







 本文介绍了Ray Tune的核心概念,包括Trainables(训练对象)、Search Spaces(搜索空间)、Trials(审理)、Search Algorithms(搜索算法)、Schedulers(调度程序)和Result Grid(结果网格)。通过示例展示了如何定义搜索空间,选择搜索算法,使用调度程序优化强化学习模型的超参数,以及如何分析实验结果。RLlib结合Ray Tune,能有效提升调参效率。
本文介绍了Ray Tune的核心概念,包括Trainables(训练对象)、Search Spaces(搜索空间)、Trials(审理)、Search Algorithms(搜索算法)、Schedulers(调度程序)和Result Grid(结果网格)。通过示例展示了如何定义搜索空间,选择搜索算法,使用调度程序优化强化学习模型的超参数,以及如何分析实验结果。RLlib结合Ray Tune,能有效提升调参效率。
Ray Tune 的关键概念
Tune 有六个需要理解的关键组件。
- 首先,您定义要在搜索空间中调整的超参数,并将它们传递到指定要调整的目标的可训练文件中。
- 然后,您选择一种搜索算法来有效优化参数,并可以选择使用调度程序来提前停止搜索并加快实验速度。
- 您的可训练、搜索算法和调度程序与其他配置一起传递到 Tuner,它运行您的实验并创建试验。
- Tuner 返回一个 ResultGrid 来检查您的实验结果。
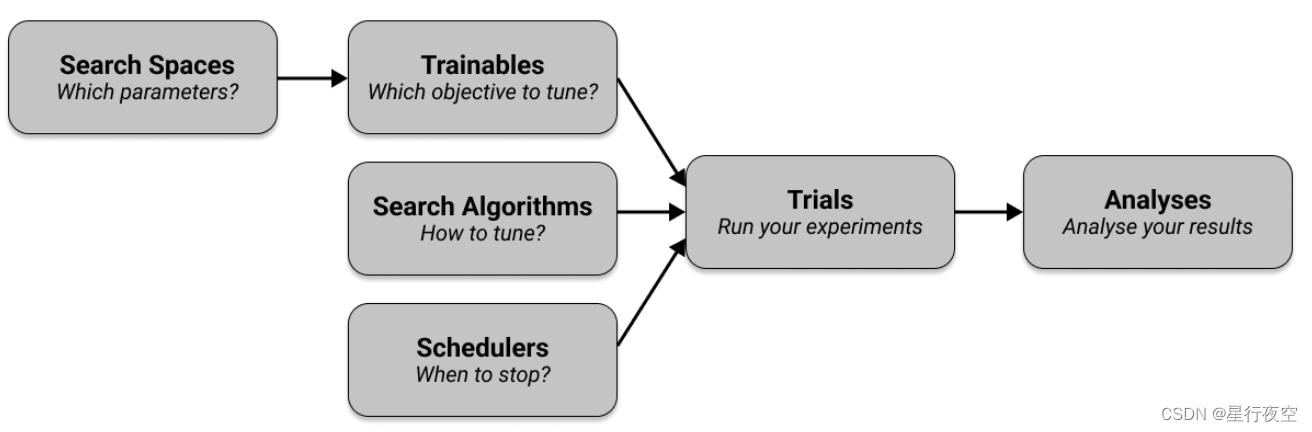
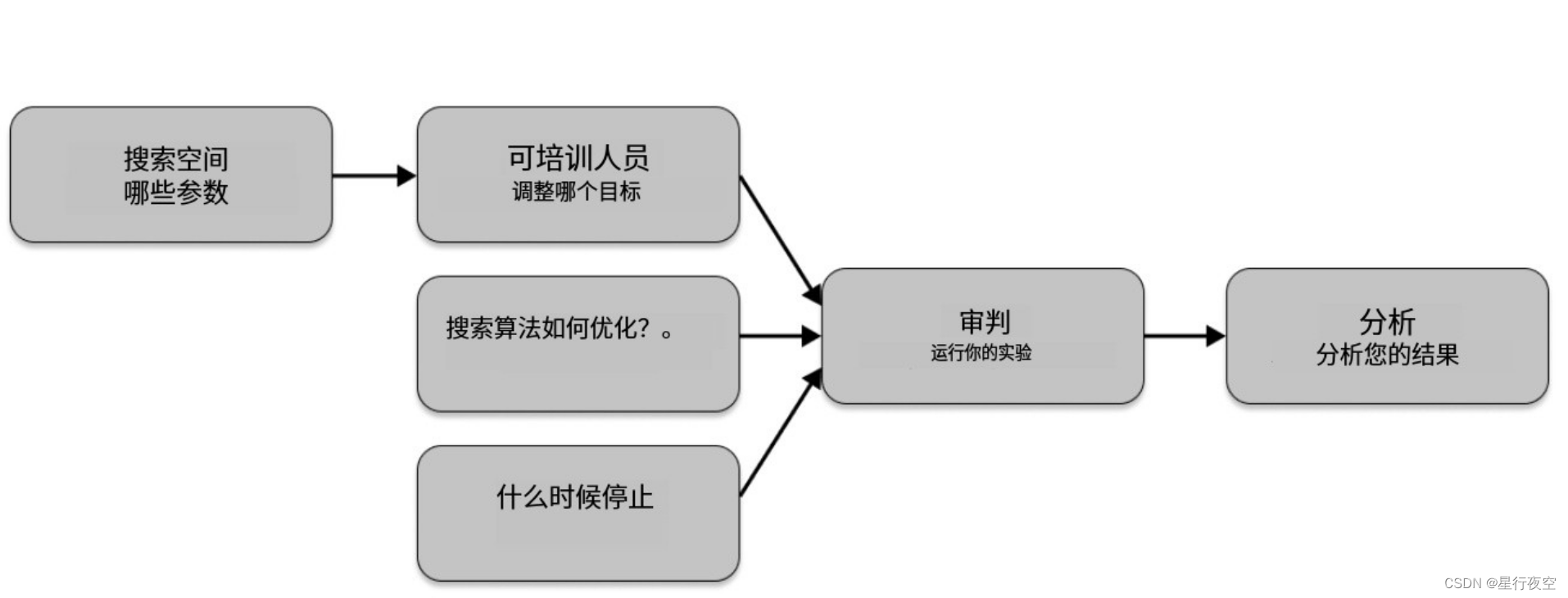
Trainables 训练对象
简而言之,Trainable 是一个可以传递到 Tune 运行中的对象。 Ray Tune 有两种定义可训练的方法,即函数 API 和类 API。两者都是定义可训练的有效方法,但通常建议使用 Function API,并在本指南的其余部分中使用。
假设我们想要优化一个简单的目标函数,例如 a (x ** 2) + b,其中 a 和 b 是我们想要调整以最小化目标的超参数。由于目标也有一个变量 x,我们需要测试 x 的不同值。给定 a、b 和 x 的具体选择,我们可以评估目标函数并获得最小化分数。
可训练对象:函数
from ray import train
def objective(x, a, b): # Define an objective function.
return a * (x**0.5) + b
def trainable(config): # Pass a "config" dictionary into your trainable.
for x in range(20): # "Train" for 20 iterations and compute intermediate scores.
score = objective(x, config["a"], config["b"])
train.report({
"score": score}) # Send the score to Tune.
可训练对象:类
from ray import tune
def objective(x, a, b):
return a * (x**2) + b
class Trainable(tune.Trainable):
def setup(self, config):
# config (dict): A dict of hyperparameters
self.x = 0
self.a = config["a"]
self.b = config["b"]
def step(self): # This is called iteratively.
score = objective(self.x, self.a, self.b)
self.x += 1
return {
"score": score}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 8351
8351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









