




在大模型参数突破万亿级的今天,算力已成为衡量国家科技竞争力的核心指标。传统云计算在应对 TB 级参数同步、十万卡集群调度时,面临 "存储墙"" 通信瓶颈 " 等结构性挑战。云智算通过算网基础设施与 AI 技术的深度融合,构建了从算力生产到智能服务的全链条解决方案,其技术演进直接决定着大模型时代的产业智能化进程。
云智算的内涵与架构革新
一、云智算的定义与本质
云智算是通过算网基础设施与AI人工智能核心技术深度融合,提供一体化算网资源、全栈式开发环境、一站式模型服务、多样化场景应用的新型云服务模式。
与传统云计算相比,云智算以 AI 为核心驱动力,实现从单纯的计算资源供给向智能化服务的转变。能够根据不同的业务需求,灵活调度算网资源,为用户提供更加高效、智能的计算服务。云智算是下一代云计算范式,将重新定义算力服务的形态与边界。
二、体系架构升级
云计算的体系架构经历了从 IaaS(基础设施即服务)、PaaS(平台即服务)、SaaS(软件即服务)三层架构向 AIIaaS(算网一体化供给的基础设施服务)、AIPaaS(面向各类 AI 开发者的工具平台服务)、MaaS(加速 AI 一站式落地的模型服务)、AISaaS(覆盖多样化场景的 AI 应用服务)四层架构的升级。
- AIIaaS 通过泛在网络推动各类算力 “联算成网”,依托算网大脑实现算力的灵活调度,满足不同场景下对算力的多样化需求。在大规模数据处理场景中,能够快速调配所需的计算资源,确保任务高效完成。
- AIPaaS 为 AI 开发者提供全环节的工具链和开发环境,涵盖数据处理、模型训练、测试等各个阶段,大大提升AI 创新的效率,缩短项目开发周期。
- MaaS 汇聚丰富的模型、能力和智能体资源,加速AI 在各行业的应用落地。企业可以通过 MaaS 平台快速获取适合自身业务的模型,降低 AI 应用的门槛和成本。
- AISaaS 则直接面向多样化的场景,为用户提供具体的 AI 应用服务,推动生产方式、生活方式和社会治理方式的数智化转型。在智能安防领域,AISaaS 应用能够实时监测异常情况,及时发出警报,有效提升安防效率。
云智算四层架构在大模型场景中呈现出独特优势:
- AI IaaS 层通过算网大脑实现异构算力调度,某大模型训练中,跨地域算力调度效率提升 40%,资源利用率从 35% 提升至 72%;
- AI PaaS 层的训练框架支持万亿参数模型并行优化,采用 FP8 混合精度训练时,算力效率提升 3 倍,梯度溢出率控制在 0.5% 以下。
云智算核心技术全景解析
一、 计算技术突破算力瓶颈
1、算力芯片——多元异构,协同共进
随着大模型训练和推理对算力要求的不断提高,传统的 CPU 已难以满足需求,专为 AI 设计的异构计算芯片成为焦点。GPU 凭借其强大的并行计算能力,成为智算的核心芯片。例如,英伟达的 GPU 在深度学习领域广泛应用,其强大的算力加速了模型训练的速度。同时,国产 GPU 也在不断发展,通过技术创新提升性能,逐步缩小与国际先进水平的差距。
除了 GPU,DPU(数据处理单元)芯片也在云智算中发挥着重要作用。DPU 专注于数据处理和网络加速,能够提升智算网络性能,实现自主算法的落地。某云服务提供商推出的基于 DPU 的解决方案,有效提升了数据传输的效率,降低了网络延迟。在未来,基于 SIMT 架构与 RISC-V 指令集的 AI 智算芯片将有望构建更加开放、自主的生态,为云智算提供更强大的算力支持。
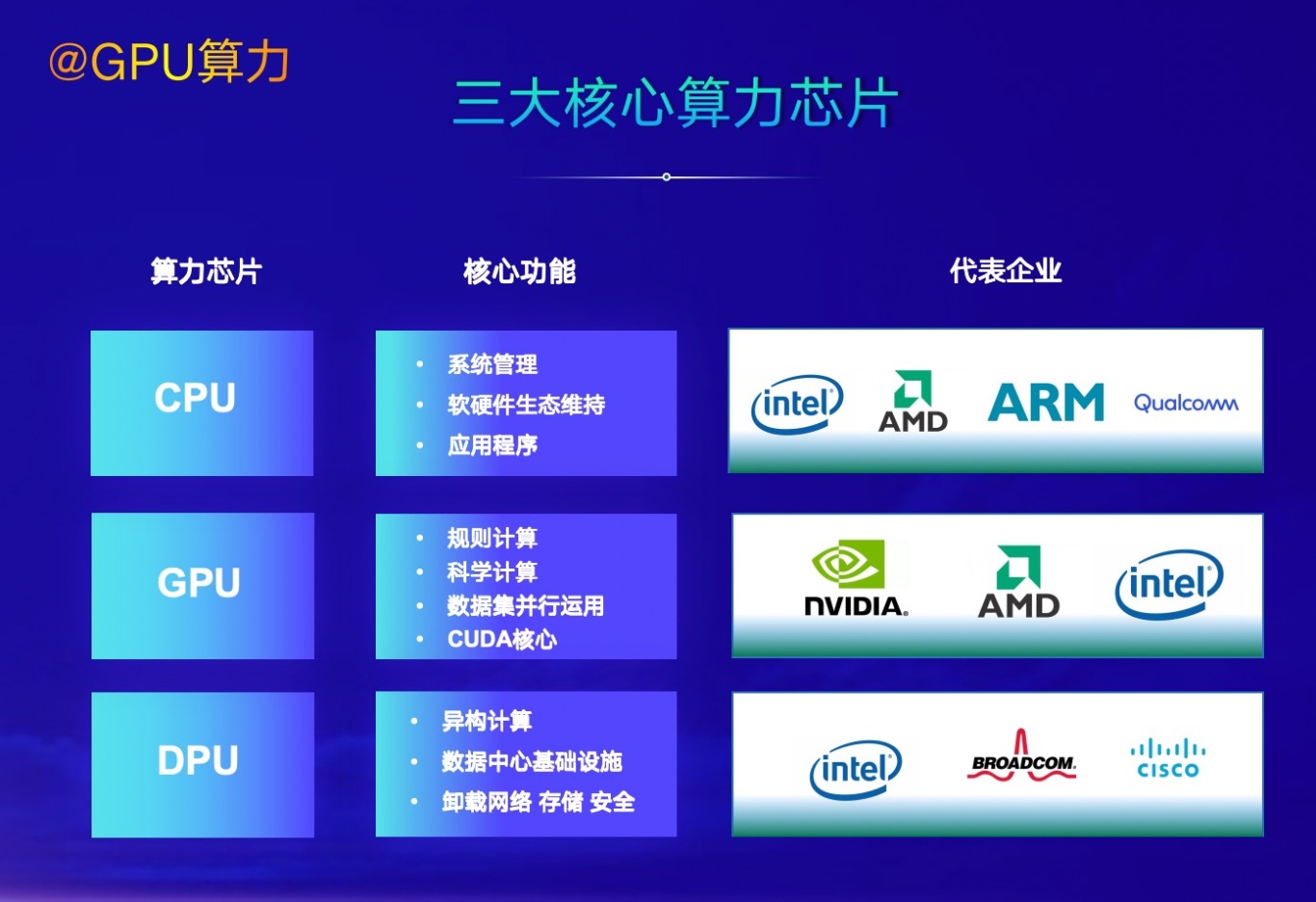
三大核心算力芯片
2、智算超节点——打造算力核心集群
智算超节点是云智算的关键基础设施,它能够实现高密度的算力集成和高速互联。例如,英伟达发布的 NVL72 超节点支持单机内 72 个 GPU 高速互联,极大地提升了算力密度。为了应对全球智能算力竞争,国内企业也在积极布局智算超节点。基于原创 COCA 异构计算架构打造的智算超节点,支持 64 卡互联,点对点带宽高达 800GB/s,时延低至微秒级,能够满足大模型训练对海量数据处理和高速通信的需求。这种超节点采用开放式硬件架构,兼容不同厂商的 GPU,通过软件栈优化提升推理性能,为云智算提供了强大的算力底座。
3、算力原生——打破生态壁垒
面对国内智算芯片生态碎片化的问题,算力原生技术应运而生。算力原生通过统一的 API 和集合通信库,实现了对异构设备的统一管理和调度,使得智算应用能够 “一次开发、跨芯部署”。某企业基于算力原生平台,成功将服务上线时间从原来的数小时缩短至分钟级,大大提高了开发和部署效率。未来,算力原生技术将进一步完善 AI 芯片的统一抽象机制,探索虚拟指令集技术,构建更加融通的 XPU 算力底座,促进智算应用生态的繁荣发展。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2855
2855

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









