







 RocketMQ消费者机制包括集群和广播模式,Push与Pull模式。Push模式更常见,消费者通过offset跟踪消费进度。优化包括利用OS cache加速ConsumeQueue访问,以及在集群中通过负载均衡减少Master压力,提高吞吐量。
RocketMQ消费者机制包括集群和广播模式,Push与Pull模式。Push模式更常见,消费者通过offset跟踪消费进度。优化包括利用OS cache加速ConsumeQueue访问,以及在集群中通过负载均衡减少Master压力,提高吞吐量。
RocketMQ消费消息有一个消费者组的概念,一个消费者组里面包含了多个消费者。
消费者组有两种消费方式,一种是集群模式,消费者组内只有一个消费者能消费到Topic下的同一条数据,其余消费者则无法消费到,而另外的消费者组也可以有一个消费者能消费到这条消息,这是默认的消费模式;还有一种是广播模式,Topic下的同一条消息将会被消费者组内的所有消费者消费一遍。
消息传送也有两种模式,一种是Push模式,一种是Pull模式:
Pull模式是消费者主动去RocketMQ的Broker机器上拉取数据。
Push模式本质上也是基于Pull模式,本质就是消费者一直去Broker上拉数据,如果有新的消息可以消费,就立马返回消息去处理,处理完之后再拉取下一批消息,时效性非常好,就好像Broker一直在不停的往消费者推送消息。
一般来说,使用Push模式较多,Pull模式的代码更加复杂,而且时效性上Push模式更好。
RocketMQ中消费者在读取消息的时候,就像我们读书一样,书本就类似很多需要消费的消息,比如我们今天看了10页,“哎呀,好累呀,不知道写的些啥,休息一下吧”,然后我们就会在第10页上加一个书签,这样之后我们就记得我们看到了哪里。
消息消费也是一样的,也有这么一个“书签”,就是offset。我之前的文章中(RocketMQ的数据存储及消息持久化)有说到过RocketMQ的MessageQueue,这是RocketMQ中的数据分片,MessageQueue将消息持久化到CommitLog中,MessageQueue和ConsumeQueue可以认为是一一对应的,ConsumeQueue主要保存了这个MessageQueue的所有消息在CommitLog文件中的物理位置,也就是Offset偏移量。除了Offset之外,ConsumerQueue还保存了消息的长度和tag hashcode,一条数据是20字节,每个ConsumerQueue可以保存30万条数据,大概每个文件5.72M,一个MessageQueue实际在磁盘上对应了多个ConsumerQueue文件。
老规矩还是上图:
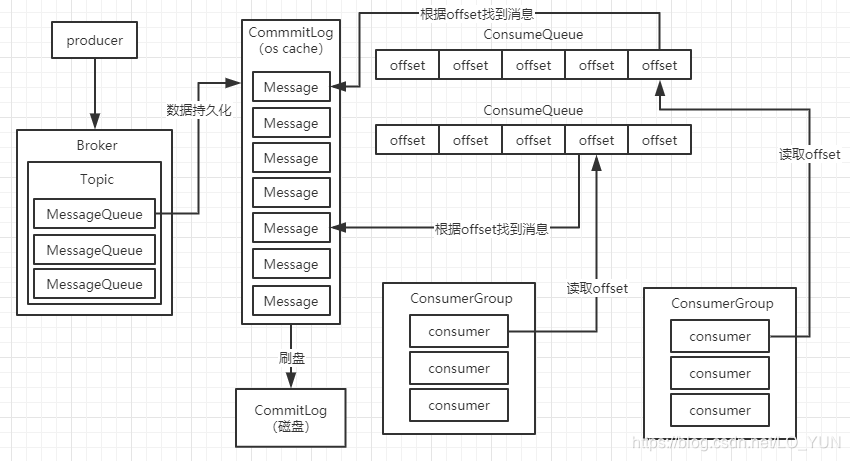
所以消费者获取消息的本质就是,Broker根据MessageQueue和消息开始消费的位置,去ConsumeQueue里面读取对应消息的offset,然后再通过offset去CommitLog中找到对应的消息,返回给消费者。当消费者消费完成之后,会将offset再交给Broker,告诉Broker已经消费完成。
RocketMQ本身的吞吐量很大,那么对于消息消费,又做了哪些优化呢?
现在我们知道,消息消费需要读取ConsumeQueue的offset,才能知道从哪里开始消费消息,那么在这个读取ConsumeQueue的过程中肯定做了优化。
- 大量的ConsumeQueue在写入的时候,会优先写入os cache中。根据局部性原理,os(operation system)本身也会做优化,读取磁盘文件时,会自动把磁盘的一些相邻文件数据缓存到os cache中。
- ConsumeQueue中主要是存储offset信息,所以ConsumeQueue很小,几十万条消息也就是几M左右,所以可以全部加载到os cache中,读取os cache几乎跟直接读内存一样快,所以消费数据的性能很高。
- 当从ConsumeQueue中读取到offset之后,就需要去CommitLog中获取实际的消息,一个CommitLog的大小为1GB,肯定无法全部放入os cache中,所以部分CommitLog数据可以从os cache中获取,大部分还是需要从磁盘中获取。如果RocketMQ是集群部署的话,这时Master发现消息处理较慢,下次拉取数据时就会让消费者去Slave上拉取消息,减少Master的工作量,尽量让消费者读取的都是os cache中的数据,这样才能一直保持较高的吞吐量。

















 1174
1174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









