




SuperCLUE推理榜惊现黑马:原来中兴是一家AI公司?
一家信息通信公司,居然拿到了 AI 推理竞赛的冠军,这事儿有点意思。
前段时间,中文大模型测评基准 SuperCLUE 发布了 2025 年 5 月报告。这份报告评估了来自 OpenAI、谷歌、DeepSeek、字节跳动等多家国内外 AI 公司的大模型,并发布了多个榜单。报告显示,虽然海外模型在综合能力上占优,但国内模型在推理任务中表现亮眼,Doubao-1.5-thinking-pro-250415 与星云大模型 NebulaCoder-V6 以推理总分 67.4 并列第一。
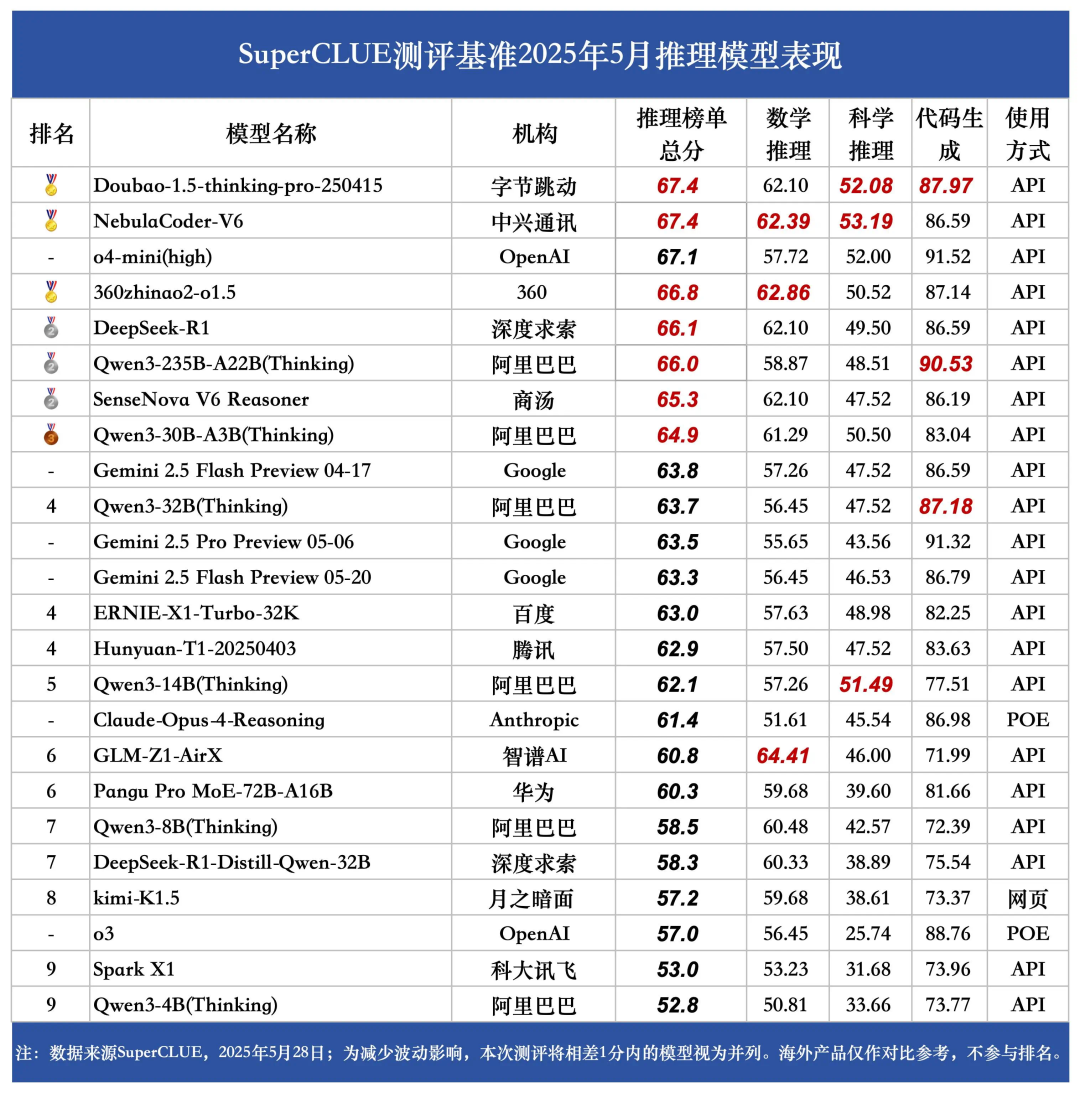
SuperCLUE 推理榜单深度聚焦模型的逻辑思维与问题解决能力,涵盖数学推理、科学推理、代码生成三大硬核维度。
作为专业赛道的选手,Doubao 的表现并不让人意外。但是,星云大模型 NebulaCoder-V6 着实算得上一匹黑马,因为它来自一家老牌信息通信公司 —— 中兴通讯。而且,除了拿下推理榜单第一,它在综合总榜中也表现不俗 —— 与 DeepSeek-R1 并列第二,拿到了银牌。
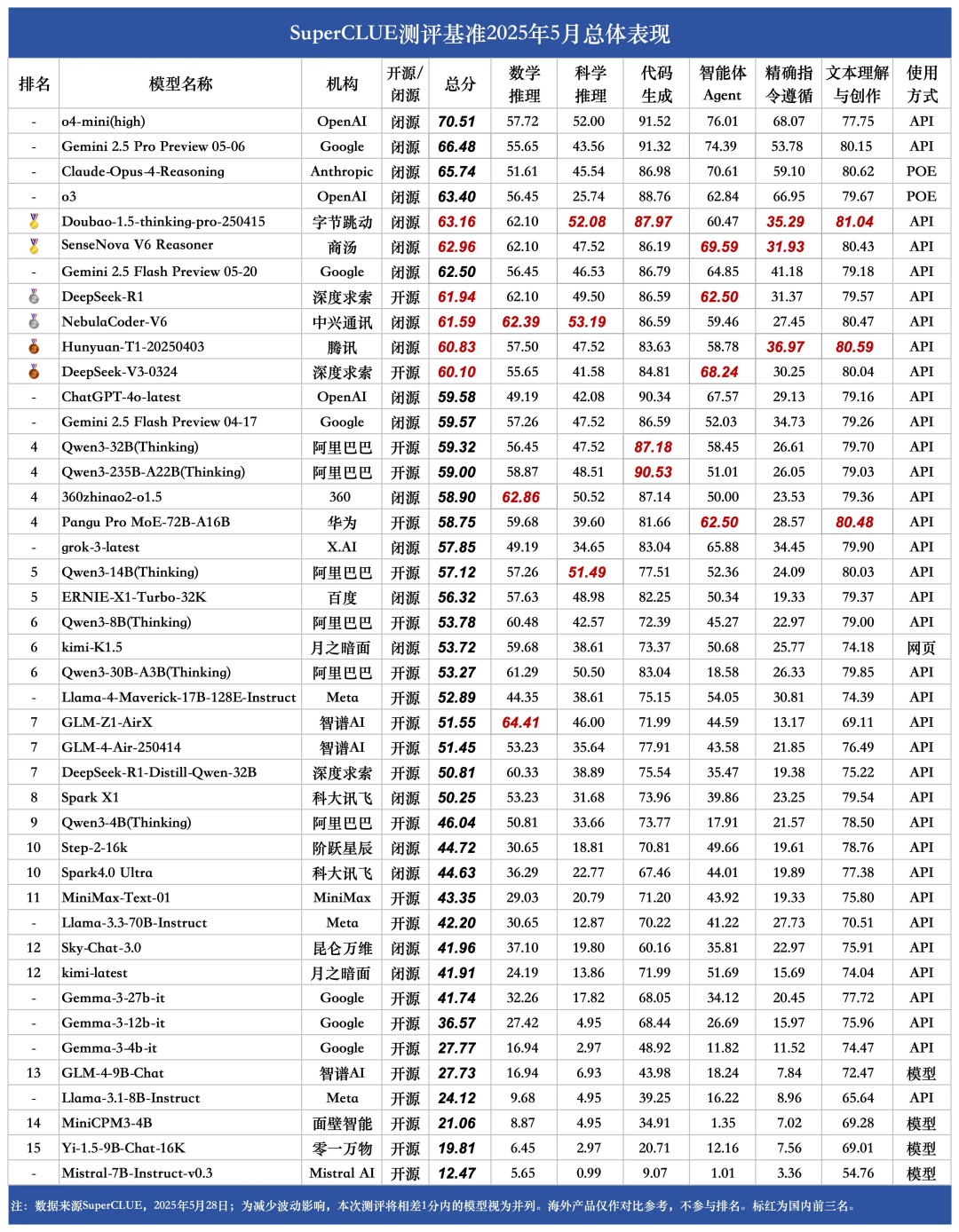
SuperCLUE 推理榜单深度聚焦模型的逻辑思维与问题解决能力,涵盖数学推理、科学推理、代码生成三大硬核维度。
作为专业赛道的选手,Doubao 的表现并不让人意外。但是,星云大模型 NebulaCoder-V6 着实算得上一匹黑马,因为它来自一家老牌信息通信公司 —— 中兴通讯。而且,除了拿下推理榜单第一,它在综合总榜中也表现不俗 —— 与 DeepSeek-R1 并列第二,拿到了银牌。
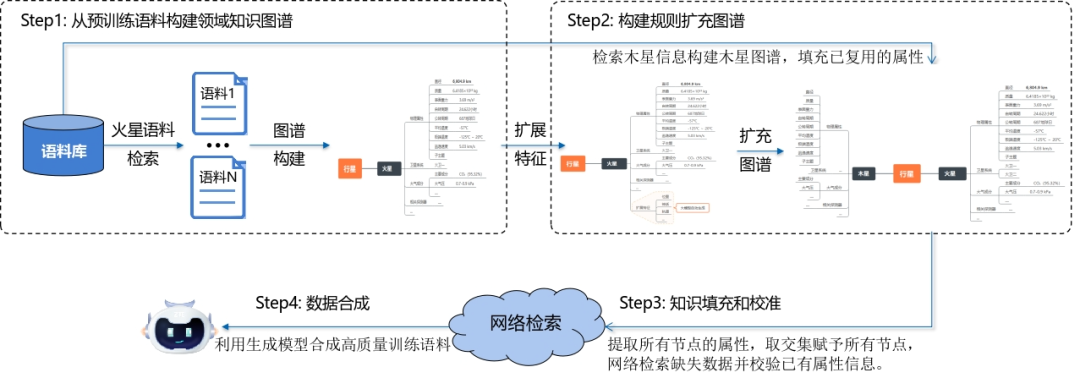
什么叫「领域共享属性」?研究人员举了个例子,假如在现成的预训练语料中,火星的知识非常丰富,但木星的数据残缺不全,用传统的预训练数据直接训练必然会缺失大量的木星知识,从而导致模型幻觉。DASER 的创新之处在于使用了同一领域内知识的共享规律 —— 比如行星都具有公转周期、自转周期等共同属性。因此在构建木星知识图谱时,它会根据之前所识别到的行星公共属性去自动填充可复用的属性,并通过网络检索进行缺失数据填充。
借助这一方法,星云大模型团队构建了覆盖国家基础学科分类体系的全学科知识图谱。模型训练效率、推理准确性均显著提升,在中兴构建的高难度私域知识类 QA Bench 上,准确率指标由 61.93% 增长至 66.48%。
监督微调:批判学习 + 数据飞轮,让模型理解复杂指令
监督微调(SFT)阶段的目的是将预训练模型拥有的通用潜力转化为特定领域的专业能力,让模型理解并执行复杂指令,这个过程类似于人类的高等教育或职业培训。
研究人员介绍说,这一阶段的数据通常有两类:第一类是标准的 QA「问题 - 正确答案」对,用于直接训练模型模仿正确响应;第二类是思维链数据,即在答案中显式包含推理步骤,引导模型分步解决问题。
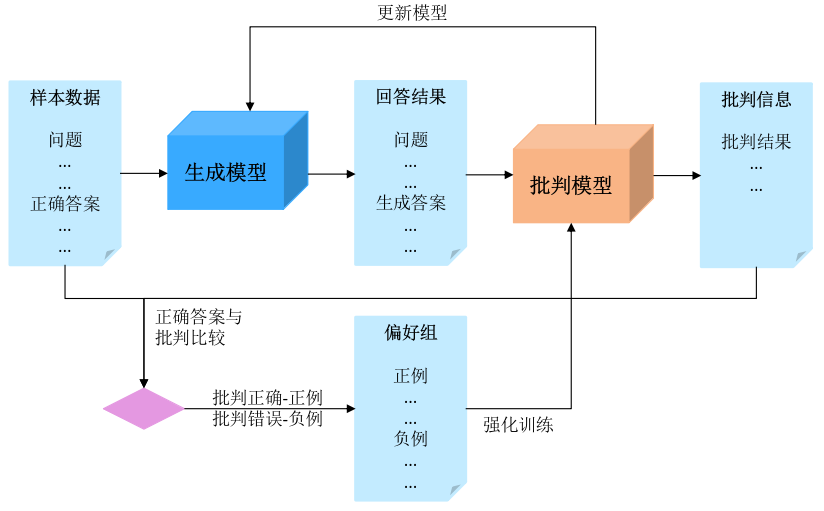
更进一步,还可以使用批判学习(Critique Learning, CL)基于难样本生成特定形式的思维链数据,让模型对错误答案进行批判并验证,从而构建一个持续优化模型推理与批判能力的「批判 - 推理」数据飞轮。
在训练模型的过程中,他们发现批判学习数据效果更为显著。其原理在于:模型如同人脑,对「异常」(如错误答案)高度敏感。发现错误并提出批判的过程,比单纯接受标准答案更能深化模型的理解。
因此,研究人员在 SFT 中引入了批判学习(CL)及成对批判学习(PCL)算法。PCL 的关键流程是:
-
针对困难样本,模型给出初始(错误)回答。
-
模型对错误回答进行批判。
-
基于批判信息,模型生成修正后的回答。
-
利用规则方法验证最终答案的正确性。
上述流程将产生 {任务描述,错误回答,批判信息,正确回答} 的四元组训练样本。进一步的,他们发现在模型训练中使用从四元组中抽取 {任务描述,错误回答,批判信息} 三元组,而非直接使用四元组,训练效果会更好。
相较于使用纯思维链类数据的 SFT,引入额外 CL/PCL 数据的批判 CFT(Critique Fine-Turing)方法在数学、代码等多项推理中准确率明显上升。


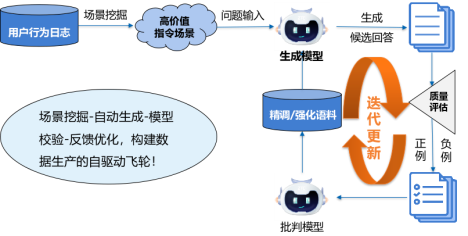
 除此之外,为了让模型在遇到用户复杂指令时也能准确理解并执行。需要让模型看到更多高质量指令数据。为了得到这些数据,他们构造了一个数据飞轮。如下图所示,整个飞轮分为四个模块,其中很多工作可以借助模型来自动完成,比如场景挖掘、候选答案生成。在其中一个关键模块 —— 模型校验中,他们也用到了批判学习。他们借助这种方式获得的数据反哺训练集,迭代地帮模型提高意图理解能力。
除此之外,为了让模型在遇到用户复杂指令时也能准确理解并执行。需要让模型看到更多高质量指令数据。为了得到这些数据,他们构造了一个数据飞轮。如下图所示,整个飞轮分为四个模块,其中很多工作可以借助模型来自动完成,比如场景挖掘、候选答案生成。在其中一个关键模块 —— 模型校验中,他们也用到了批判学习。他们借助这种方式获得的数据反哺训练集,迭代地帮模型提高意图理解能力。
强化学习:双阶段强化学习,提升回答精度与严谨度
强化学习阶段的目的是通过环境反馈(奖励信号)进一步优化模型的行为策略,使其能够解决更复杂的现实世界问题,类似于人类的职场实战。
在这一阶段,星云大模型团队主要关心两个问题:如何提高大模型解决复杂问题的准确率和逻辑严谨性。
为此,他们提出了双阶段强化学习,即「先整体纠错→再局部精修」。
在纠错阶段,他们引入了「批判性强化学习(CRL)」,选取 STEM 领域的高难度问题进行专项训练,迭代提升模型回答高难度问题的准确度。
在精修阶段,研究人员发现使用强化学习会导致回答多样性下降。拿代码生成举例,模型可能有多种正确的实现方式, 如果某一种方式因为细微的错误被视为负样本,模型可能会「误以为」这种方法本身是错误的,从而在未来避免使用。这会导致模型生成的答案多样性下降,甚至在海量强化数据优化后无法提供解决方案,从能力「涌现」到能力「崩塌」。
为了解决这个问题,他们首先在数据层面,将模型回答错误的样本,通过一个离线的拒绝采样过程,获取「最小修改」纠错样本。再改进传统强化学习算法,单独计算每个 Token 的回报值。这种「更细粒度」的强化学习算法,使模型无论是模型回答还是思维链条都更合理,幻觉明显下降,人类偏好打分提升 13%。
03
从 ICT 到 AI 的无缝切换
当 40 年的 ICT 巨头闯入 AI 战场,等待他们的是「跨界」阵痛,还是无缝切换?答案可能是后者。
这是因为,AI 和 ICT 看似「跨界」,实际有很多相似之处,比如它们的核心都在于数据的处理、交换和存储;都是复杂超大系统的高效协同。
具体来说,ICT 涉及多个网元组成的庞大网络,AI 需要芯片、服务器、存储、交换和数据中心组成高效绿色的基座。这些系统不仅需要达到局部最优,还要放在一起进行全局优化。这要求具备全栈的技术积累、工程实践和系统优化能力,而这恰恰是中兴所擅长的,也是他们在未来重要的战略方向 ——「智算」中所要强化的。
除此之外,在 AI 这个方向上,中兴也有自己独特的优势。
我们知道,AI 的发展是一个跨多学科的复杂工程科学,它的创新进程离不开大量工程实践经验,比如参数调优、算子融合、算法优化…… 其涉及领域之广,技术门槛之高已经让一些早期入局的企业感觉吃力。
而从中兴身上,我们能够看到一些走 AI 长期路线的潜质。具体来说,和芯片厂家相比,他们有整体的系统工程能力;和做通算的纯 IT 类厂家相比,他们的组网能力更强;和纯做大模型的厂家相比,他们的硬件能力又更强。所以综合来看,中兴其实更容易拉起整个产业链,无论是硬件开发、软件平台、大模型还是行业应用,他们在原来的领域都已经有所涉及。
而且,中兴也有巨大的产品生态支撑,这些产品目前正在「AI 化」。如果未来全部 AI 化,市场空间巨大,也能让技术在丰富的场景中快速迭代,形成数据反哺。
当传统 ICT 巨头全力拥抱 AI,这场转型会给行业带来怎样的化学反应?答案或许就在中兴接下来的每一步里。
推荐活动
即将于8月8-9日举办的,第七届 AiDD峰会(北京)上邀请了中兴内部几位AI专家现身峰会宣讲。感兴趣的同学,欢迎大家报名参会,与近百位AI行业大咖共同探索AI新纪元!


















 3292
3292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









