 Transformer架构学习笔记
Transformer架构学习笔记




一、Transformer 的诞生背景与优势
传统序列模型(如 RNN/LSTM)受限于循环计算的串行特性,难以并行处理长序列,且长距离依赖问题显著。2017 年,Vaswani 等人在《Attention Is All You Need》中提出Transformer 架构,彻底摒弃循环与卷积,仅依赖注意力机制实现序列建模,成为自然语言处理领域的里程碑。
两大显著优势:
1.可捕获间隔较长的语义关联。
2.充分利用分布式GPU进行并行训练,提升模型训练效率。
二、Transformer 整体架构
Transformer 总体架构包括四部分:输入、输出、编码器、解码器。
(一)输入层
1.词嵌入(Token Embedding)
对输入的文本以单词为单位进行切分,再对单词序列编码,使用独热向量表达,再将独热向量映射为低维向量,可通过Word2Vec实现。
2.位置编码(Positional Encoding)
思路历程:整数位置编码→二进制位置编码→正弦位置编码
为弥补注意力机制缺乏时序信息的缺陷,通过正弦 / 余弦函数生成位置向量,公式为:
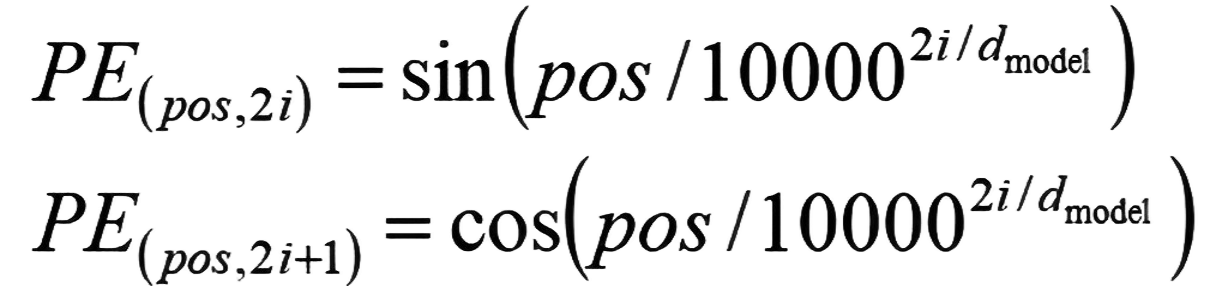
(二)、编码器(Encoder)
由多个同样的编码器块组合而成
1.多头自注意力层(Multi-Head Self-Attention)
注意力机制基本思想:“移动”量由其他词的意义(值)和其他词与当前词相关度决定。
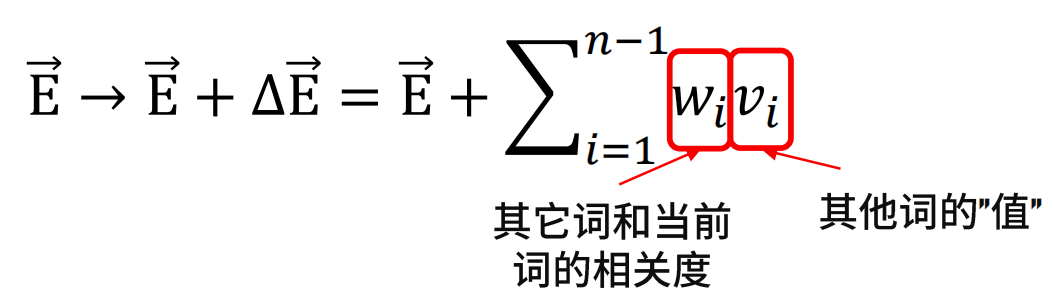
自注意力机制:
(1)由每个编码器的输入向量生成三个向量,即查询向量、键向量和一个值向量。这三个向量是通过词嵌入与三个权重矩阵相乘后创建出来的。将以上所得到的查询向量、键向量、值向量组合起来就可以得到三个向量矩阵Query、Keys、Values。
(2)计算得分。我们需要拿输入句子中的每个单词对目标单词进行打分。这些分数是通过所有输入句子的单词的键向量与“目标单词”的查询向量相点积来得到的。
(3)将分数除以8(让梯度更稳定,这里也可以使用其它值),然后进行softmax处理。得到的softmax分数决定了每个单词对编码当下位置单词的贡献。
(4)将每个值向量乘以对应softmax分数(以此来关注语义上相关的单词,并弱化不相关的单词),最后对加权值向量求和,即得到自注意力层在该位置的输出。
多头自注意力机制:使用多组矩阵得到多组查询、键、值矩阵,然后每组分别计算得到一个Z矩阵,再得到最终的Z矩阵。这扩展了模型专注于不同位置的能力。
2.前馈全连接层:Add(残差连接)、Norm(层归一化)。
(三)解码器(Decoder)
解码器同样由N=6个层堆叠,每层包含三大子层:
1.掩码多头自注意力层
掩码操作(mask):计算注意力时,每一个新词(query)只能和之前出现的词进行相关运算。
2.多头自注意力层 与编码器相同
3.前馈全连接层 与编码器相同
(四)输出层
由线性层和Softmax层串联而成。
线性层:通过对上一步的线性变化得到指定维度的输出,也就是转换维度的作用.
Softmax层:使最后一维的向量中的数字缩放到0-1的概率值域内,并满足他们的和为1.

















 1486
1486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









