







MMOE

- 针对的问题:
- 多任务学习,目的是通过构建一个模型,能够用在不同目标或者任务上。但是这种模型的预测质量往往对于任务之间的关系很敏感。
- 产生的新想法:
- 提出了Multi-gate Mixture-of-Experts(MMoE), 多门控制的混合专家网络。在MoE(专家网络)的基础上,通过在任务间共享专家网络的子模型,来使MoE适应多任务学习。
例如,在电影推荐系统中,通常需要同时优化多个目标,例如同时预测用户的购买率、用户的打分等。
研究表明迁移学习可以通过利用正则化(regularization)和迁移学习(transfer learning)来提升在所有任务上的表现。但是实际上,多任务学习模型往往不如单任务模型表现得好。因为基于DNN的多任务模型对于数据分布和任务之间的关系是很敏感的。对于任务之间的内在的冲突实际上对于预测在一些任务上是有影响的,特别是模型广泛共享的时候。
现状:
- 通过给每个任务生成数据来训练,来衡量任务之间的差异,作为多任务学习的一个信息。但是实际任务通常很负责,很难去衡量任务之间的不同性。
- 使用建模的方法去衡量任务间的不同性,而不是产出明显的差异。引入的更多的参数,在大规模推荐系统中不是很实用。
- 论文中提出新的MMoE框架。
细节:
模型结构:
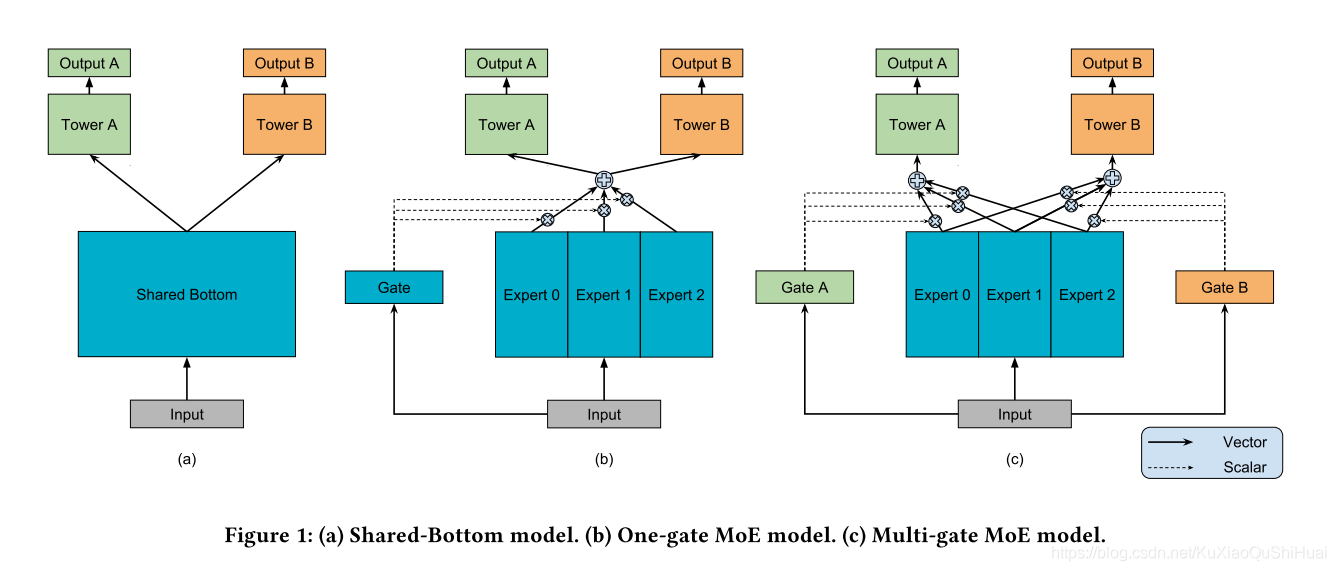
C为论文中提出的架构。
增加了很多的Expert,而且对于每一个训练任务(Tower),都会训练处一个单独的Gate,通过自己的Gate来确定使用不同的Expert.
公式细节:
b图中的one-gate MoE 模型:
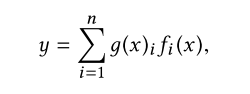
n个expert, 每个expert前面乘以1个系数再累加。每个expert输出都是多维的,所以y也是多维的。 g ( x ) i g(x)_i g(x)i 是一个系数,累加和为1.
对于多个门:
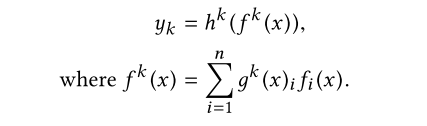
区别在于有k个任务时,我们有k个gate,每个gate参数不共享。
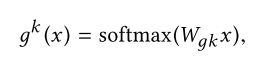
值得学习的实验思路:
皮尔逊相关系数:
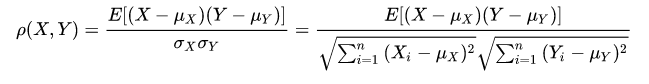
cosine相似度:
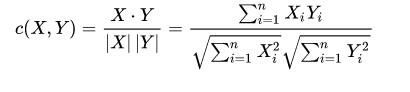
论文中有一段为了验证任务相关程度越大,模型的表现越好。所以人工生成了一些可以控制相关性的任务,生成方法如下:
- 理论基础:

上述可以通过给定一个p,来生成一个Label y相似度为p的两个任务。
注意在2式中,给定的p不是皮尔逊相关系数,利用的余弦相似度去近似的皮尔逊相似度。在线性的情况下,皮尔逊相似度就是给定的p,在非线性的情况下(生成的任务就是非线性的),**也是有正相关的。**正相关如下图(横轴是余弦相似度,纵轴是皮尔逊相关系数。):

接下是验证模型相关性对于多任务模型的影响,通过控制不同的相关系数p来训练模型看表现:

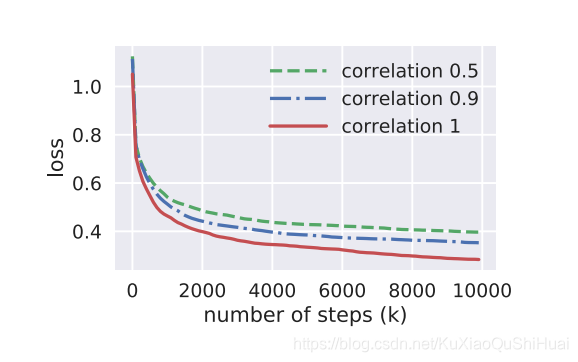
上图可以验证了相似度越大,多任务模型的表现效果就会越好。

















 1757
1757

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









