







Multi-Head Latent Attention(多头潜在注意力,MLA)是一种改进的注意力机制,结合了传统多头注意力(Multi-Head Attention)和潜在空间建模(Latent Space Modeling)的优势,旨在提升模型对长序列、复杂语义关系的建模能力,同时优化计算效率。以下是其核心原理、技术实现及应用的详细解析:
核心思想
MLA 的核心是通过引入潜在空间(Latent Space),将高维注意力计算映射到低维空间,从而减少计算复杂度,同时保留关键语义信息。其设计目标包括:
**降低计算成本**:避免传统注意力机制的 (O(n^2)) 复杂度。
**增强语义抽象**:在潜在空间中捕捉更高阶的依赖关系。
**保持多粒度建模**:通过多头机制并行处理不同子空间的语义特征。
时间线:
|
模型 |
创新点/亮点 |
时间 |
|
DeepSeekMath |
GRPO |
2024.04 |
|
DeepSeek-V2 |
DeepSeekMoE、 Multi-Head Latent Attention(MLA) |
2024.06 |
|
DeepSeek-V3 |
迭代DeepSeekMoE、 MTP、混合精度训练infra:花费下降 |
2024.12 |
|
DeepSeek-R1 |
直接应⽤GRPO:效果提升 |
2025.01 |
DeepSeek⽕爆出圈,有很多延伸的讨论和评价。作为算法同学,我们还是要回归到最本质的技术上来。我们逐个的来看看⼀下他们的论⽂和技术创新,起码要先知道⼈家是怎么做的。
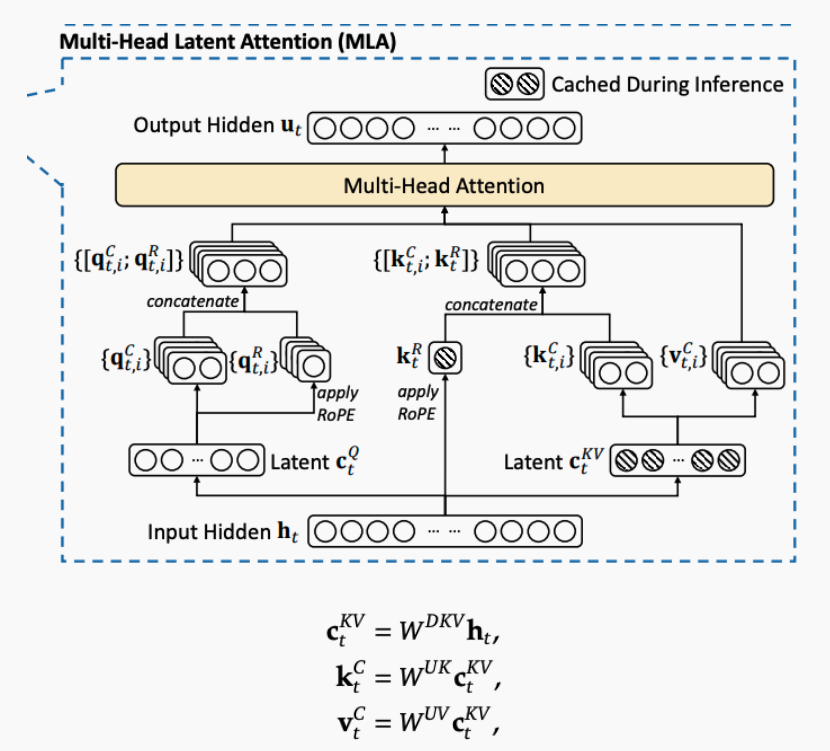
MLA:Multi-head Latent Attention
MLA guarantees efficient inference through significantly compressing the Key-Value (KV) cache into a latent vector
KVCache是常⽤的技术,为了降低KVCache的存储量,GQA和MQA被提出来简化KV值,但是这些技术都会折损效果。MLA采⽤低秩压缩算法,压缩KV的维度,相⽐于MHA,MLA效果⼜好,推理效率⼜⾼。
标准MHA算法从另外⼀个⻆度复习⼀下多头注意⼒机制算法(对算法清楚了,只看公式就知道是怎么回事了)• d 表⽰输⼊维度• nh 表⽰头的数量• dh 表⽰每个头的维度• ht 表⽰输⼊的第t个向量
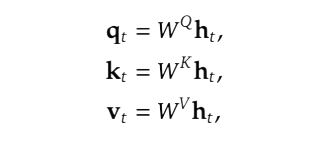

MLA的核⼼是对KV做了低秩压缩,在送⼊标准MHA算法之前,⽤更短的⼀个向量来表⽰原来⻓的向量,从⽽⼤幅减少KVcache空间。



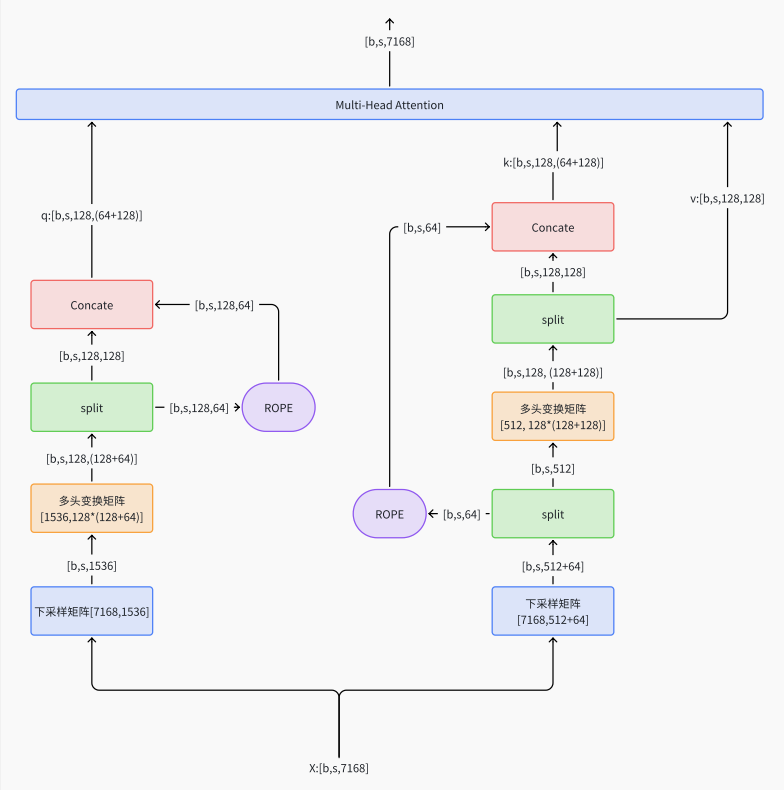
伪代码:
https://github.com/deepseek-ai/DeepSeek-V3/blob/main/inference/model.py
class MLA(nn.Module):
def __init__(self):
self.dim = 7168
self.n_heads = 128
self.q_lora_rank = 1536 # q压缩后维度
self.kv_lora_rank = 512 # KV压缩后维度
self.qk_nope_head_dim = 128
self.qk_rope_head_dim = 64
self.qk_head_dim = self.qk_nope_head_dim + self.qk_rope_head_dim =128+64
self.v_head_dim = 128
self.wq_a = Linear([7168, 1536]) # 下采样矩阵,得到压缩后的q向量
self.wq_b = Linear([1536, 128*(128+64)]) # 变换成多头注意⼒和⽤来旋转位置编码的向量
self.wkv_a = Linear([7168, 64+512]) # 下采样矩阵,得到压缩后的kv向量
self.wkv_b = Linear([512, 128*(128+128)]) # 变换多头注意⼒和⽤来旋转位置编码的向量
self.wo = Linear([128*128, 7168]) # 最后进⾏的投影层
def forward(self, x):
q = self.wq_b(self.wq_a(x))
q = q.view(bsz, seqlen, 128, 128+64)
q_nope, q_pe = torch.split(q, [128, 64], dim=-1)
q_pe = apply_rotary_emb(q_pe)
kv = self.wkv_a(x) # [b, s, 512+64]
kv, k_pe = torch.split(kv, [512, 64], dim=-1)
k_pe = apply_rotary_emb(k_pe.unsqueeze(2))
q = torch.cat([q_nope, q_pe], dim=-1)
kv = self.wkv_b(kv)
kv = kv.view(bsz,seqlen, 128, 128+128)
k_nope, v = torch.split(kv, [128, 128], dim=-1)
k = torch.cat([k_nope, k_pe], dim=-1)
self.k_cache[:bsz,...] = k
self.v_cache[:bsz,...] = v
scores = torch.einsum("bshd,bthd->bsht", q, self.k_cache[:bsz,:end_pos])
x = torch.einsum("bsht,bthd->bshd", scores, self.v_cache[:bsz,:end_pos])
x = self.wo(x.flatten(2))
return x




















 4284
4284

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











