







1.在官网选择合适的网络模型(登Hugging Face官网需要梯子!)
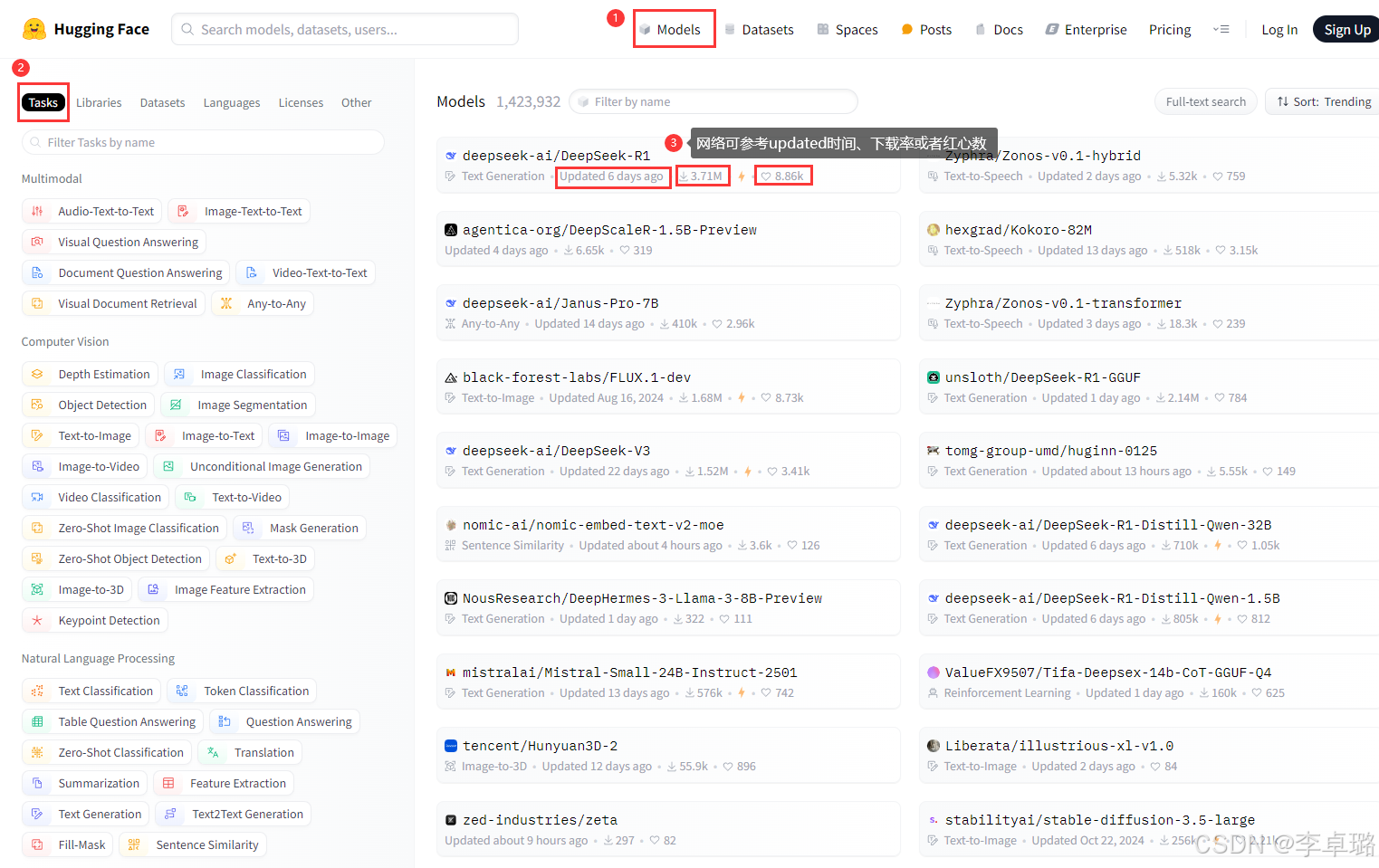
2.导包
from transformers import AutoTokenizer #会根据模型自动判断选用哪种分词器进行分词操作
联外网运行
获取checkpoint

from transformers import AutoTokenizer
checkpoint = "timpal0l/mdeberta-v3-base-squad2"
tokenizer = AutoTokenizer.from_pretrained(checkpoint)#从模型中自动获取tokenizer
在执行完会在默认将模型保存在本地,如下图所展示

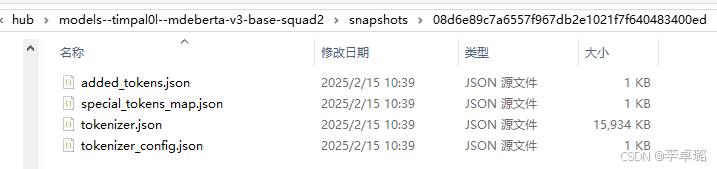
此时我们后续可以直接使用本地模型离线运行(不用挂梯子)
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("timpal0l/mdeberta-v3-base-squad2")
tokenizer.save_pretrained("./medical_QA_model")
tokenizer = AutoTokenizer.from_pretrained("./medical_QA_model/")
这样就将下图的文件保存至所想要保存的文件夹中,后续可以实现模型本地加载,离线运行,不用挂梯子了。
那上述的两种代码中都是使用了自动分词器选择,它是由checkpoint指定的预训练模型关联的,不用我们自己选择tokenizer,它自动帮我们选择好了。
tokenizer(raws_inputs,padding=True,truncation=True,return_tensors=“pt”)*中padding代表是否需要自动补零;truncation代表是否需要隔断,默认是true,指不超过计算机的上限512,它也可以被你指定你设定的文本长度然后进行隔断;return_tensors="pt"指的是使用pytorch.
输出结果:

模型的输入经过tokenizer得到两部分: 1)input_id:它由id、[CLS][SEP]两个特殊字符、补零占位符组成;2)attention_mask:为1的表示可以跟谁算,为0的不会参与到self-attention的进一步计算。
注意: attention_mask和padding是配套使用的,当人为去修改padding的时候,也要把attention_mask里面的参数进行修改。不修改的话计算机会认为人为padding的0占位符是有效位将会参与self-attention计算,那么这时候输出结果会有区别。
注意: 在加载清华gpt模型的tokenizer时候,需要添加trust_remote_code=True,因为清华的tokenizer是额外写在一个py文件中的,如果不指定相信远程调用的话可能会报错,完整代码为:tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b",trust_remote_code=True)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









