



一、课程核心概述
神经网络与深度学习作为人工智能领域的关键分支,致力于运用机器模拟人类智能,解决复杂的现实问题。人工智能通过多种途径实现智能化,机器学习便是其中核心环节,其借助数据经验优化计算机系统性能,在处理传统程序难以解决的问题时优势显著。然而,随着数据量爆发式增长以及非结构化数据增多,传统机器学习面临诸多挑战,如在大数据处理和特征工程方面的瓶颈,深度学习则应运而生,成为推动人工智能发展的核心力量。
二、神经网络基础原理
(一)线性回归
线性回归作为一种基础的统计分析方法,旨在精准确定变量之间的定量关系。以房屋销售数据为例,我们可通过构建线性函数拟合数据,进而预测新数据对应的输出值。在这个过程中,训练集、输出数据、拟合函数、训练数据条目数以及输入数据维度等要素构成了线性回归的基础框架。

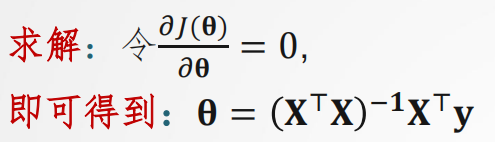
(二)线性二分类与感知机
线性分类器通过对特征进行线性组合来做出分类决策,与线性回归相比,二者在输出意义、参数意义以及维度上存在明显差异。在解决二分类问题时,我们引入 Sigmoid 函数,将线性输出巧妙转换为概率形式,从而实现分类目的。

感知机作为神经网络和支持向量机的重要基础,专门用于解决线性分类问题。其模型表达式为:
![]()
通过定义损失函数:
![]()
采用迭代更新权值的方式寻找最佳分类超平面。
(三)神经元模型
人工神经元模型(如 M-P 模型)灵感源自生物神经元的结构与功能,它通过对输入信号进行加权求和,并借助激发函数进行处理,实现信息的传递与转换。
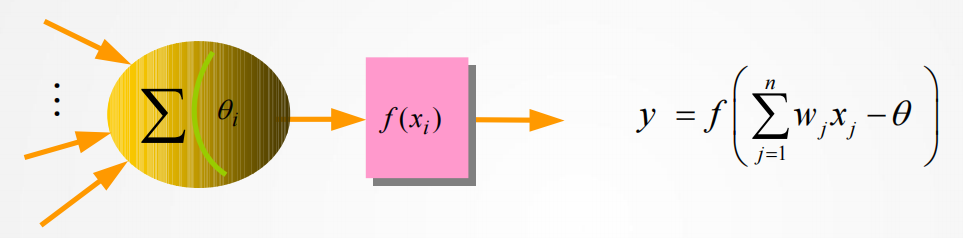
常见的激发函数包括非对称型 Sigmoid 函数、对称型 Sigmoid 函数和对称型阶跃函数,它们各自具有独特的特性,在不同场景下发挥着重要作用。
Hebb 规则为神经元连接权值的调整提供了重要依据,其核心思想是连接权值的调整量与输入和输出的乘积成正比。这一规则在神经网络的训练过程中,对于优化神经元之间的连接强度、提升网络性能具有关键意义。
三、多层前馈网络与 BP 算法
(一)多层感知机的架构与应用
多层感知机通过在输入层和输出层之间巧妙添加隐层,有效解决了线性不可分的难题,如著名的 XOR 问题。相关定理表明,三层阈值节点网络具备实现任意二值逻辑函数的能力,而三层 S 型非线性特性节点网络则能够逼近连续函数或平方可积函数,这为多层感知机在复杂问题求解中的广泛应用奠定了坚实的理论基础。
(二)BP 算法的原理与流程
BP 算法作为多层前馈网络的核心学习算法,基于梯度下降法,融合了正向传播和反向传播两个关键过程。在正向传播阶段,输入信号从输入层依次经过隐层,最终传至输出层。若输出结果符合预期,则学习过程结束;反之,则进入反向传播阶段。
在反向传播过程中,算法将误差(样本输出与网络输出之差)按照原连接通路进行反向计算,并依据梯度下降法对各层节点的权值和阈值进行调整,从而逐步减小误差,使网络输出不断逼近真实值。这一过程不断迭代,直至网络达到满意的性能指标。
四、神经网络性能优化策略
(一)常用优化技巧
在神经网络的训练过程中,模型初始化是至关重要的环节。常见的初始化方法包括在 [-1,1] 区间内按均值或高斯分布进行初始化,以及 Xavier 初始化。Xavier 初始化旨在确保网络中信息能够顺畅流动,使每一层输出的方差保持相对稳定。
数据的合理划分与利用对于模型训练同样关键。通常,数据被划分为训练集、验证集和测试集,常见的划分比例为 70%、15%、15% 或 60%、20%、20%。当数据量充足时,可适当减少训练和验证数据的比例。此外,K 折交叉验证技术通过多次划分数据进行训练和验证,能够更准确地评估模型性能。
为有效防止过拟合现象的发生,权重衰减和 Dropout(暂退)技术被广泛应用。权重衰减通过在损失函数中添加惩罚项,约束权值的大小,避免权值过大导致过拟合;Dropout 则在训练过程中随机将部分节点置零,减少神经元之间的依赖,提高模型的泛化能力。
(二)优化算法的创新与应用
动量法针对 SGD 在病态曲率区域的困境,引入动量概念进行优化。其更新公式为:
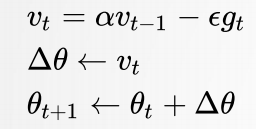
这一方法使得模型在训练过程中能够更稳定地朝着最优解前进,减少震荡,提高训练效率。
自适应梯度算法(如 AdaGrad、RMSProp、Adam)则根据参数梯度的变化自适应调整学习率。AdaGrad 根据历史梯度平方值总和的平方根对学习率进行缩放;RMSProp 通过指数衰减平均丢弃遥远的历史梯度,解决了 AdaGrad 中学习率过度衰减的问题;Adam 算法在 RMSProp 的基础上,进一步保留历史梯度的指数衰减平均,兼具动量和自适应学习率的优势,能够更高效地训练模型。
五、卷积神经网络的技术演进与应用
(一)卷积神经网络基础原理
全连接网络在处理大规模数据时,存在权值过多、计算速度慢、容易过拟合等问题。卷积神经网络则通过局部连接、权值共享和多层结构等创新设计,有效减少权值连接数量,并实现对数据的分层特征提取。
卷积神经网络主要由卷积层、下采样层和全连接网络组成。卷积层利用卷积核对输入数据进行卷积操作,提取特征;下采样层通过池化操作(如均值池化或最大池化)减少特征数量,降低计算复杂度;全连接网络则基于提取的特征进行分类决策。
(二)LeNet-5 网络的架构与特点
LeNet-5 作为早期的卷积神经网络,在手写字符识别领域取得了显著成果。其网络结构包含多个卷积层、池化层和全连接层。随着网络层次的加深,数据的宽度和高度逐渐减小,而通道数则相应增加。
与现代网络相比,LeNet-5 具有一些独特之处,如卷积过程中不进行填充、池化层采用平均池化而非最大池化、选用 Sigmoid 或 tanh 作为非线性环节激活函数,并且网络层数相对较浅,参数数量较少。
(三)基本卷积神经网络的发展与创新
随着技术的不断进步,AlexNet、VGG-16、残差网络、Inception 网络等经典卷积神经网络相继涌现。AlexNet 通过扩大网络规模,采用 ReLU 激活函数、Dropout 技术和双 GPU 策略,显著提升了模型性能;VGG-16 以其规整的结构和大量的参数,在图像识别任务中表现出色;残差网络通过引入残差块,有效解决了梯度消失问题,使得网络能够训练得更深;Inception 网络则通过特殊的模块设计,提高了网络对不同尺度特征的捕捉能力,进一步优化了模型性能。
六、常用数据集
在神经网络与深度学习领域,常用数据集为模型训练和评估提供了重要的数据支持。MNIST 数据集由手写数字图片和标签构成,是早期模型训练和测试的常用选择;Fashion-MNIST 作为 MNIST 的替代数据集,涵盖了 10 类商品的正面图片,在评估模型性能方面具有重要价值;CIFAR-10 包含 10 类彩色图像,为图像分类研究提供了丰富的数据资源;PASCAL VOC 主要用于目标分类、检测和分割任务;MS COCO 则是源自复杂日常场景的数据集,在目标识别、检测等领域发挥着关键作用;ImageNet 规模庞大,包含大量图像和众多类别,是图像识别领域的重要基准数据集。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









