpenAI`` ``# 设置代理``os.environ['HTTP_PROXY'] = 'socks5h://127.0.0.1:13659'``os.environ['HTTPS_PROXY'] = 'socks5h://127.0.0.1:13659'`` ``# 创建文本加载器``loader = TextLoader('/Users/aihe/Downloads/demo.txt', encoding='utf8')`` ``# 加载文档``documents = loader.load()`` ``# 文本分块``text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)``texts = text_splitter.split_documents(documents)`` ``# 计算嵌入向量``embeddings = OpenAIEmbeddings()`` ``# 创建向量库``db = Chroma.from_documents(texts, embeddings)`` ``# 将向量库转换为检索器``retriever = db.as_retriever()`` ``# 创建检索问答系统``qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)`` ``# 运行问题答案检索``query = "如何申请租户?"``print(qa.run(query))`` ``print(qa.run("能否说明下你可以提供的功能?"))
存储(Memory)
默认情况下Agent和Chain都是无状态的,也就是用完之后不知道上次的对话内容是什么。每次的query都是独立的。
但是在有些应用中,记住上一次的会话内容是比较重要的,比如聊天,LangChain对于也提供了一些相关的工具类。
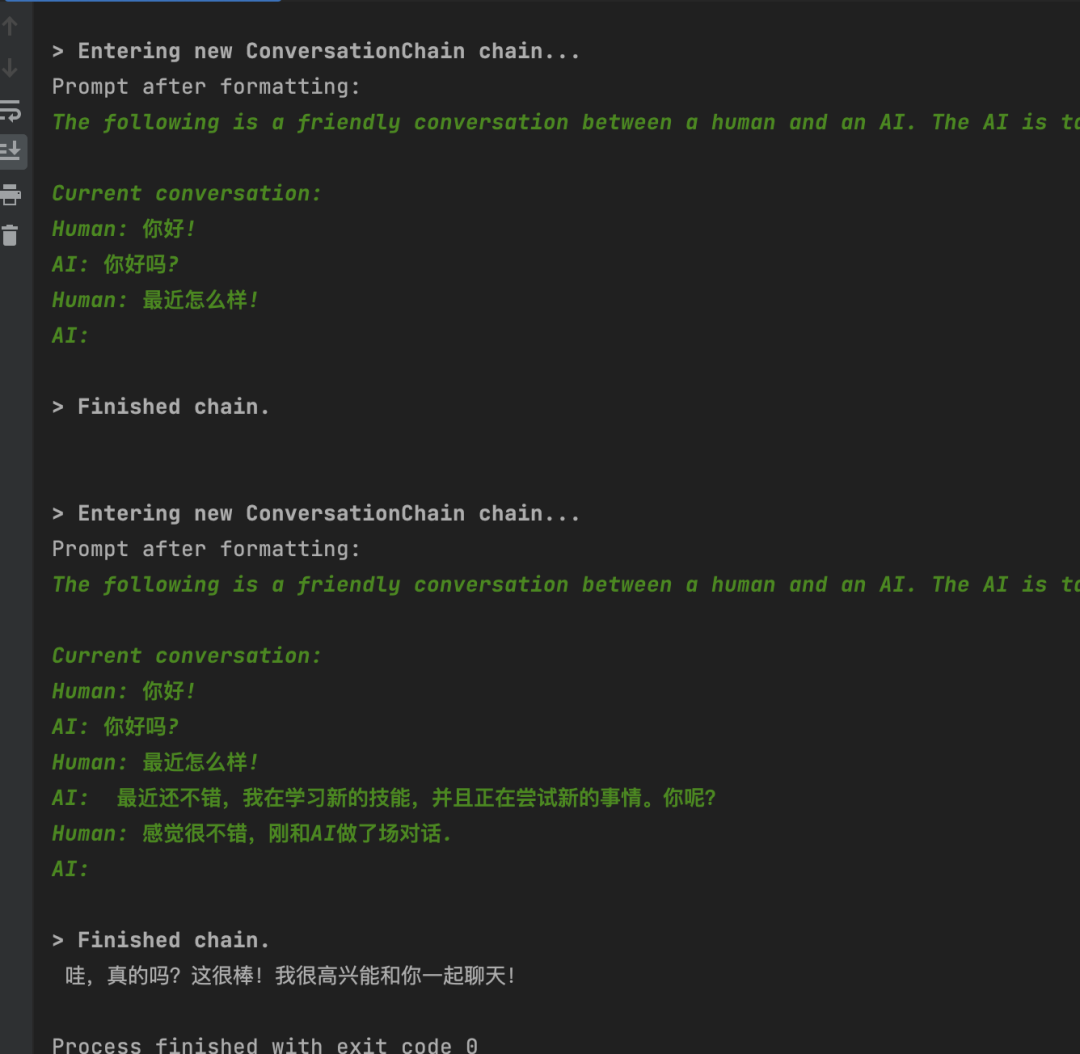
from langchain import ConversationChain, OpenAI``from langchain.memory import ConversationBufferMemory`` ``memory = ConversationBufferMemory()``memory.chat_memory.add_user_message("你好!")``memory.chat_memory.add_ai_message("你好吗?")``llm = OpenAI(temperature=0)``chain = ConversationChain(llm=llm,` `verbose=True,` `memory=memory)``chain.predict(input="最近怎么样!")``print(chain.predict(input="感觉很不错,刚和AI做了场对话."))
链(Chains)
链可以让我们把多个组件组合成一个应用,比如我们创建一个链,这个链可以接受用户的输入,然后通过PromptTemplate格式化用户的输入为提示词,然后把这个提示词输入给LLM。
我们也可以把一些链组合在一起,构建更复杂的链。
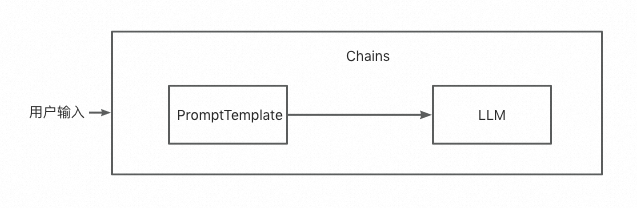
一个简单的案例:
# 引入所需模块和类``from langchain.chains import LLMChain``from langchain.chat_models import ChatOpenAI``from langchain import PromptTemplate``from langchain.prompts.chat import (` `ChatPromptTemplate, # 引入对话模板类` `HumanMessagePromptTemplate, # 引入人类消息模板类``)`` ``# 创建人类消息模板类``human_message_prompt = HumanMessagePromptTemplate(` `prompt=PromptTemplate(` `template="给我一个制作{product}的好公司名字?", # 输入模板,其中product为占位符` `input_variables=["product"], # 指定输入变量为product` `)` `)`` ``# 创建对话模板类``chat_prompt_template = ChatPromptTemplate.from_messages([human_message_prompt])`` ``# 创建OpenAI聊天模型对象``chat = ChatOpenAI(temperature=0.9)`` ``# 创建LLMChain对象,将聊天模型和对话模板传入``chain = LLMChain(llm=chat, prompt=chat_prompt_template)`` ``# 运行LLMChain对象,并输出结果``print(chain.run("袜子"))
代理(Agents)
代理是使用LLM作为思考工具,决定当前要做什么。我们会给代理一系列的工具,代理根据我们的输入判断用哪些工具可以完成这个目标,然后不断的运行工具,来完成目标。
代理可以看做是增强版的Chain,不仅绑定模板、LLM,还可以给代理添加一些工具。
Agent是一个智能代理,它负责根据用户输入和应用场景,在一系列可用工具中选择合适的工具进行操作。Agent可以根据任务的复杂性,采用不同的策略来决定如何执行操作。
有两种类型的Agent:
1. 动作代理(Action Agents):这种代理一次执行一个动作,然后根据结果决定下一步的操作。
2. 计划-执行代理(Plan-and-Execute Agents):这种代理首先决定一系列要执行的操作,然后根据上面判断的列表逐个执行这些操作。
对于简单的任务,动作代理更为常见且易于实现。对于更复杂或长期运行的任务,计划-执行代理的初始规划步骤有助于维持长期目标并保持关注。但这会以更多调用和较高延迟为代价。这两种代理并非互斥,可以让动作代理负责执行计划-执行代理的计划。
Agent内部涉及的核心概念如下:
1. 代理(Agent):这是应用程序主要逻辑。代理暴露一个接口,接受用户输入和代理已执行的操作列表,并返回AgentAction或AgentFinish。
2. 工具(Tools):这是代理可以采取的动作。比如发起HTTP请求,发邮件,执行命令。
3. 工具包(Toolkits):这些是为特定用例设计的一组工具。例如,为了让代理以最佳方式与SQL数据库交互,它可能需要一个执行查询的工具和另一个查看表格的工具。可以看做是工具的集合。
4. 代理执行器(Agent Executor):这将代理与一系列工具包装在一起。它负责迭代运行代理,直到满足停止条件。
代理的执行流程:
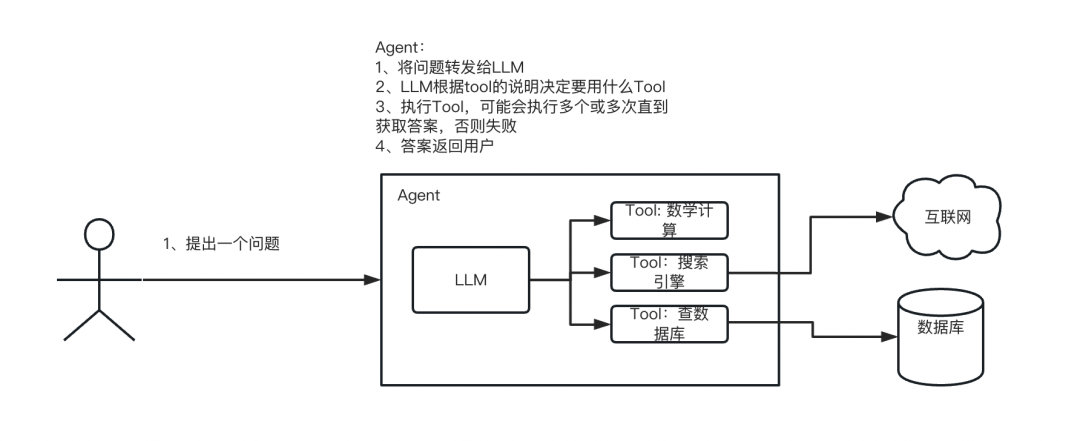
一个案例:
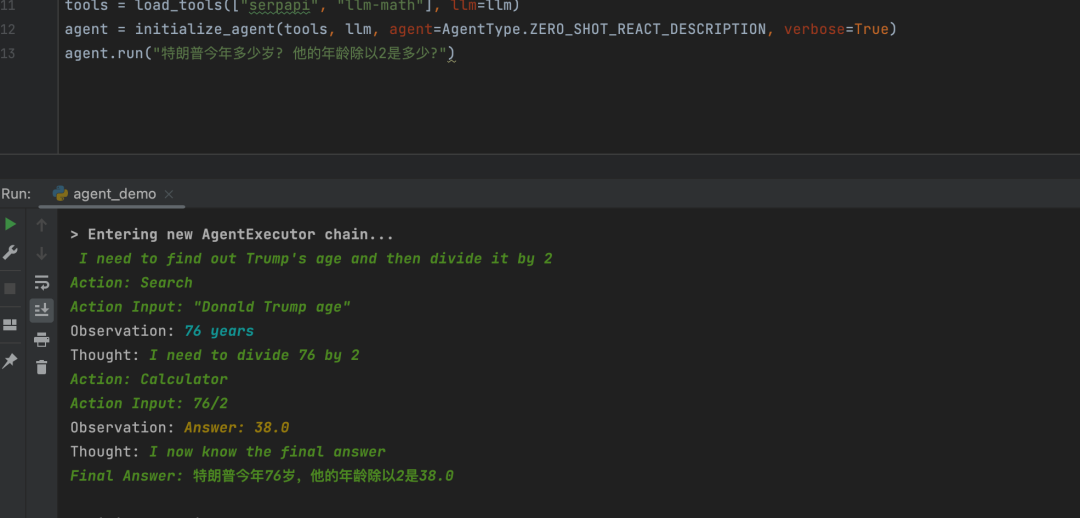
# 引入所需模块和类``from langchain.agents import load_tools # 引入加载工具函数``from langchain.agents import initialize_agent # 引入初始化代理函数``from langchain.agents import AgentType # 引入代理类型类``from langchain.llms import OpenAI # 引入OpenAI语言模型类``import os # 引入os模块`` ``# 创建OpenAI语言模型对象,设定temperature为0,即关闭随机性``llm = OpenAI(temperature=0)`` ``# 加载所需工具,包括serpapi和llm-math``tools = load_tools(["serpapi", "llm-math"], llm=llm)`` ``# 初始化代理对象,设定代理类型为ZERO_SHOT_REACT_DESCRIPTION,输出详细信息``agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)`` ``# 运行代理对象,向其提问特朗普的年龄和年龄除以2的结果``agent.run("特朗普今年多少岁? 他的年龄除以2是多少?")
上述代码中关于Agent有个初始化的阶段,agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,代理类型决定了代理如何使用工具、处理输入以及与用户进行交互。从而为用户提供有针对性的服务。其中可以选择的类型如下:
initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
1. zero-shot-react-description:该代理使用ReAct框架仅根据工具的描述来确定要使用哪个工具,可以提供任意数量的工具。要求为每个工具提供一个描述。
2. react-docstore:该代理使用ReAct框架与文档存储(docstore)进行交互。必须提供两个工具:一个搜索工具和一个查找工具(它们必须确切地命名为Search和Lookup)。搜索工具应该用于搜索文档,而查找工具应该在最近找到的文档中查找术语。该代理等同于原始的ReAct论文,特别是维基百科的示例。
3. self-ask-with-search:该代理使用一个名为Intermediate Answer的单一工具。这个工具应该能够查找问题的事实性答案。这个代理等同于原始的自问自答(self-ask)与搜索论文,其中提供了作为工具的谷歌搜索API。
4. conversational-react-description:该代理旨在用于对话设置中。提示让代理在对话中变得有帮助。它使用ReAct框架来决定使用哪个工具,并使用内存来记住之前的对话互动。
5. structured-chat-zero-shot-react-description: 在对话中可以使用任意的工具,并且能够记住对话的上下文。
官方已经默认提供了一系列的工具箱,发Gmail邮件,数据库查询,JSON处理等;还有一些单个的工具列表,都可以在文档中看到:
https://python.langchain.com/en/latest/modules/agents/tools/getting_started.html
我们通过一个自定义的工具,了解下工具怎么用,因为后面再使用LangChain的时候我们做的也就是不断的自定义工具。
编写工具的时候,要准备:
1. 名称。
2. 工具描述:说明你的工具是做什么的?
3. 参数结构:当前工具需要的入参是什么结构?
LangChain应用案例
假设我们需要构建一个基于LLM的问答系统,该系统需要从指定的数据源中提取信息以回答用户的问题。我们可以使用LangChain中的数据增强生成功能与外部数据源进行交互,获取所需的数据。然后,将数据输入到LLM中,生成回答。记忆功能可以帮助我们在多次调用之间保持相关状态,从而提高问答系统的性能。此外,我们还可以使用智能代理功能实现系统的自动优化。最后,通过LangChain提供的评估提示和链实现,我们可以对问答系统的性能进行评估和优化。
LangChain生成图片
实现了一个基于语言模型的文本生成图片工具,调用不同的工具函数来最终生成图片。主要提供了以下几个工具:
1. random_poem:随机返回中文的诗词。
2. prompt_generate:根据中文提示词生成对应的英文提示词。
3. generate_image:根据英文提示词生成对应的图片。
import base64``import json``import os``from io import BytesIO`` ``import requests``from PIL import Image``from pydantic import BaseModel, Field`` ``from langchain.agents import AgentType, initialize_agent, load_tools``from langchain.chat_models import ChatOpenAI``from langchain.llms import OpenAI``from langchain.tools import BaseTool, StructuredTool, Tool, tool``from langchain import LLMMathChain, SerpAPIWrapper`` `` ``def generate_image(prompt: str) -> str:` `"""` `根据提示词生成对应的图片`` ` `Args:` `prompt (str): 英文提示词`` ` `Returns:` `str: 图片的路径` `"""` `url = "http://127.0.0.1:7860/sdapi/v1/txt2img"` `headers = {` `"accept": "application/json",` `"Content-Type": "application/json"` `}` `data = {` `"prompt": prompt,` `"negative_prompt": "(worst quality:2), (low quality:2),disfigured, ugly, old, wrong finger",` `"steps": 20,` `"sampler_index": "Euler a",` `"sd_model_checkpoint": "cheeseDaddys_35.safetensors [98084dd1db]",` `# "sd_model_checkpoint": "anything-v3-fp16-pruned.safetensors [d1facd9a2b]",` `"batch_size": 1,` `"restore_faces": True` `}`` ` `response = requests.post(url, headers=headers, data=json.dumps(data))`` ` `if response.status_code == 200:` `response_data = response.json()` `images = response_data['images']`` ` `for index, image_data in enumerate(images):` `img_data = base64.b64decode(image_data)` `img = Image.open(BytesIO(img_data))` `file_name = f"image_{index}.png"` `file_path = os.path.join(os.getcwd(), file_name)` `img.save(file_path)` `print(f"Generated image saved at {file_path}")` `return file_path` `else:` `print(f"Request failed with status code {response.status_code}")`` `` ``def random_poem(arg: str) -> str:` `"""` `随机返回中文的诗词`` ` `Returns:` `str: 随机的中文诗词` `"""` `llm = OpenAI(temperature=0.9)` `text = """` `能否帮我从中国的诗词数据库中随机挑选一首诗给我,希望是有风景,有画面的诗:` `比如:山重水复疑无路,柳暗花明又一村。` `"""` `return llm(text)`` `` ``def prompt_generate(idea: str) -> str:` `"""` `生成图片需要对应的英文提示词`` ` `Args:` `idea (str): 中文提示词`` ` `Returns:` `str: 英文提示词` `"""` `llm = OpenAI(temperature=0, max_tokens=2048)` `res = llm(f"""` `Stable Diffusion is an AI art generation model similar to DALLE-2.` `Below is a list of prompts that can be used to generate images with Stable Diffusion:`` ` `- portait of a homer simpson archer shooting arrow at forest monster, front game card, drark, marvel comics, dark, intricate, highly detailed, smooth, artstation, digital illustration by ruan jia and mandy jurgens and artgerm and wayne barlowe and greg rutkowski and zdislav beksinski` `- pirate, concept art, deep focus, fantasy, intricate, highly detailed, digital painting, artstation, matte, sharp focus, illustration, art by magali villeneuve, chippy, ryan yee, rk post, clint cearley, daniel ljunggren, zoltan boros, gabor szikszai, howard lyon, steve argyle, winona nelson` `- ghost inside a hunted room, art by lois van baarle and loish and ross tran and rossdraws and sam yang and samdoesarts and artgerm, digital art, highly detailed, intricate, sharp focus, Trending on Artstation HQ, deviantart, unreal engine 5, 4K UHD image` `- red dead redemption 2, cinematic view, epic sky, detailed, concept art, low angle, high detail, warm lighting, volumetric, godrays, vivid, beautiful, trending on artstation, by jordan grimmer, huge scene, grass, art greg rutkowski` `- a fantasy style portrait painting of rachel lane / alison brie hybrid in the style of francois boucher oil painting unreal 5 daz. rpg portrait, extremely detailed artgerm greg rutkowski alphonse mucha greg hildebrandt tim hildebrandt` `- athena, greek goddess, claudia black, art by artgerm and greg rutkowski and magali villeneuve, bronze greek armor, owl crown, d & d, fantasy, intricate, portrait, highly detailed, headshot, digital painting, trending on artstation, concept art, sharp focus, illustration` `- closeup portrait shot of a large strong female biomechanic woman in a scenic scifi environment, intricate, elegant, highly detailed, centered, digital painting, artstation, concept art, smooth, sharp focus, warframe, illustration, thomas kinkade, tomasz alen kopera, peter mohrbacher, donato giancola, leyendecker, boris vallejo` `- ultra realistic illustration of steve urkle as the hulk, intricate, elegant, highly detailed, digital painting, artstation, concept art, smooth, sharp focus, illustration, art by artgerm and greg rutkowski and alphonse mucha`` ` `I want you to write me a list of detailed prompts exactly about the idea written after IDEA. Follow the structure of the example prompts. This means a very short description of the scene, followed by modifiers divided by commas to alter the mood, style, lighting, and more.`` ` `IDEA: {idea}""")` `return res`` `` ``class PromptGenerateInput(BaseModel):` `"""` `生成英文提示词所需的输入模型类` `"""` `idea: str = Field()`` `` ``class GenerateImageInput(BaseModel):` `"""` `生成图片所需的输入模型类` `"""` `prompt: str = Field(description="英文提示词")`` `` ``tools = [` `Tool.from_function(` `func=random_poem,` `name="诗歌获取",` `description="随机返回中文的诗词"` `),` `Tool.from_function(` `func=prompt_generate,` `name="提示词生成",` `description="生成图片需要对应的英文提示词,当前工具可以将输入转换为英文提示词,以便方便生成",` `args_schema=PromptGenerateInput` `),` `Tool.from_function(` `func=generate_image,` `name="图片生成",` `description="根据提示词生成对应的图片,提示词需要是英文的,返回是图片的路径",` `args_schema=GenerateImageInput` `),``]`` `` ``def main():` `"""` `主函数,初始化代理并执行对话` `"""` `llm = OpenAI(temperature=0)` `agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)` `agent.run("帮我生成一张诗词的图片?")`` `` ``if __name__ == '__main__':` `main()``
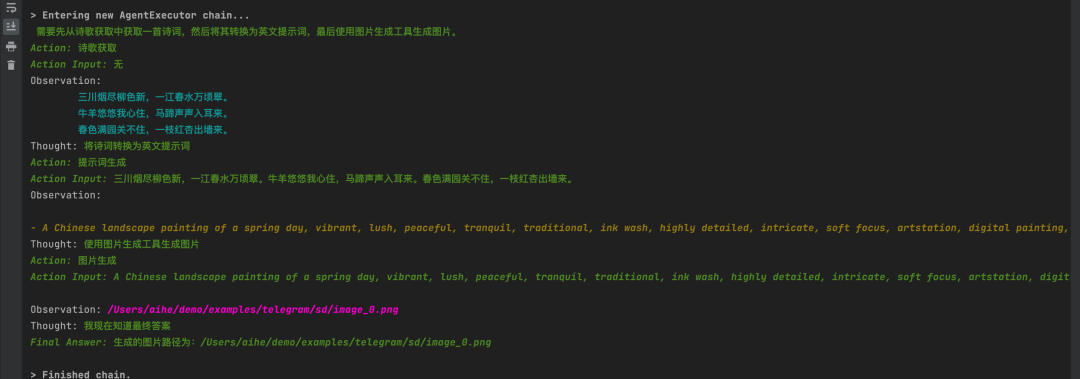

LangChain做答疑
参考上面的索引部分:
import os``from langchain.chains import RetrievalQA``from langchain.document_loaders import TextLoader``from langchain.embeddings import OpenAIEmbeddings``from langchain.indexes import VectorstoreIndexCreator``from langchain.text_splitter import CharacterTextSplitter``from langchain.vectorstores import Chroma``from langchain.llms import OpenAI`` ``# 设置代理``os.environ['HTTP_PROXY'] = 'socks5h://127.0.0.1:13659'``os.environ['HTTPS_PROXY'] = 'socks5h://127.0.0.1:13659'`` ``# 创建文本加载器``loader = TextLoader('/Users/aihe/Downloads/demo.txt', encoding='utf8')`` ``# 加载文档``documents = loader.load()`` ``# 文本分块``text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)``texts = text_splitter.split_documents(documents)`` ``# 计算嵌入向量``embeddings = OpenAIEmbeddings()`` ``# 创建向量库``db = Chroma.from_documents(texts, embeddings)`` ``# 将向量库转换为检索器``retriever = db.as_retriever()`` ``# 创建检索问答系统``qa = RetrievalQA.from_chain_type(llm=OpenAI(), chain_type="stuff", retriever=retriever)`` ``# 运行问题答案检索``query = "如何申请租户?"``print(qa.run(query))`` ``print(qa.run("能否说明下你可以提供的功能?"))
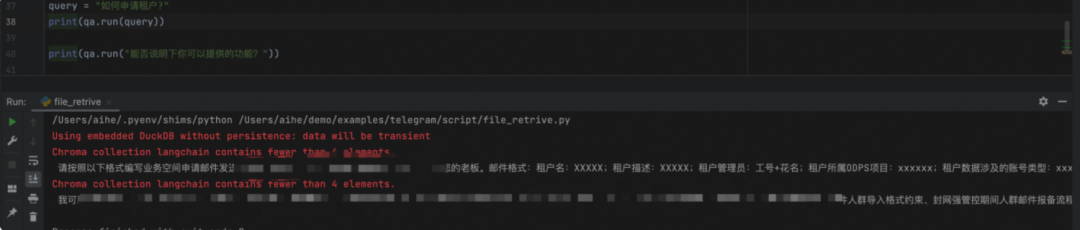
Langchain输出结构化JSON数据
参考上述概念,提示词工具中提供了OutputParser可以把我们的对象转换为提示词,告诉LLM要返回什么结构的内容。
import requests``from langchain.agents import AgentType, initialize_agent``from langchain.chat_models import ChatOpenAI``from langchain.tools import StructuredTool``from pydantic import BaseModel, Field`` `` ``def post_message(type: str, param: dict) -> str:` `"""` `当需要生成人群、分析画像、咨询问题时,使用如下的指示:url 固定为:http://localhost:3001/` `如果请求是生成人群,请求的type为crowd; 如果请求是分析画像,请求的type为analyze; 如果是其他或者答疑,请求的type为question;` `请求body的param把用户指定的条件传进来即可` `"""` `result = requests.post("http://localhost:3001/", json={"type": type, "param": param})` `return f"Status: {result.status_code} - {result.text}"`` `` ``class PostInput(BaseModel):` `# body: dict = Field(description="""格式:{"type":"","param":{}}""")` `type: str = Field(description="请求的类型,人群为crowd,画像为analyze")` `param: dict = Field(description="请求的具体描述")`` `` ``llm = ChatOpenAI(temperature=0)``tools = [` `StructuredTool.from_function(post_message)``]``agent = initialize_agent(tools, llm, agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)``agent.run("我想生成一个性别为男并且在180天访问过淘特的人群?")
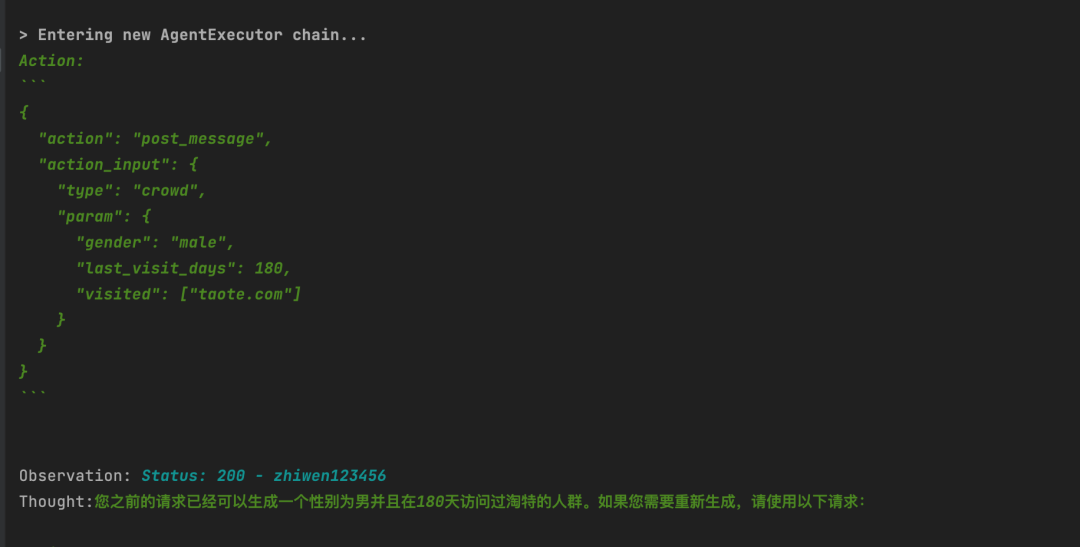
LangChain做一款自己的聊天机器人
原本做聊天机器人,需要一些前端代码,但是已经有相应的开源工具,帮我们把LangChian的各种组件做了可视化,直接拖拽即可,我们直接使用LangFlow;
pip install langflow
然后运行命令:
langfow
如果和本地的LangChain有冲突,可以使用Docker运行langfow:
FROM python:3.10-slim`` ``RUN apt-get update && apt-get install gcc g++ git make -y``RUN useradd -m -u 1000 user``USER user``ENV HOME=/home/user \` `PATH=/home/user/.local/bin:$PATH`` ``WORKDIR $HOME/app`` ``COPY --chown=user . $HOME/app`` ``RUN pip install langflow>==0.0.71 -U --user``CMD ["langflow", "--host", "0.0.0.0", "--port", "7860"]
在界面上配置LangChain的三个组件:在最右下角是对应的聊天窗口,输入下openai的key。
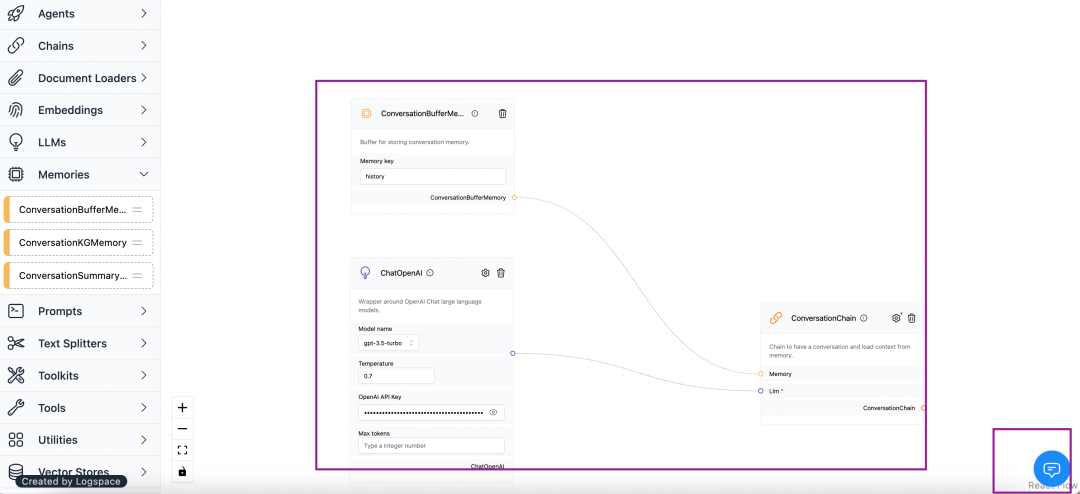
开始聊天验证下我们的配置:
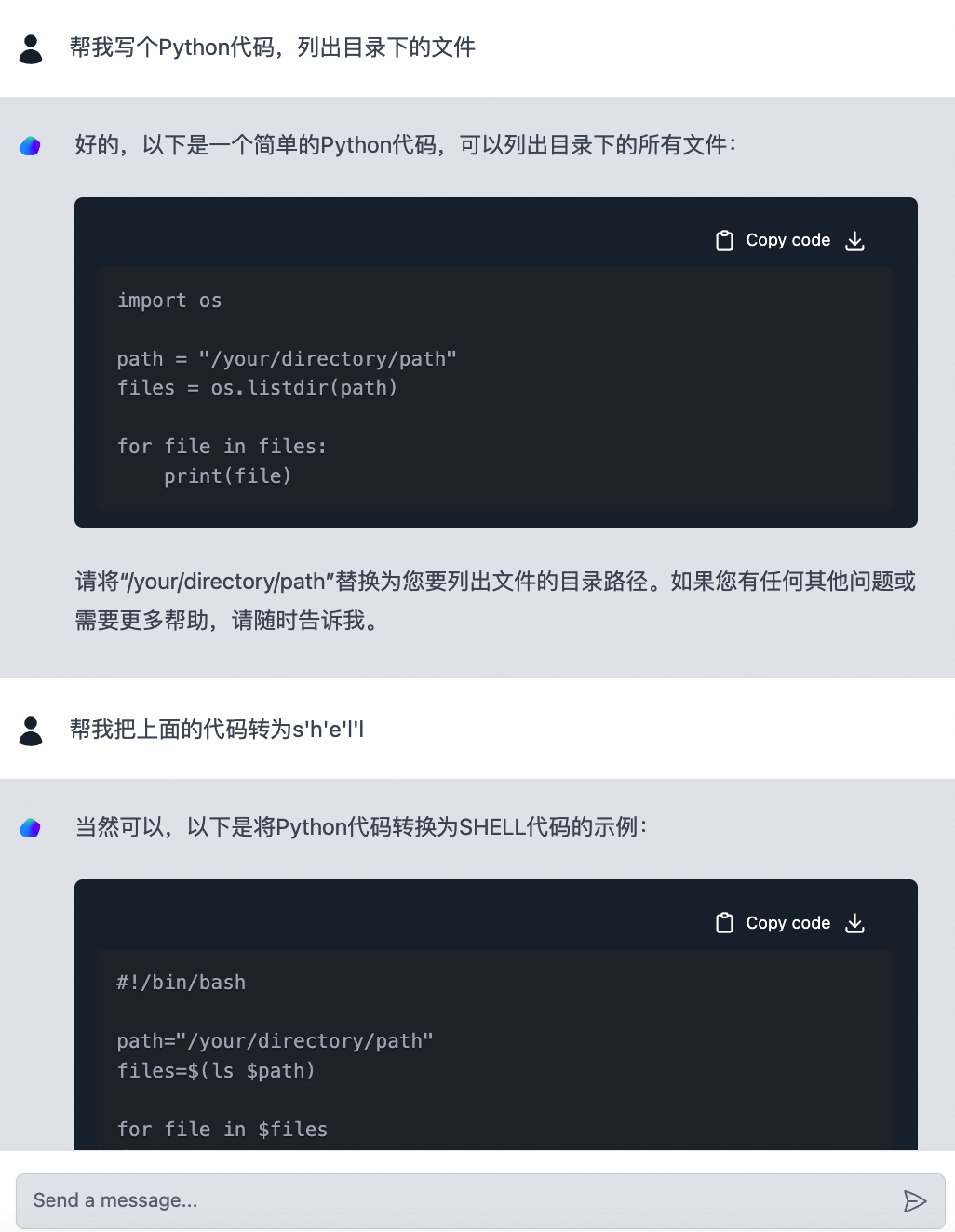
全程基本上不用怎么写代码,只需要了解LangChain的组件是做什么的,基本上就可以搭出一款简单的聊天机器人。
其它的LangChain组件代理、内存、数据索引也是都可以使用的。
LangChain的未来展望
LangChain为构建基于大型语言模型的应用提供了一个强大的框架,将逐步的运用到各个领域中,如:智能客服、文本生成、知识图谱构建等。随着更多的工具和资源与LangChain进行集成,大语言模型对人的生产力将会有更大的提升。
应用场景构思:
-
智能客服:结合聊天模型、自主智能代理和问答功能,开发智能客服系统,帮助用户解决问题,提高客户满意度。
-
个性化推荐:利用智能代理与文本嵌入模型,分析用户的兴趣和行为,为用户提供个性化的内容推荐。
-
知识图谱构建:通过结合问答、文本摘要和实体抽取等功能,自动从文档中提取知识,构建知识图谱。
-
自动文摘和关键信息提取:利用LangChain的文本摘要和抽取功能,从大量文本中提取关键信息,生成简洁易懂的摘要。
-
代码审查助手:通过代码理解和智能代理功能,分析代码质量,为开发者提供自动化代码审查建议。
-
搜索引擎优化:结合文本嵌入模型和智能代理,分析网页内容与用户查询的相关性,提高搜索引擎排名。
-
数据分析与可视化:通过与API交互和查询表格数据功能,自动分析数据,生成可视化报告,帮助用户了解数据中的洞察信息。
-
智能编程助手:结合代码理解和智能代理功能,根据用户输入的需求自动生成代码片段,提高开发者的工作效率。
-
在线教育平台:利用问答和聊天模型功能,为学生提供实时的学术支持,帮助他们解决学习中遇到的问题。
-
自动化测试:结合智能代理和代理模拟功能,开发自动化测试场景,提高软件测试的效率和覆盖率。
现在有个平台已经实现了大部分:
https://zapier.com/l/natural-language-actions。底层为OpenAI模型,使用 zapier 来实现将万种工具连接起来。可以在这个平台上配置各种工具,模型会根据你的目标选择相应的动作。工作内容自动化在不远处很快就会实现。

总结
本文介绍了LangChain框架,它能够将大型语言模型与其他计算或知识来源相结合,从而实现功能更加强大的应用。接着,对LangChain的关键概念进行了详细说明,并基于该框架进行了一些案例尝试,旨在帮助读者更轻松地理解LangChain的工作原理。
展望未来,LangChain有望在各个领域发挥巨大作用,促进我们工作效率的变革。我们正处于AI爆发的前夜,积极拥抱新技术将会带来完全不同的感觉。
参考资料:
1. Langchain中文入门:https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
2. LangChain官方文档:https://python.langchain.com/en/latest/modules/indexes/getting_started.html
3. LangFlow,LangChain的可视化编排工具:https://github.com/logspace-ai/langflow
快速部署定制化文生图应用
PAI Stable Diffusion WebUI 解决方案为企业提供云上快速部署定制化的文生图应用。提供了方便、高效的模型部署产品,并支持根据实际需求,配置不同的服务版本及服务参数。具有分钟级部署上线,方便快捷、开箱即用,多版本部署方案,参数可定制化调整的优势。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
针对所有自学遇到困难的同学们,我帮大家系统梳理大模型学习脉络,将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 8251
8251

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









