




 本文提出AdaDiff,一种根据输入样本复杂度动态选择去噪步骤的框架,通过策略梯度优化降低图像和视频生成的推理时间,保持高质量。实验显示,相比于固定步骤,AdaDiff在保持生成效果的同时显著减少了计算成本。
本文提出AdaDiff,一种根据输入样本复杂度动态选择去噪步骤的框架,通过策略梯度优化降低图像和视频生成的推理时间,保持高质量。实验显示,相比于固定步骤,AdaDiff在保持生成效果的同时显著减少了计算成本。
AdaDiff: Adaptive Step Selection for Fast Diffusion
这本质是一篇加速生成的文章,优化角度在于为不同复杂程度的提示选取不同的时间步去进行去噪。
Abstract
扩散模型的生成过程涉及到几十个步骤的去噪以产生逼真的图像/视频,这在计算上是昂贵的。本文认为去噪步骤 应该根据输入样本的复杂程度来进行特定的采样。
因此提出了 AdaDiff ,一个轻量级的框架来学习 instance-specific 的步骤策略。还是和之前方法一样,使用策略梯度方法来最大化一个奖励函数。(平衡推理时间和生成质量)
作者在 3 个图像生成基准测试和 2 两个视频生成基准测试进行了实验,结果表明:可以实现和固定 50 个去噪步骤的模型实现相当的结果,但是本文提出的方法减少了 33%−40%33\% - 40\%33%−40% 的推理时间
Introduction

目前考虑到生成质量和推理速度之间的权衡,大多数去噪步骤都是设置为 50。
而作者认为:
- 文本提示的丰富性(即对象的数量以及它们彼此之间的关系)差异很大。
- 对于某些简单且粗粒度的提示(仅涉及一个或几个对象),使用少步骤足以达到好的生成质量,而增加步骤只会有边际改善而不会有必然的生成改善。
- 对于包含许多对象、详细描述和对象之间复杂交互的复杂文本提示,需要更多的步骤来实现期望的结果。
因此,本文的目标是为扩散模式建立一个动态框架;
简而言之,AdaDiff 为不同丰富程度的提示分配了不同数量的生成步骤,旨在最大限度地减少推理时间,同时保持高图像质量。带有红色边框的图像是由AdaDiff生成的。
对于每个提示符的的动态生成策略:
1)决定所需要的生成步骤数目;
2)使用相对更少的步骤来确保高质量的生成;
这样的问题是:学习动态步骤选择是一项非常难的任务,因为它涉及不可微分的决策过程。
为此,AdaDiff训练一个轻量级的步长选择网络来生成步长使用策略。随后,基于此导出的策略,对预训练的扩散模型进行动态采样过程,以实现高效生成。
- 步骤选择网络使用策略梯度方法进行优化,以最大化奖励函数。
- 这个奖励函数的主要目标是鼓励生成高质量的视觉内容,同时最小化计算资源。
- 同样值得指出的是,以文本输入为条件的步长选择网络是轻量级的,计算开销可以忽略不计。
Methods
这里主要关注的是 3.2 节:Adaptive step selection for image generation
Adaptive step selection for image generation
文中使用离散时间的 DDIM sample 来加速采样,设定 N=5,S={10,20,30,40,50}N = 5, S = \{10, 20, 30, 40, 50\}N=5,S={10,20,30,40,50} ;
形式上;
1)给定文本提示 p\mathbf{p}p ,经过 文本编码器 τ\boldsymbol{\tau}τ 提取特征 c=τ(p)\mathbf{c}=\boldsymbol{\tau}(\mathbf{p})c=τ(p)
2)步长选择网络 fsf_{s}fs,参数化为 www,通过 self-attention 来学习文本提示 c\mathbf{c}c 信息量;
3)然后通过一个 MLP 投射为 s∈RNs\in \mathcal{\mathbb{R}}^{N}s∈RN
s=fs(c;w) \mathbf{s}=f_s(\mathbf{c};\mathbf{w}) s=fs(c;w)
其中,s\mathbf{s}s 中的每一项表示选择该步骤的概率得分。然后定义了一个N维类别分布的步长选择策略 πf(u∣p)\pi^f\left(\mathbf{u}\mid\mathbf{p}\right)πf(u∣p)。
其中,u\mathbf{u}u 是一个长度为 N 的 one-hot 向量,而 uj=1\mathbf{u}_j = 1uj=1 表示 S\mathcal{S}S 中选择下标为 jjj 的时间步骤 t\mathbf{t}t 的概率。
步长选择网络设计为由三个自关注层和一个多层感知器组成的轻量级结构。
在训练阶段,从相应的策略中抽样生成 u\mathbf{u}u,在测试阶段,采用贪心方法。
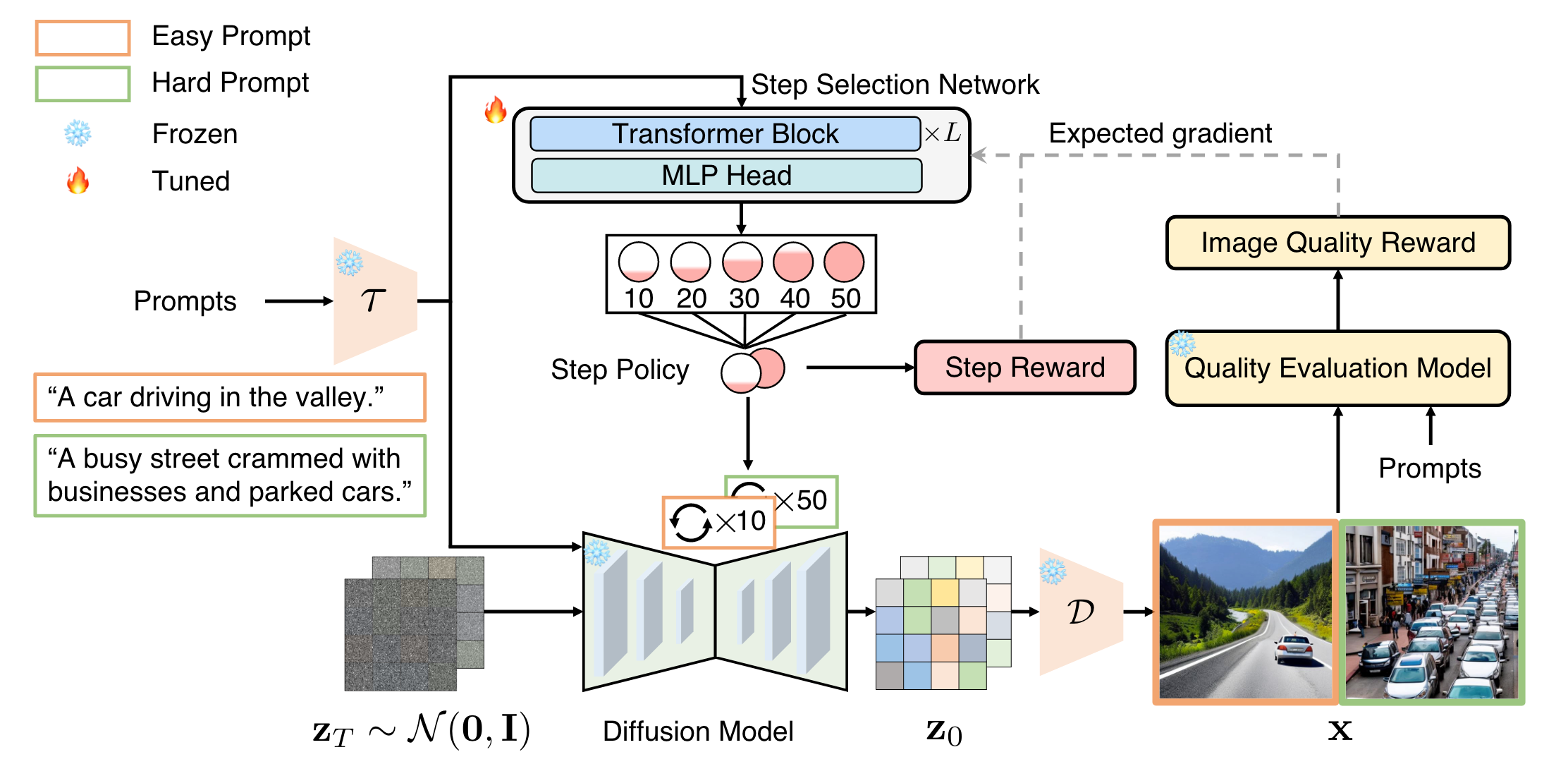
Reward function
两部分:1)Image quality Reward , 2)step reward (balance quality 和 inference time)
Image quality Reward
这一部分是使用了一个图像质量评估模型 fqf_qfq,表示为 IQS。
模型从两个维度评估图像质量:
- image-text alignment:图文对齐来衡量生成图像和文本提示之间的一致性。
- perceptual fidelity:生成的图像应该忠实于物体的形状和特征,而不是杂乱无章地生成。
因此,IQS score 的分数反映着图像的质量。image quality reward fomulate as: Q(u)=fq(x)\mathcal{Q}(\mathbf{u})=f_q(\mathbf{x})Q(u)=fq(x)
Step reward
O(u)=1−tSmax\mathcal{O}(\mathbf{u})=1-\frac{\mathbf{t}}{S_{max}}O(u)=1−Smaxt
表示为相对于 S\mathcal{S}S 中的最大时间步节省的规范化步骤。(相当于省下了多少时间)
整体的奖励函数如下所示:
R(u)={O(u)+λQ(u)for high quality image−γelse \left.R(\mathbf{u})=\left\{\begin{array}{ll}\mathcal{O}(\mathbf{u})+\lambda\mathcal{Q}(\mathbf{u})&\text{for high quality image}\\-\gamma&\text{else}\end{array}\right.\right. R(u)={O(u)+λQ(u)−γfor high quality imageelse
其中,λ\lambdaλ 和 γ\gammaγ 是超参数。λ\lambdaλ 用于控制图像质量,γ\gammaγ 是当生成的图像质量较低时对奖励函数施加的惩罚。
那么如何判断图像质量是低还是高呢?
这里并不是设定一个阈值,来判断好坏。
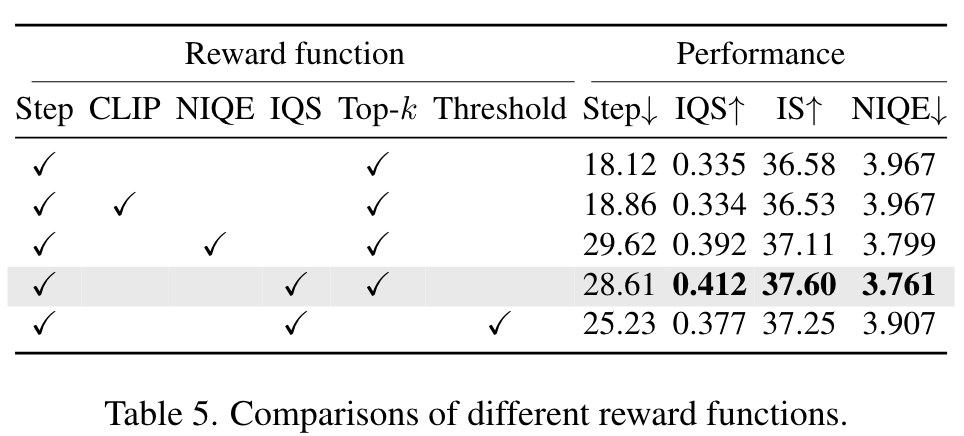
而是给定一个 prompt,然后为 steps 集合 S={10,20,30,40,50}\mathcal{S} =\{10,20,30,40,50\}S={10,20,30,40,50} 中的每一步生成一张图像;
然后看图像分数是否在这五张图像中排名前k,我们认为图像质量得分高(我们经验地将k设置为3)。
我的理解,就是看前面较小的时间 t 生成的图像是否能够排到前三,如果可以就是具有优化空间;
那么优化目标就是最大化期望奖励:
maxwL=Eu∼πfR(u)\max_\mathbf{w}{\mathcal{L}}=\mathbb{E}_{\mathbf{u}\sim\pi_f}R(\mathbf{u})wmaxL=Eu∼πfR(u)
使用策略梯度算法来学习 步长选择网络 fsf_sfs 的参数 www。期望的梯度推导如下:
∇wL=E[R(u)∇wlogπf(u∣p)]\nabla_\mathbf{w}{\mathcal{L}}=\mathbb{E}\left[R(\mathbf{u})\nabla_\mathbf{w}\log\pi^f(\mathbf{u}\mid\mathbf{p})\right]∇wL=E[R(u)∇wlogπf(u∣p)]
使用小批量样本,用蒙特卡罗采样进一步近似,得到:
∇wL≈1B∑i=1B[R(ui)∇wlogπf(ui∣pi)]\nabla_{\mathbf{w}}\mathcal{L}\approx\frac{1}{B}\sum_{i=1}^{B}\left[R\left(\mathbf{u}_{i}\right)\nabla_{\mathbf{w}}\log\pi^{f}\left(\mathbf{u}_{i}\mid\mathbf{p}_{i}\right)\right]∇wL≈B1i=1∑B[R(ui)∇wlogπf(ui∣pi)]
其中,BBB 是批量大小,ui\mathbf{u}_iui 是从策略 πf\pi^fπf 中采样的步长选择向量,pi\mathbf{p}_ipi 是对应的文本提示。
Training and inference
- 在上述训练过程之后,选择网络学习在推理时间和生成质量之间取得平衡的步长使用策略。
- 在推理阶段,对于不同的提示,使用s中的最大概率分数来确定生成步骤的数量,从而实现动态推理。
对于视频的生成,和上述的过程类似,只是在奖励函数上有所不同,这里不再赘述。
Experiments
为了评估我们方法的有效性和通用性,我们在三个图像数据集上进行了广泛的实验:MS COCO 2017 , Laion-COCO, DiffusionDB;
以及两个视频数据集:MSR-VTT[51]和InternVid[44]。
在MS COCO 2017中,我们的训练集由118287个文本描述组成,并且使用验证集中的所有25014个文本对进行测试。对于Laion-COCO,我们随机选择200K个文本描述用于训练,20K个文本图像对用于测试。DiffusionDB的训练集和测试集的划分遵循与Laico-COCO相同的范式。
Metric
FID 、 IS、 CLIP Score,NIQE, IQS
Results
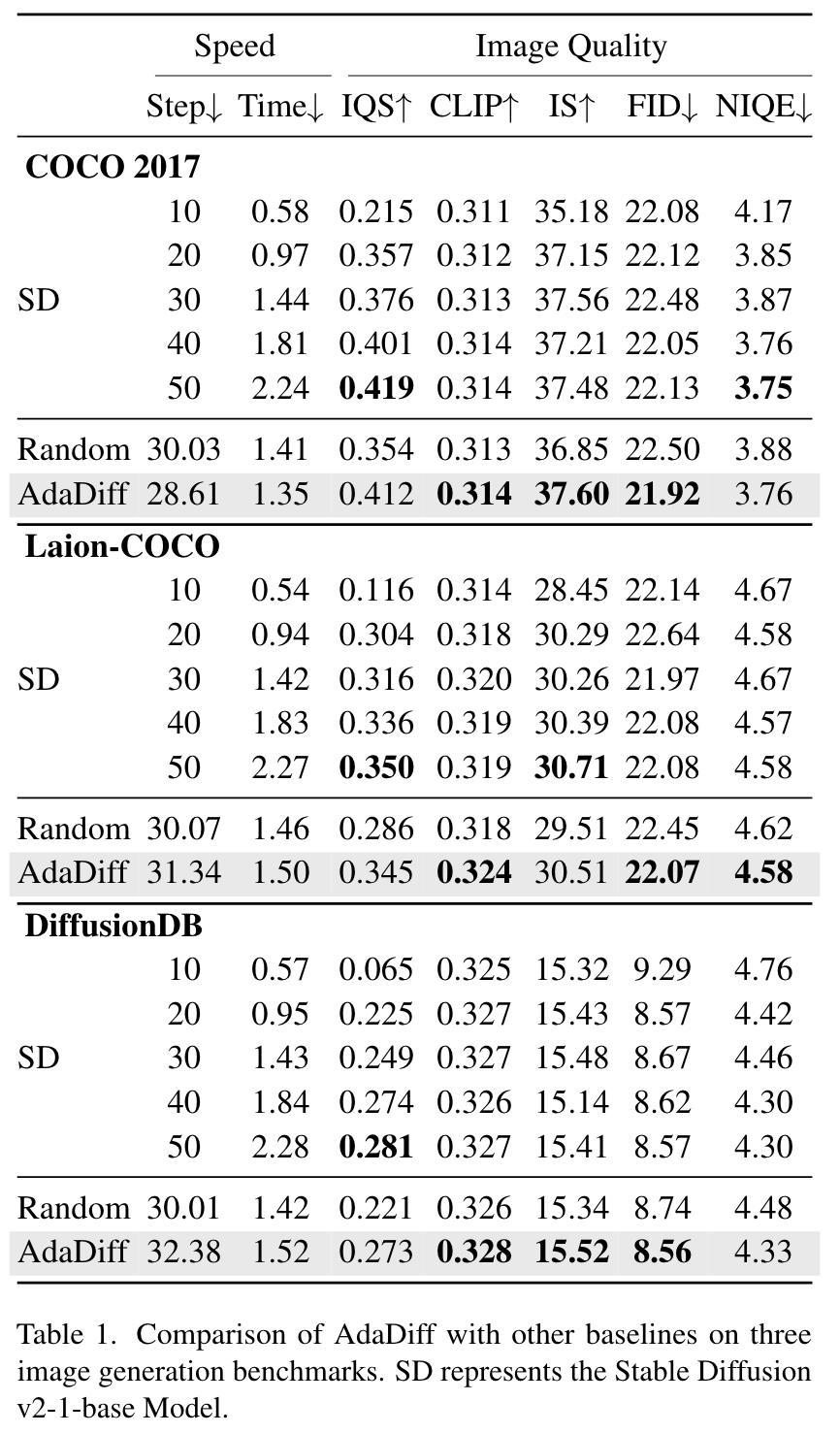
这里的 random 指的是:对不同提示使用随机步骤选择策略,我们报告5次运行使用的平均步骤。
我们知道之前的扩散轨迹都是通过 ODE求解器来求解的,作者使用稳定扩散中的DPM-Solver[21]采样器来评估其在图像生成中的性能,如下表所示。与50步生成相比,AdaDiff平均为每个提示分配24.09步,进一步节省50.8% 的生成时间,同时保持相当的图像质量。
与随机策略相比,学习后的自适应策略不仅使推理时间提高了19.6%,而且在五个指标上提高了图像质量。这些结果表明,AdaDiff可以作为即插即用组件与其他加速方法相结合,用于动态生成。
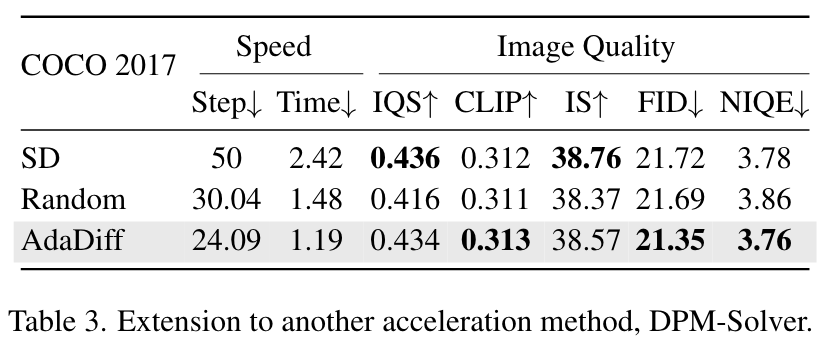
实验来看,图像质量其实就是 0.0几 个点,这个说是相当。但是时间上的提升还是很明显的。
但是从这个角度来看,文本提示的丰富性难道只通过目标数量或者拥挤程度来衡量吗?从这个地方来加速,感觉有点不太合理。


















 168
168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









