






注意事项
- 根据以下链接进行配置,具体的使用情况可以看我的分享【免费开源的LaTex OCR软件分享(latex-ocr和texify使用分享)】
LaTeX-OCR: https://github.com/lukas-blecher/LaTeX-OCR
texify: https://github.com/VikParuchuri/texify
- 配置环境可能存在某些库版本太新,导致安装出现异常;
- 下面剪贴板的路径修改为自己存在的路径;
- 使用F5刷新界面来获取新的识别内容;
texify调用
# 调用命令
streamlit run .\texify_app.py
import os
from PIL import Image, ImageGrab
import streamlit as st
from texify.inference import batch_inference
from texify.model.model import load_model
from texify.model.processor import load_processor
# how to use
# streamlit run .\texify_app.py
# 注释掉的部分可以调用文件上传,但感觉对我不是很实用
# if __name__ == '__main__':
# streamlit.set_page_config(page_title='Texify OCR')
# streamlit.title('Texify OCR')
# streamlit.markdown(
# 'Convert images of equations to corresponding LaTeX code.\n\nThis is based on the `texify` module.')
# uploaded_file = streamlit.file_uploader(
# 'Upload an image an equation',
# type=['png', 'jpg'],
# )
# if uploaded_file is not None:
# image = Image.open(uploaded_file)
# streamlit.image(image)
# else:
# streamlit.text('\n')
# if streamlit.button('Convert'):
# if uploaded_file is not None and image is not None:
# with streamlit.spinner('Computing'):
# try:
# latex_code = batch_inference([image], model, processor)
# streamlit.code(latex_code, language='latex')
# streamlit.markdown(f'$\\displaystyle {latex_code}$')
# except Exception as e:
# streamlit.error(e)
# else:
# streamlit.error('Please upload an image.')
if __name__ == '__main__':
st.set_page_config(page_title='LaTeX-OCR')
st.title('LaTeX OCR')
st.markdown('Convert images of equations to corresponding LaTeX code.')
image_container = st.empty()
im = ImageGrab.grabclipboard()
import time
time.sleep(0.1)
flie_path = "D:\\Miniconda\\envs\\texocr\\doc\\clipboard\\grab_clipboard.jpg"
if isinstance(im, Image.Image):
print("Image: size : %s, mode: %s" % (im.size, im.mode))
image_container.image(im)
im.save(flie_path)
else:
print("clipboard is empty")
if os.path.exists(flie_path):
if st.button('Convert'):
with st.spinner('Computing'):
try:
model = load_model()
processor = load_processor()
image = Image.open(flie_path)
latex_code = batch_inference([image], model, processor)
# print(latex_code)
st.code(latex_code[0], language='latex')
st.markdown(latex_code[0])
except Exception as e:
st.error('Failed Convert!')
else:
st.info('Please copy an image to your clipboard first, then click "Use Clipboard"')
latex ocr调用
# 运行命令
streamlit run .\ocrtex_app.py
import os
from PIL import Image, ImageGrab
import streamlit as st
from pix2tex.cli import LatexOCR
from munch import Munch
args = Munch({'config': 'settings/config.yaml',
'checkpoint': 'checkpoints/weights.pth',
'no_resize': False})
if __name__ == '__main__':
st.set_page_config(page_title='LaTeX-OCR')
st.title('LaTeX OCR')
st.markdown('Convert images of equations to corresponding LaTeX code.')
image_container = st.empty()
im = ImageGrab.grabclipboard()
import time
time.sleep(0.1)
flie_path = "D:\\Miniconda\\envs\\texocr\\doc\\clipboard\\grab_clipboard.jpg"
if isinstance(im, Image.Image):
print("Image: size : %s, mode: %s" % (im.size, im.mode))
image_container.image(im)
im.save(flie_path)
else:
print("clipboard is empty")
if os.path.exists(flie_path):
if st.button('Convert'):
with st.spinner('Computing'):
try:
model = LatexOCR(args)
image = Image.open(flie_path)
latex_code = model(image)
print(latex_code)
cp_content = '$$ ' + latex_code + ' $$'
st.code(cp_content, language='latex')
st.markdown(f'$\\displaystyle {latex_code}$')
except Exception as e:
st.error('Failed Convert!')
else:
st.info('Please copy an image to your clipboard first, then click "Use Clipboard"')
文本OCR
图片示例如下,背景简单没问题,稍微复杂的背景可能不太行,一般是建议使用微信,几乎大家都有,使用简单。
https://github.com/deanmalmgren/textract
按照上述同样#1#2的原理可以很容易实现下面效果:
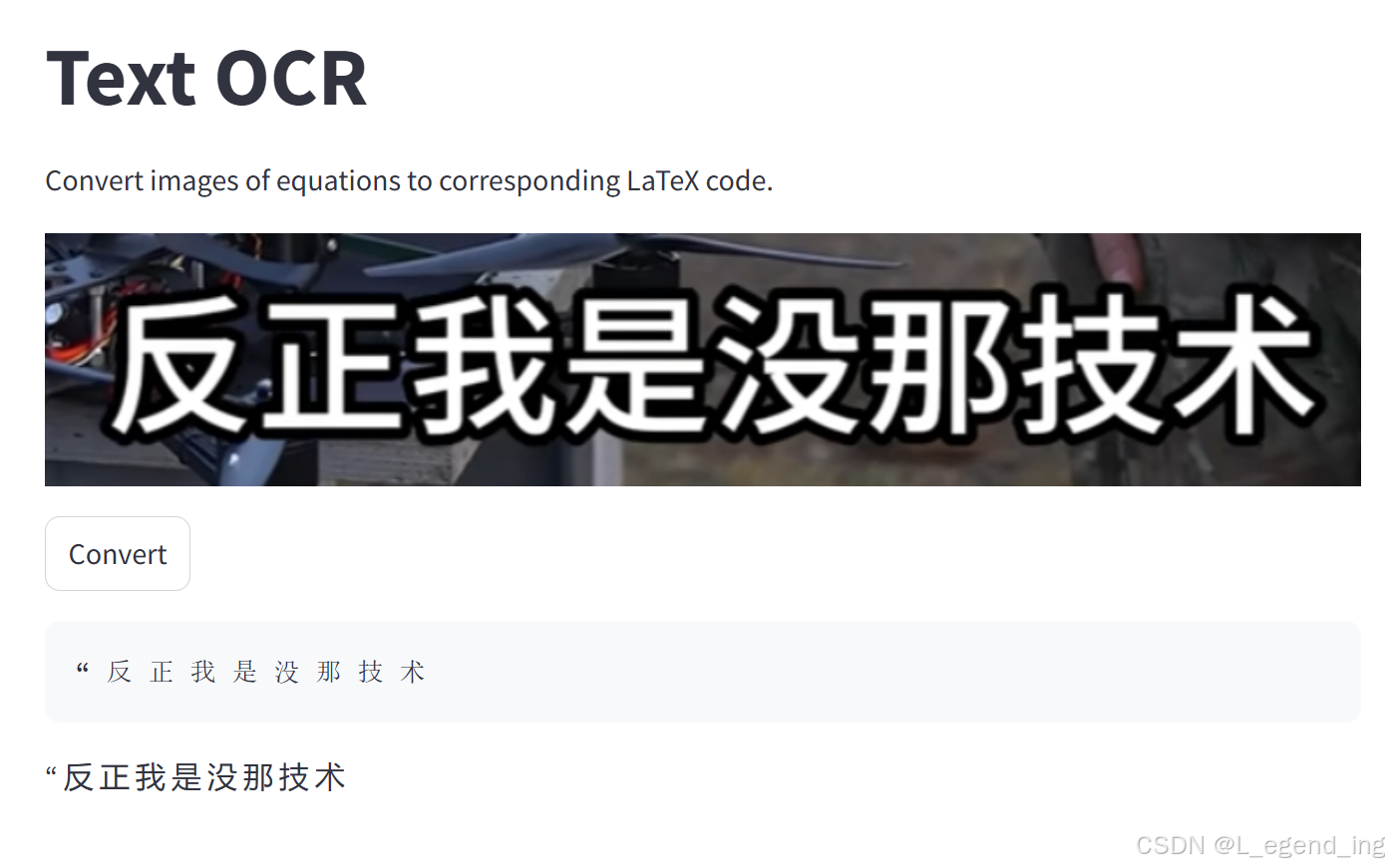
注意:需要单独下载支持中文的语言包,还要安装支持的库,这个已经被作者封装好exe,直接安装就行。
import os
import textract
from PIL import Image, ImageGrab
import streamlit as st
if __name__ == '__main__':
st.set_page_config(page_title='Text-OCR')
st.title('Text OCR')
st.markdown('Convert images of equations to corresponding LaTeX code.')
image_container = st.empty()
im = ImageGrab.grabclipboard()
import time
time.sleep(0.1)
flie_path = "D:\\Miniconda\\envs\\texocr\\doc\\clipboard\\grab_clipboard.jpg"
if isinstance(im, Image.Image):
print("Image: size : %s, mode: %s" % (im.size, im.mode))
image_container.image(im)
im.save(flie_path)
else:
print("clipboard is empty")
if os.path.exists(flie_path):
if st.button('Convert'):
with st.spinner('Computing'):
try:
full_text = textract.process(
flie_path,
method='tesseract',
language='chi_sim',
).decode('utf-8')
# print(full_text)
st.code(full_text, language='txt')
st.markdown(full_text)
except Exception as e:
st.error('Failed Convert!')
else:
st.info('Please copy an image to your clipboard first, then click "Use Clipboard"')

















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









