






近年来,以DeepSeek、Llama、Qwen、Mixtral为代表的新一代大模型不断突破参数规模瓶颈,推动模型体量向万亿级跃进,流水线并行(Pipeline Parallelism)已演变为大模型分布式训练的必备技术之一。
流水线并行通过将模型的不同层放置于不同的计算设备,降低单个计算设备的内存(显存,后文统一称为内存)消耗,从而实现超大规模模型训练。相较于张量并行中大量的All-Gather等通信,流水线带来的通信代价是每个stage之间的P2P通信,通信总量相对来说较小。
然而,流水线并行的特点决定了流水线的不同stage之间必然存在着依赖计算关系,这种依赖关系会产生额外等待时间(又叫做“空泡”或“bubble”),制约着模型的训练性能。为了尽量压缩bubble,提升训练性能,业界提出了如GPipe、PipeDream和Megatron-LM等当前应用广泛的几种流水线编排技术。
这些技术在拉高了训练效率的上限的同时也引入了不同设备上内存开销的不均衡,增大了策略调优的难度和成本,流水线并行策略的配置成为了影响大模型端到端性能的核心因素之一。
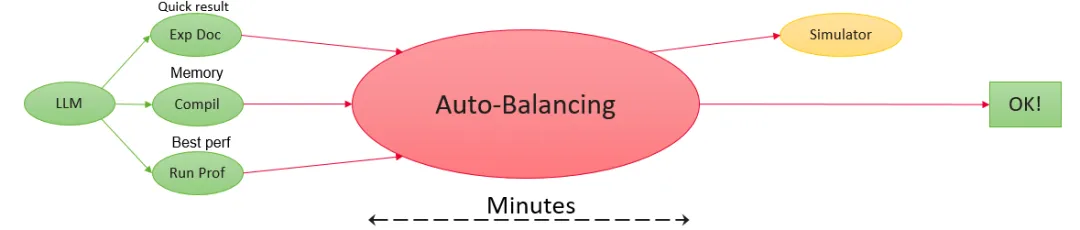
洞察到这个挑战,昇思MindSpore团队提出了一种同时均衡计算和内存的全局求解方法,面向复杂的流水线编排逻辑,自动生成最优的stage-layer分配和重计算策略。研发人员将算法打包成为自动流水负载均衡工具,结合Dryrun集群内存仿真工具,实现低成本高效模型调优:
-
自动流水负载均衡工具是基于符号抽象的全局线性规划算法,实现同时均衡计算和内存的负载。通过对模型的性能和内存进行分解,构建出线性规划问题,在分钟级的时间内求解出一个最优的layer分配和重计算策略,大幅度提升模型调优的效率。
-
Dryrun是模拟集群实际执行训练任务的工具,可以在单卡上完美模拟AI框架的构图、编译、内存分配的过程,其输出的内存预估和真实执行之间的误差极小,从而实现单卡仿真大集群并行策略的调优,降低调优资源消耗、提升调优效率。
MindSpore TransFormers Pipeline_balance地址:
https://gitee.com/mindspore/mindformers/tree/dev/toolkit/pipeline_balance
通过结合昇思MindSpore提供的自动流水负载均衡工具与Dryrun集群内存仿真工具,在大集群上实测DeepSeek-V3 671B调优,实现训练性能倍增;实测千亿参数Llama模型自动负载均衡调优相比于专家调优提升性能14%。
# 01
超大集群调优案例
一
DeepSeek-V3 671B调优案例
DeepSeek的架构中不同的MoE层专家数存在着区别,并且还引入了MTP层,这让Deepseek模型的不同层之间内存和计算建模有着显著差异。手工调优需要工程师多次实验总结不同层处在不同stage时的内存变化规律,相比于Llama系列模型复杂度和工作量都是成倍提升。
面对DeepSeek一类的异构模型,流水负载均衡工具可以有效兼容。表3展示了DeepSeek-V3 671B 大集群调优的实例。
当模型参数量来到了671B这样的规模,即使配置pp=16,将模型的layer平均切分到每个stage时,设备内存压力仍然较大,因此只能选择开启完全重计算。表中图示展示了流水执行的模拟示意,蓝色方框为正向计算,黄色为反向计算,纵轴表示16个stage,横轴表示时间,下面的红色real bubble代表bubble相比于真实计算时间的比值,real bubble越大,预估性能越差。
在平均切分全重计算的情况下,可以观察到stage0上每层的计算时间相比于stage1-15较小,这是因为Dense层的计算时间小于MoE层;另外stage16的每个小方框较大,是因为MTP层的计算时间较大。从图中观察1F1B的流水执行中,可以看到瓶颈是stage16的正反向时间,其余的stage不得不等待stage16的计算结束,因此可以看出在stable阶段产生了不小的bubble,而在cooldown阶段,因为前面stage的反向已经结束,产生了非常明显的巨大的bubble,最终real bubble值为1.45,很明显该平均切分策略性能较差。
对于DeepSeek-V3 671B使用自动流水负载均衡工具,妥善配置了每个stage的layer数和重计算策略,流水线各stage上的计算、内存负载基本均衡。从第二张图可以看出最后一个stage的计算量变小,是通过挪动部分layer到其他stage来调整的。通过解决瓶颈stage的计算问题,stable阶段的bubble被基本消除,cooldown阶段的bubble也大幅度降低,最终real bubble降为0.91,大幅提高了训练效率。
在大集群实测训练性能相比开箱性能提升一倍以上。
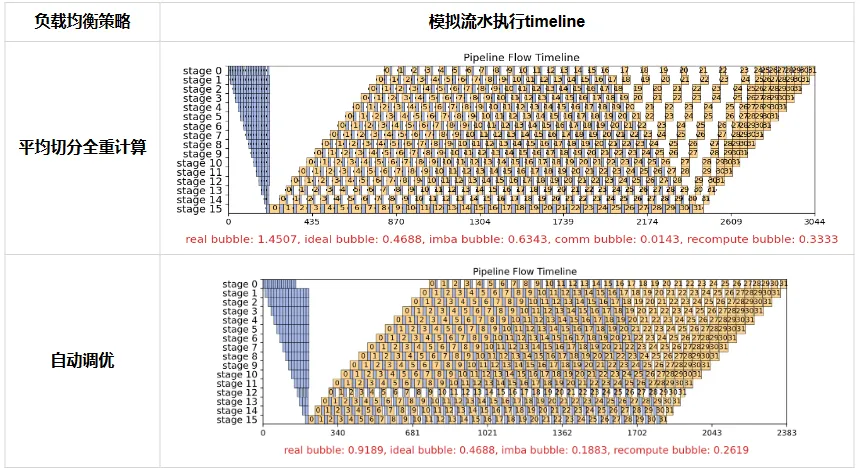
图1 DeepSeek-V3 671B 大集群调优
二
千亿参数Llama模型
大模型训练中为了保障训练的效果(loss的收敛和最终的评测效果),通常会控制global batch size不能太大。在限定global batch size的情况下,流水并行的micro size数也受到了限制,尤其是在大集群训练时,数据并行dp的维度数非常大。根据bubble计算公式(p-1)/m,当m过小时,bubble相对较大,设备空等时间较多,影响训练性能。针对interleave场景的调优难题,自动负载工具做到了对内存排布和计算时间的建模,用户可以任意给定chunk数,工具将给出此条件下的最优解。同时工具自带模拟器,方便用户对比各种不同的并行策略。
下图通过流水并行模拟器展示了超大集群的千亿参数Llama模型训练的调优实例。
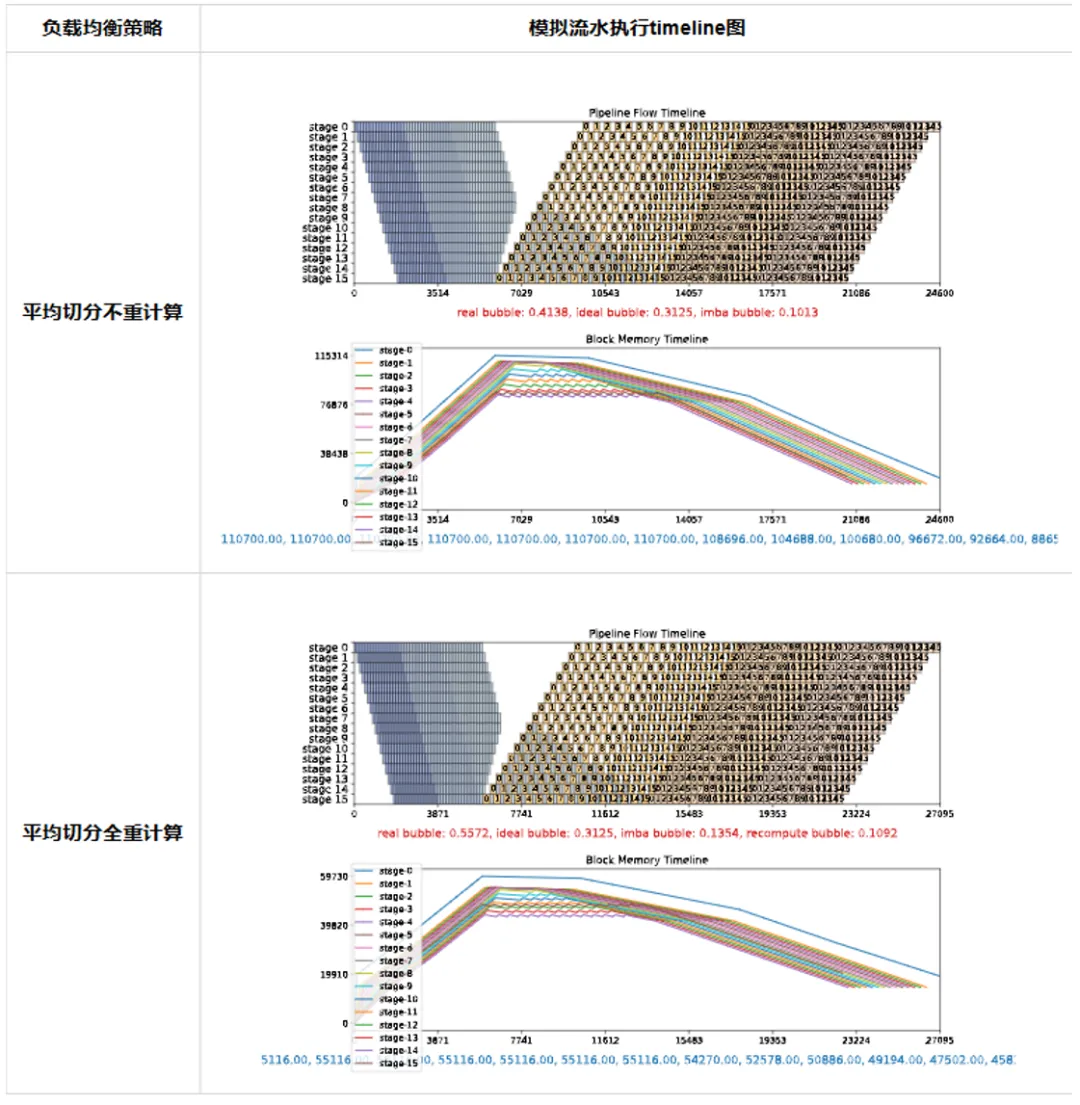
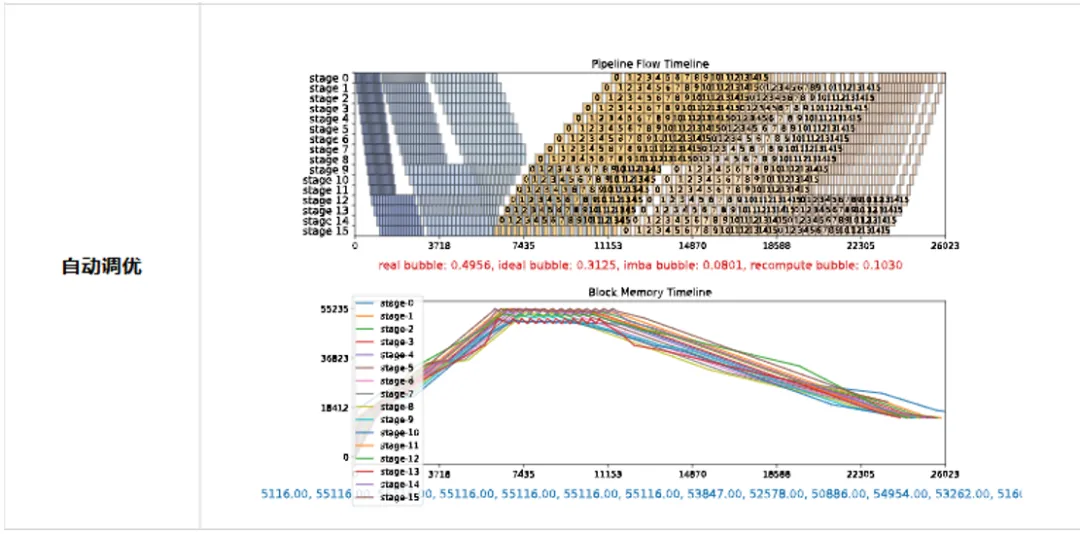
图2 超大集群千亿参数规模Llama调优
图2中共有三种流水线负载均衡配置,分别是对layer进行平均切分,且不开启重计算;平均切分开启全部重计算以及经过自动负载均衡调优后的策略。
最终通过超大集群实测,自动负载均衡调优相比于专家调优提升性能14%。
# 02
技术背景和挑战
一
流水线并行的典型编排方式
图1展示了最简单的流水并行切分,将模型的层进行了切分,分布在不同的设备上,虽然节省了内存占用,但是可以很明显的看到非常大的bubble,在实际训练时性能会非常差,因此在实际训练中基本上不会直接使用native pipeline。谷歌为了提高流水线的效率,提出了Gpipe,如图2所示,设备上的训练数据被分成了更细的micro batch,不同的micro batch可以并行计算,这样就压缩了训练过程中的bubble,提升了训练性能。
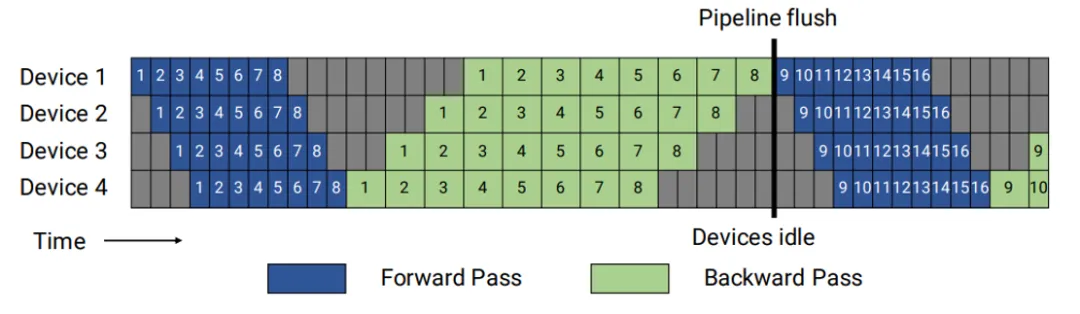
图4 GPipe
在这种范式下,每个device上的内存压力是一样的,都需要在反向之前存储一个step中所有layer的激活值(activation/Acti.)。因此,GPipe虽然通过流水线的方式把模型分割到了不同的设备上,但其所采取的流水线编排方式在调大micro batch时,内存占用过高,影响了其扩展性。因为通常来说,micro batch越大,可以流水并行的计算部分越多,bubble越小。
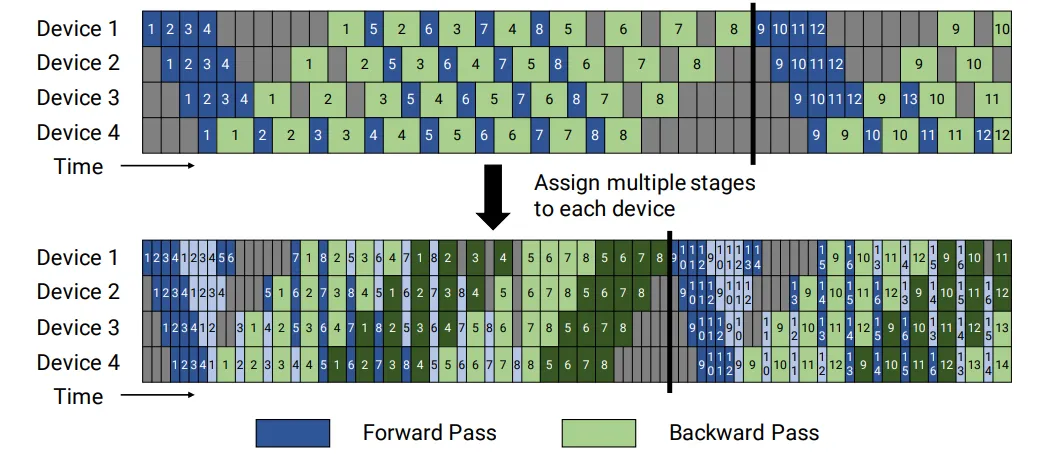
图5 1F1B & interleaved pipeline
PipeDream在GPipe batch-forward-batch-backward的编排基础上提出了一种新的编排方式,1-forward-1-backward(1F1B)(图5上半部分),流水线在一个前向处理完成后便可以开始计算反向,这样激活值在反向执行后就可以及时释放,相比于Gpipe提高了内存使用效率,增加micro batch的数量不再会对设备上的峰值内存有影响。在这种1F1B的编排方式之下,流水线的最小bubble为(p-1)/m,p和m分别是流水线stage数和micro batch数。性能持平GPipe的同时进一步节省了内存压力。以下表为例,当micro batch数量为8的时候,stage = 4的流水线并行最少也能为设备节省50%的内存。
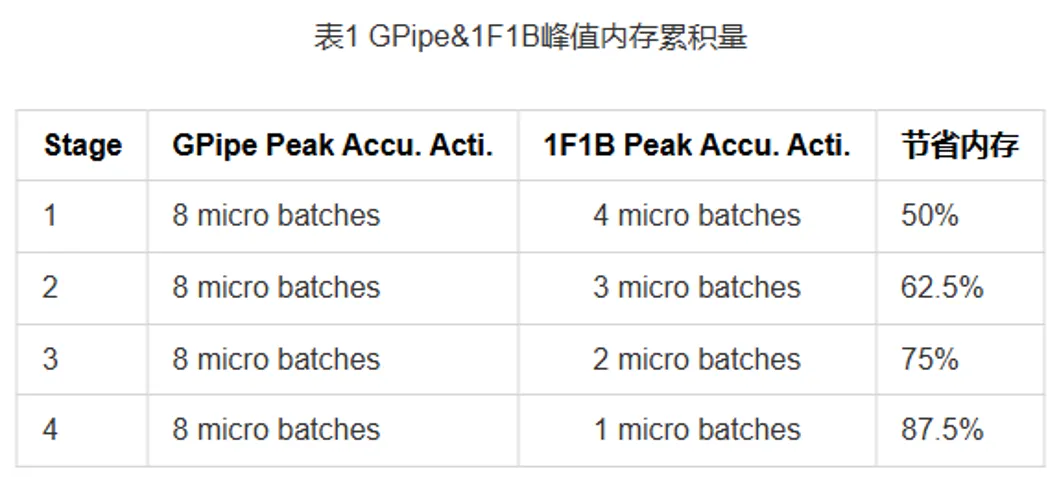
因为在峰值内存方面的优势,业界的流水线并行普遍采用了1F1B的编排方式。经过深入分析可以发现,1F1B编排模式下,设备的内存压力相比于GPipe而言减少了很多,然而流水线中每个stage的内存压力是不平衡的(见上表最右列)。每个设备上的峰值内存由进入稳定状态之前1F1B累积的激活值决定,第i个stage累计的激活值带来的内存开销可以通过公式计算,计算结果显示在流水线中靠前的设备(即i数值较小的)峰值内存更高。
Megatron团队在2021年提出了流水线交织(interleaved pipeline)的排布方式(图5下半部分),这是一种基于1F1B的优化,通过把一个设备上原本连续的layer继续分割成多个chunk,进一步细化了流水线的颗粒度,进一步压缩bubble到(p-1)/vm,v是每个stage切分出的chunk数。当stage = 4时,如果micro batch数为16,理论上1F1B下bubble最小占比为18%,而分出两个chunk之后,bubble的占比极限下可以进一步被压缩到9%左右。不过,流水线交织并不能解决内存不平衡,只是引入了新变量chunk,导致调优又新增了一个维度,复杂度几何级上升。
二
流水线并行调优难点
综上所述,在当前主流的流水线并行技术之下,stage之间内存资源的使用是天然不平衡的,如果模型规模继续增大,需要切分更多的流水线stage数,这种不平衡会更加明显。
流水负载均衡的调优需要找到内存和计算的trade-off,既要让每个设备的内存资源都要得到充分利用,也要让每个设备的计算负载尽量相等。为了达到这一点,调优中至少要考虑以下几个维度:
-
每个stage要分配多少layer;
-
每个stage中有多少的layer需要进行重计算,如果涉及多种重计算,比如完全重计算、选择重计算,则每种都需要单独考虑;
-
如果采取流水线交织的话,则还需考虑每个chunk中layer的分配;
-
当各个stage的内存得到了充分利用之后,能否真的在短板效应的影响下提高端到端的性能。
三
当前的流水线并行策略寻优方式
并行策略对模型整体训练效率的PipeDream和Dapple这些工作中都提出过针对性的策略寻优算法。这些算法实际应用中还是依赖工程师的手工调优,依靠经验和直觉多次迭代调整去发现最好的策略。常常需要花费数天至数周的时间去完成策略的微调,期间还伴随着训练任务的多次拉起。
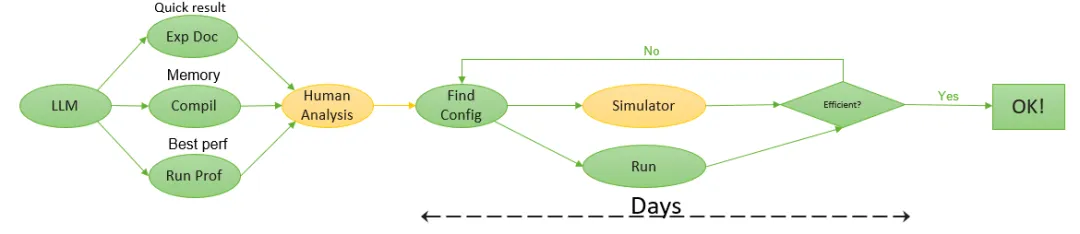
图6 专家手工调优流程
在大多数情况下,人工调优会采取贪心的策略,在1F1B模式且stage数目较少的情形下是可行的。但当stage增多的时候调优难度会逐步提高,尤其是,开启流水线交织后,内存模式会有所不同,且这几个调优维度之间是互相影响的,调优难度指数级增加。
对每个维度独立考虑,最终组合起来并一定是最优解。这就使得贪心的调优策略在很多场景下会无能为力,必须用一种全局的求解思路去寻找最优策略。
面对这个问题,我们提出了基于符号抽象的全局线性规划算法,同时均衡计算和内存的负载。通过对模型的性能和内存进行分解,构建出线性规划问题,在分钟级的时间内求解出一个最优的layer分配和重计算策略,大幅度提升模型调优的效率。
# 03
基于符号代价模型和线性规划的自动负载均衡算法
一
建模与算法
从整体角度来看,主流的大语言模型都是由embedding+多层layer重复+lm_head构成的,我们只需要知道layer层面的性能信息即可。在内存方面,只要有一定的stage内存开销的已知数据,就可以分解出模型的内存构成,完成内存建模。
二
性能模型分解
传统性能模型的求解能力和测量出来的数值精度绑定,需要多次profiling以识别规律,不能很好预估某一次运行的绝对速度。白盒拆解网络关系则可以更好地修正时间信息。在负载均衡的建模中,我们把时间分成head、body和tail。以Llama类型的网络为例,模型的输入经过了embedding之后是重复的decoder,最后以lm_head和loss结束。此时,embedding就是head,而decoder layer是body,tail则是lm_head和loss。这些时间都可以在profiling中找到。如果不考虑流水线并行,那么一个micro batch的前向时间就是head + n × body + tail。同时这种白盒方案也有利于在反向时间中考虑重计算的影响。此外,这种抽象范式也能泛化到Deepseek这种“异构模型”上。在Deepseek中,其decode layer既有dense MoE也有sparse MoE,还会接上一层MTP,不过对于我们的算法来说,这些不同的层抽象之后就变成了不同的body,可以被寻优算法天然兼容。
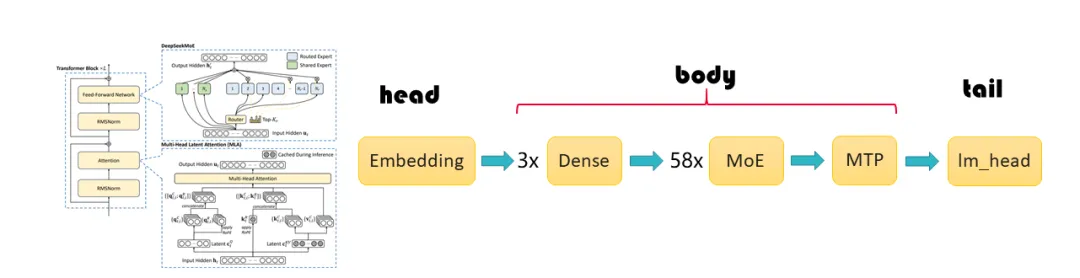
图8 性能模型分解:DeepSeek-V3
三
内存建模
内存的建模是算法中需要谨慎设计的一环。一方面,通过多次拉起的方式去获得内存,这种纯黑盒的方式时间成本过高,违背了工具设计的初衷。另一方面,白盒算法通过计算模型中各个参数和激活值的shape来推演理论内存的方式准确度欠佳:难以全面考虑AI框架、特性优化、内存复用、碎片处理、硬件驱动内存分配器的参与。
Dryrun是MindSpore提供的一种能够模拟实际执行的工具,除了真实的在硬件上执行计算和通信,Dryrun可以完美模拟AI框架的构图、编译、内存分配的过程,其输出的内存预估和真实执行之间的误差非常小。在最终的方案中,我们通过提前进行一次Dryrun获得每个stage的真实内存,再把真实内存通过线性方程组的方式进行分解。由于算法最终的输出是每个stage中的layer分配以及重计算策略,内存可以被分解到layer和重计算的层面上。假设有一个stage数为pp的流水线,每个stage的内存值为M,stage中的layer数为li,重计算层数为ri,i为stage id。内存将被分解为如下几项:

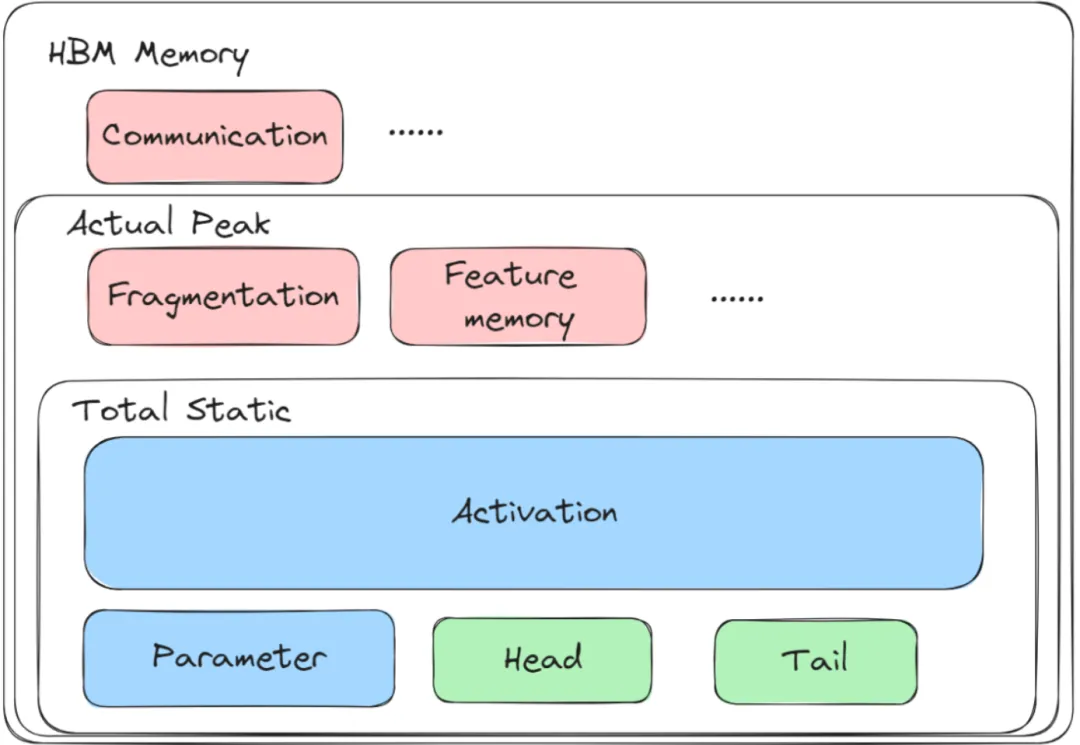
图9 内存建模:DeepSeek-V3
在上文对1F1B的分析中得知,第i个stage由于activation带来的内存开销,根据公式每个stage的峰值内存可表示为:
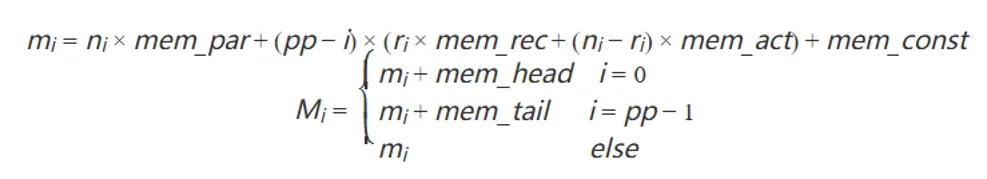
由此,只要通过Dryrun等手段得到足够多的stage峰值内存,就可以通过方程组求解完成对内存的分解。在代码中可以通过numpy方便地实现这一逻辑。

四
线性规划
按照上面两节描述的方式分解出了性能和内存信息之后,通过整数线性规划建模流水线并行的编排模式,就可以衡量不同的配置对性能和内存的影响。以设备的内存作为约束条件,以最小化端到端训练时间为目标,可以自动求出最优的layer分配和重计算策略。这里需要考虑的是如何对端到端时间建模。原封不动地刻画layer间的依赖关系是一种自然的思路,但在复杂的调优条件下这种建模方式的时间复杂度很快就会超出可接受的范围。实际上,如果考虑1F1B自身的性质,就可以简化问题、分组描述,降低复杂度。
如下图,在1F1B编排下,流水线一个step的端到端时间可以分为三个部分,分别为warmup、steady和cooldown。warmup阶段处于反向开始之前,steady阶段处于稳定的前反向交替状态,到了cooldown阶段则已经不再有需要计算前向的micro batch了,只需处理完剩余的反向过程。
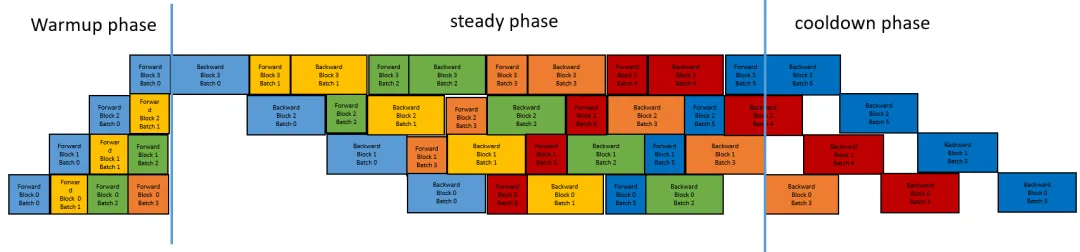
图10 1F1B编排模式
三个部分的时间表示为:

这种建模思路也能够直接复用到interleave的场景下,完成更复杂的负载均衡。基于pulp的代码逻辑表达如下:

当然实际的建模中需要处理很多的细节问题,比如说开启interleave之后不同chunk之间内存不一致带来的扰动等等,只有尽可能考虑到实际运行中的各项影响因素才能准确的做出性能和内存预估。
五
寻优方法逻辑
对于使用者来说,使用自动负载均衡工具需要提供如下的yaml文件。pipeline_config用来描述模型的流水线配置。time_config用于描述时间信息,来源于profiling数据(profiling要知道decoder layer和embedding、lm_head之间的耗时关系)。recofmpute_config和memory_uage是需要的dryrun数据,有了这些信息之后算法会自动构建线性规划问题,利用求解器完成对最佳策略的寻找。
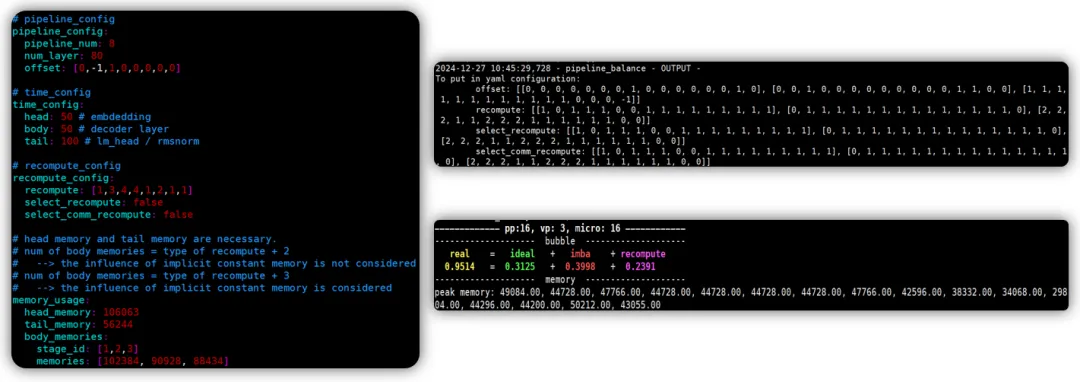
图11 输入输出样例
负载均衡工具的寻优流程如下图所示,yaml文件中包含的时间和内存信息会被工具中的parser模块所分解,构成一套抽象表征提供给算法的interface。求解出来的策略以一种兼容MindSpore TransFormers配置的格式给出并给出这个配置的bubble比例(上图右),这个策略可以直接提供给MindSpore TransFormers使用,同时工具也包含了一个流水线模拟器,会根据算出来的策略模拟出性能和各个stage的内存占用(下图右下角)。
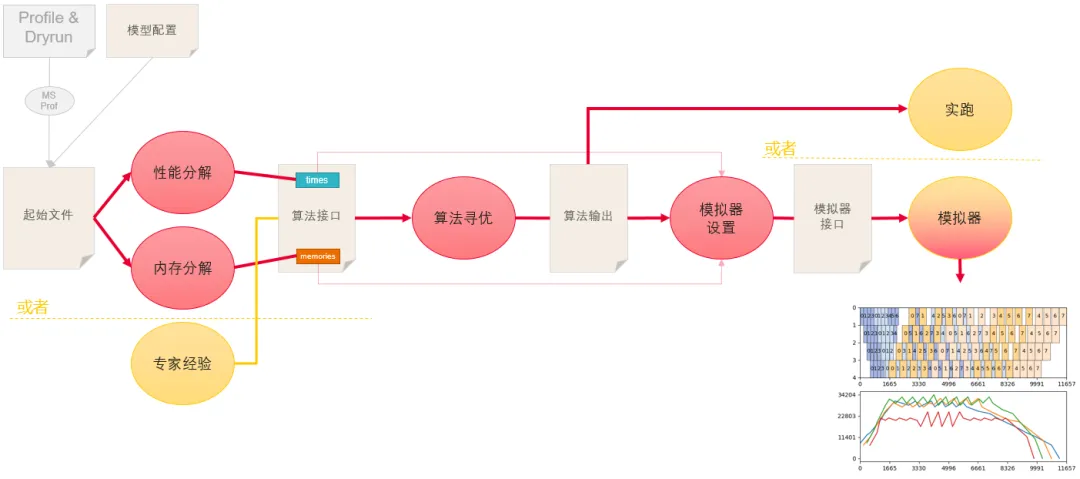
图12 负载均衡工具寻优流程

















 785
785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









