







文章目录
干货部分
概述与目标
特征选择的关键一步是特征选择矩阵,假设这个矩阵是 W k × n W^{k\times n} Wk×n,样本是 X n × 1 X^{n\times 1} Xn×1,n个特征(写成 X 1 × n X^{1\times n } X1×n,那么乘以权重的时候就需要一个转置。),如果W矩阵的每一行只有一个1,其他为0的话,那么 W X = X s u b WX=X_{sub} WX=Xsub, X s u b X_{sub} Xsub就是我们X的部分特征构成的子集。选出来的特征是根据W的每一行1的位置决定的。
这里面通常使用范数的方式来约束我们的特征选择矩阵W每行只有一个1,每列尽量也只有一个1。
这篇论文则没有使用范数,而是创建了一种交Concrete Selector Layer的层来解决这个问题。
方法描述
Concrete Selector Layer
这个Concrete Selector Layer是基于*Concrete random variables(Maddison et al., 2016; Jang et al., 2016)*设计的。这是个啥呢?
Concrete random variables
Concrete random variables是一个连续分布,这个分布有单一的封闭导数。
数学概念,难以理解,咱们直接往下看疗效
我们想要得到一个d维的 m j m_j mj向量:
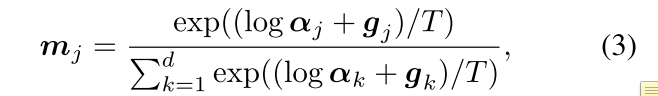
这个分布有三个参数:
-
Temperature参数,姑且叫他温度参数 T ∈ ( 0 , ∞ ) T\in (0,\infin) T∈(0,∞)。当T趋近于0时,concrete random variable会趋近于一个离散分布,这时候输出的向量 m j m_j mj就会在 a j / ∑ p α p a_j/\sum_p\alpha_p aj/∑pαp的概率下,变成一个one-hot向量(只有一个维度是1)。
**说人话就是趋近于0的时候, m j m_j mj向量中只有一个维度趋近于1,其他的趋近于0。**这是关键所在。
-
还有一个参数 α j \alpha_j αj,它是d维的,且里面每个数都大于0, α ∈ R > 0 d \alpha \in \Bbb R_{>0}^{d} α∈R>0d。我们从这个分布中取出一个d维度的向量 m j m_j mj,要这么算:
-
这里面有个 g j g_j gj, g j g_j gj也是一个d维度的向量。它是从Gumbel分布中采样来的。那么Gumbel分布是啥呢?
Gumbel分布就是一种分布咯。这里面先别管它。这里涉及到重参数技巧。关于Gumbel和重参数,见这
我们暂时知道 m j m_j mj咋来的就行了。。。
Concrete selector Layer
知道了Concrete Random variable是个啥,我们就来解读下论文提出的Concrete selector layer。这个其实简单了。
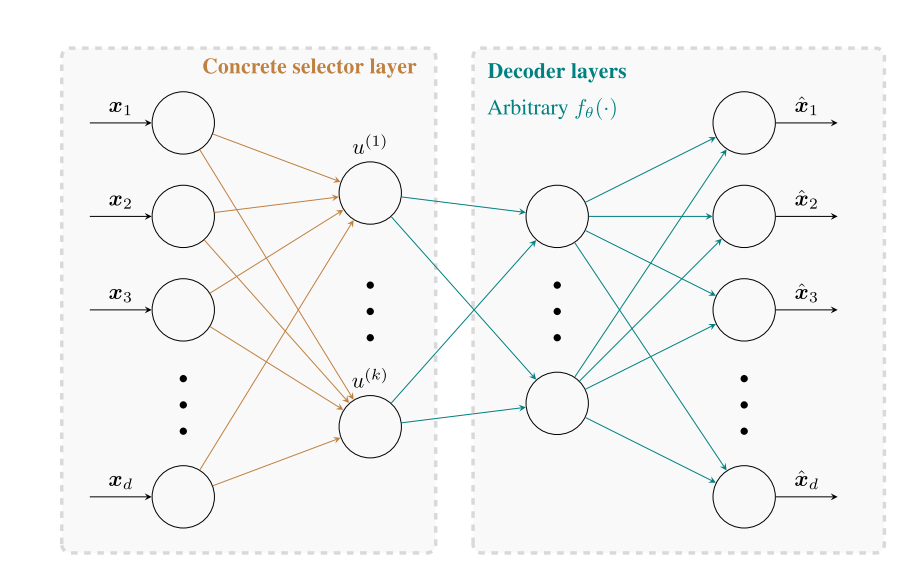
左边看似是一个简单的神经网络,但是其实在权重上做了手脚。
我们以batch size=1为例: X 1 × d X^{1 \times d} X1×d
U k × 1 = M k × d X T U^{k\times1} = M^{k\times d}X^T Uk×1=Mk×dXT
$u^{(i) } = m{(i)}X{T } $
- u ( i ) u^{(i)} u(i) 1x1
- m ( i ) m^{(i)} m(i)是M的某一行,1xd
- X T X^T XT ,dx1
i为矩阵某一行,关键的地方在于我们 m ( i ) m^{(i)} m(i)的来路,他是一个Concrete random variables。从(3)式中来的。而(3)式有一个重要的特点,就是当 T → 0 T\rightarrow 0 T→0时,是一个只有一个维度是1,其他为0的one-hot向量。这样就达到了只选择X中某一个特征的目的。 u ( i ) u^{(i)} u(i)是X的某一个维度的值。
右边就是常规的Decoder,不多说了。
训练
-
α i \alpha_i αi初始化为很小的正数,随着训练不断更新迭代。这样能够让selector layer去随机选择不同的输入特征的线性组合。当网络训练好后, α i \alpha_i αi就会变得很稀疏,因此网络就更有信心去选择某些特征。
-
T很大的时候,采样出来的 m j m_j mj没有one-hot特性,这样算出来的u(i)是众多特征的线性组合。如果T很小,采样出来是one-hot的 m j m_j mj,这就导致了不能够很好的进行探索。所以T要有一个动态的从大到小的更新。从 T 0 T_0 T0开始,逐渐到最终的 T B T_B TB的过程,论文使用的是first-order 指数衰减:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bhXxyY9I-1617111345423)(ConcreteAutoencoders.assets/image-20210330205253652.png)]
伪代码:

其他笔记(湿货部分)
一些细节,不建议阅读,可能写的辣眼睛。删了又可惜

特征选择方法分类(同西瓜书11章-11.2/11.3/11.4):
Filter(过滤式):
- 通常不考虑特征间的联系,训练和算法分离。早期主要是这种。
Wrapper(包裹式)
- 结合label,能够针对任务来选择最优的子特征。计算量较大,容易是NP问题。Lasso(1996)
Embedded(嵌入式)
- 无监督学习(使用编码解码手段)或者将选择器与训练器融为一体,关键在于使用正则化的方法约束权重,如UDFS(2011) MCFS(2010) AEFS(2017)
使用concrete selector layer作为encoder, 并且使用一个标准的NN作为decoder。
-
标准的维度减少的技巧,都是在保证最大化方差和最小的重建损失下,使用新的更少的特征代替原始数据特征,如principal compents analyasis或者autoencoders。
-
这类方法不能直接选择原始特征。所以不能直接用来减少冗杂的特征,降低试验成本。
论文中提出的方法concrete autoencoder:
使用Concrete distibution(一个松弛的离散分布)和参数重映射(Reparametrization trick)的技巧,,来选择特征去最小化损失函数

使用该方法选择20个特征点(像素点),然后重构。
问题表述
假设数据分布服从 p ( x ) p(x) p(x), 原始数据d个特征,从中选择一个子集S包含k个特征。同时学习一个重构的函数,能够使用k个特征重构出d个特征,记 f θ ( ⋅ ) : R k → R d f_\theta(·): R^k \rightarrow R^d fθ(⋅):Rk→Rd
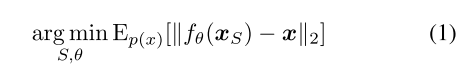
数学期望越小,说明咱们这个特征选择的越好。
然而,对于p(x)我们通常是不知道的。但是我们有n个example,我们假设都独立同分布与p(x)。
矩阵化表示n个example,d个features: X ∈ R n × d X \in R^{n\times d} X∈Rn×d
昨晚特征选择后的子矩阵,n个examples,d个features: X ∈ R n × k X \in R^{n \times k} X∈Rn×k
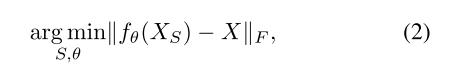
-
注意使用的是F范数。
-
这个式子很难优化,即使f是个简单的线性回归问题,选择以d的指数增长,是个NP-hard
问题。
-
f θ f_\theta fθ的复杂程度影响着重构的误差,甚至是S的选择。比如神经网络可能会比线性回归有更低的重构误差。论文希望寻找一个方法能够近似解决任何的形式的f。
-
论文选择MSE作为(1)(2)的优化指标。

















 478
478

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









