







 本文介绍了使用Python结合pytesseract库处理扫描PDF文件的方法,包括安装环境、配置tesseract,以及通过代码将PDF转换为PNG图像并提取文字内容,最终整合成完整的TXT文档。
本文介绍了使用Python结合pytesseract库处理扫描PDF文件的方法,包括安装环境、配置tesseract,以及通过代码将PDF转换为PNG图像并提取文字内容,最终整合成完整的TXT文档。
背景
有一些PDF资料,比较久远,是扫描出来的,需要文字版本
如果只需要其中几个片段可以直接微信截图识别
但是如果需要全本识别,人工的方式费时费力
OCR (Optical Character Recognition,光学字符识别),可以将图像中的文本信息提取出来,转换成计算机可处理的文本数据,为后续的分析和处理提供了便利。
虚拟环境准备
需要安装的库为:
pip install pytesseract
pip install fitz
pip install opencv-python
pip install PyMuPDF
pip install tesseract
pip install pillow
pip install pyperclip
pip install playwright
pytesseract设置
其中,pytesseract的安装比较复杂,需要设置虚拟环境
如果不设置,会遇到:
pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH
- 假设已经成功运行了pip install pytesseract
- 检查环境设置
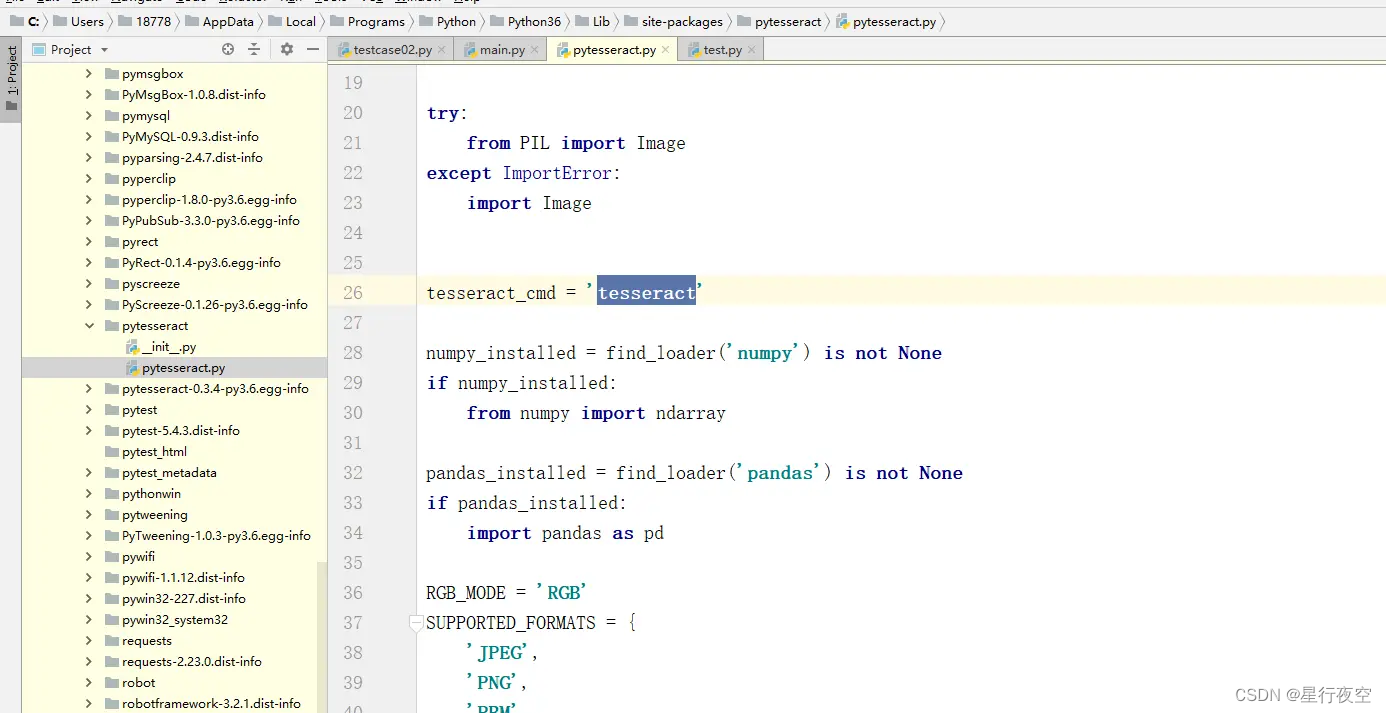
打开Python的外部库——site-packages——pytesseract——pytesseract.py
发现文件中有一句(最开头)tesseract_cmd =‘tesseract’
这里是没有指定路径的
- 从网上找到相应的‘Tesseract-OCR’下载安装
进入网站
https://github.com/tesseract-ocr/tessdoc/blob/main/Installation.md
找到对应系统文件,例如win
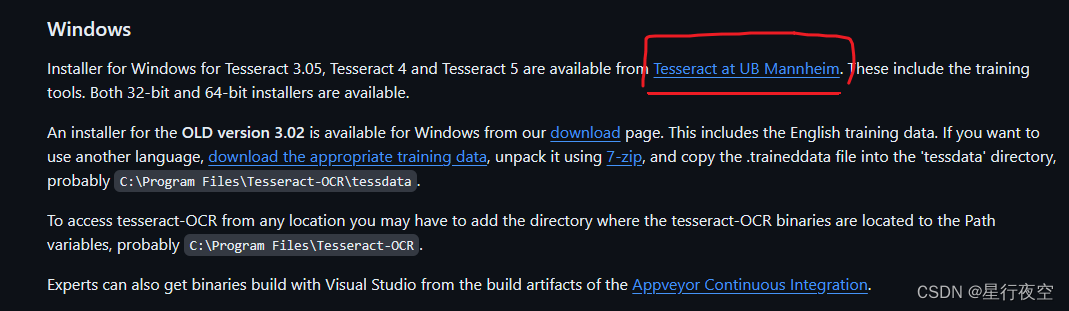
亲测下载第二个即可

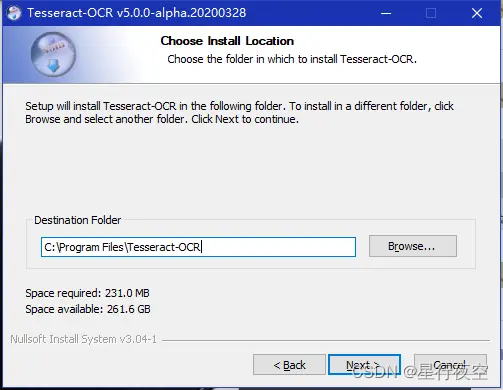
- 自定义安装,不要改变路径(最好不要)注意,安装的时候要勾选所有的可安装内容,不然没有中文
- 添加到环境变量的系统变量(PATH)
系统搜索环境变量,打开

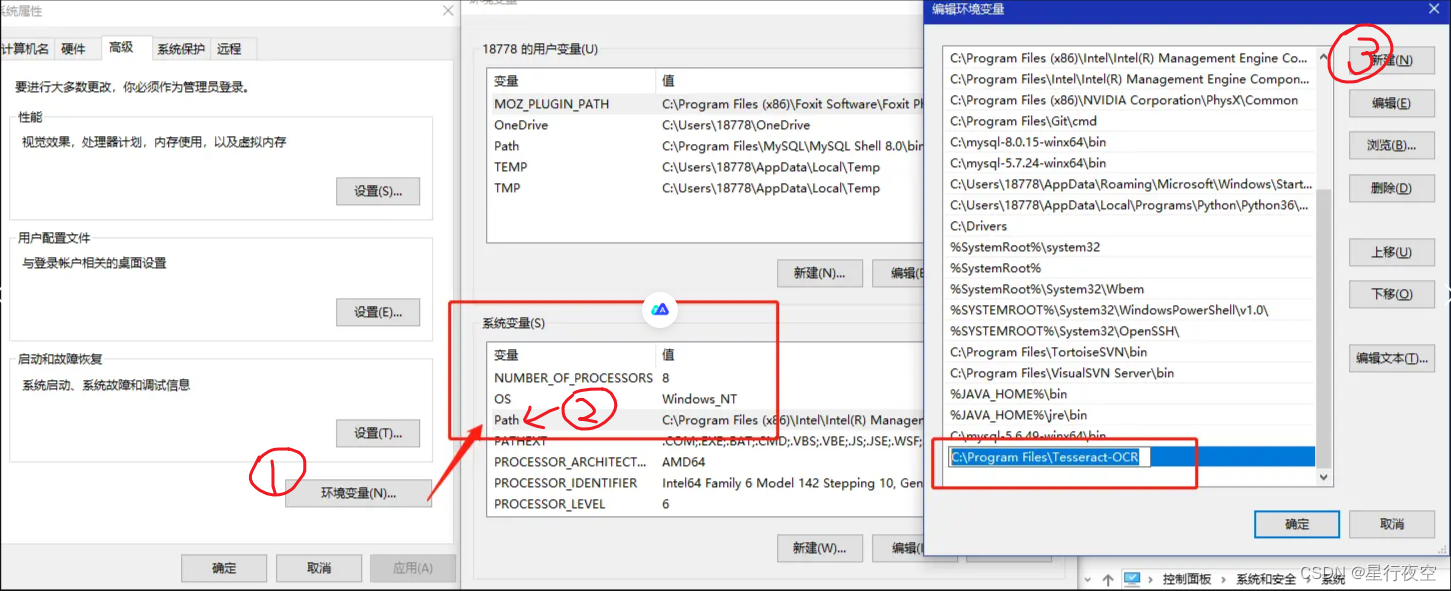
7. 新建一个系统变量
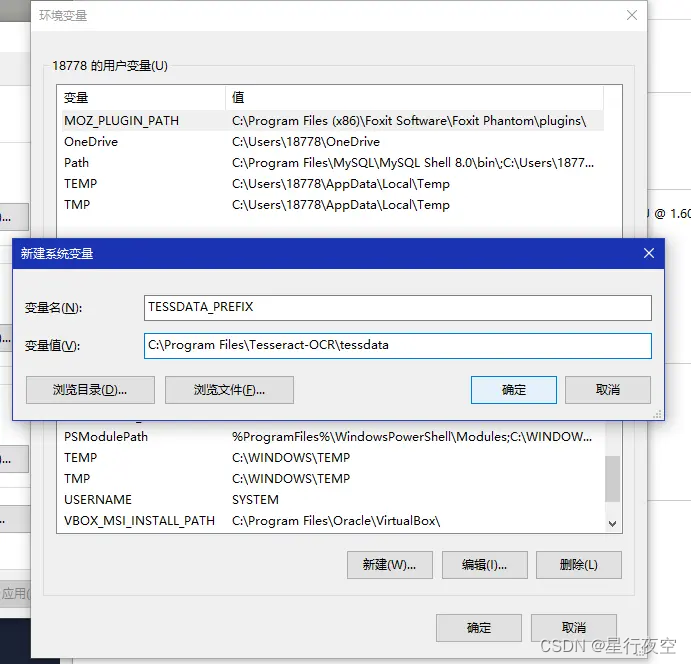
增加一个TESSDATA_PREFIX变量名,变量值还是我的安装路径C:\Program Files\Tesseract-OCR\tessdata这是将语言字库文件夹添加到变量中;
7. 打开终端,输入:tesseract -v,可以看到版本信息

8. 在pytesseract库下的pytesseract.py文件中(刚刚打开过),找到
tesseract_cmd = 'tesseract',
修改成
tesseract_cmd = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1846
1846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









