



【KNN算法】
1、概述
(K Nearest Neighbor,简称KNN)可解决分类问题和回归问题。
思想:
如果一个样本在特征空间中的 k 个最相似的样本中的大多数属于某一个类别,则该样本也属于这个类别。
什么是相似性?
样本都是属于一个任务数据集的。样本
距离越近则越相似。默认的样本距离计算方式为欧氏距离。
2、KNN算法
算法流程:
-
分类问题:
①计算未知样本到每一个训练样本的距离
②将训练样本根据距离大小升序排列
③取出距离最近的 K 个训练样本
④进行多数表决,统计 K 个样本中哪个类别的样本个数最多
⑤将未知的样本归属到出现次数最多的类别 -
回归问题:
①计算未知样本到每一个训练样本的距离
②将训练样本根据距离大小升序排列
③取出距离最近的 K 个训练样本
④把这个 K 个样本的目标值计算其平均值
⑤作为将未知的样本预测的值
KNN的K值选择:
K值就是设置最相邻点的个数,通过交叉验证、网格筛选寻找合适的K值
- K值过小
容易受到异常点的影响,容易发生过拟合 - K值过大
受到样本均衡的问题,且K值的增大就意味着整体的模型变得简单,欠拟合
API
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5)
sklearn.neighbors.KNeighborsRegressor(n_neighbors=5)
fit()
predict()
from sklearn.neighbors import KNeighborsClassifier
from sklearn.neighbors import KNeighborsRegressor
x_train = [[1],[2],[3],[4],[11]]
y_train = [0,0,1,1,2]
knnClass_model = KNeighborsClassifier(n_neighbors=3, weights='distance', metric='minkowski')
knnReg_model = KNeighborsRegressor(n_neighbors=2)
knnClass_model.fit(x_train,y_train)
knnReg_model.fit(x_train, y_train)
y_test = [[10]]
res = knnClass_model.predict(y_test)
res = knnClass_model.predict_proba(y_test)
print(res)
res2 = knnReg_model.predict(y_test)
# res2 = knnReg_model.predict_proba(y_test)
print(res2)
常用的距离计算公式:
-
欧氏距离
两个点在空间中的距离一般都是指欧氏距离
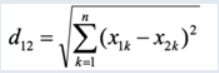
-
曼哈顿距离
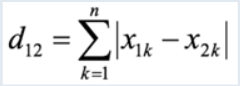
-
切比雪夫距离
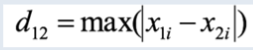
-
闵可夫斯基距离

是对多个距离度量公式的概括性的表述
其中p是一个变参数:
当 p=1 时,就是曼哈顿距离;
当 p=2 时,就是欧氏距离;
当 p→∞ 时,就是切比雪夫距离
数据集分割API:
train_test_split(x,y,test_size,random_state)
3、归一化、标准化
原因:
特征的单位或者大小相差较大,或者某特征的方差相比其他的特征要大出几个数量级,容易影响(支配)目标结果,使得一些模型(算法)无法学习到其它的特征。
归一化:
通过对原始数据进行变换把数据映射到【mi,mx】(默认为[0,1])之间。
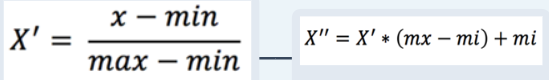
API
- sklearn.preprocessing.MinMaxScaler (feature_range=(0,1)… )
- fit_transform(X) 将特征进行归一化缩放
最大值与最小值非常容易受异常点影响, 鲁棒性较差,只适合传统精确小数据场景
标准化:
通过对原始数据进行标准化,转换为均值为0标准差为1的标准正态分布的数据

适合现代嘈杂大数据场景
API
1.sklearn.preprocessing. StandardScaler()
2. fit_transform(X) 将特征进行归一化缩放
4、交叉验证、网格搜索
交叉验证
是一种数据集的分割方法,将数据集划分为 n 份,拿一份做验证集(测试集)、其他n-1份做训练集 ;使用训练集+验证集多次评估模型,取平均值做交叉验证为模型得分,再使用训练数据集对得分最好的模型训练一遍,测试数据集对模型评估。
网格搜索
网格搜索是寻找最优超参数的工具;只需要将若干参数传递给网格搜索对象,它自动帮我们完成不同超参数的组合、模型训练、模型评估,最终返回一组最优的超参数。
API
sklearn.model_selection.GridSearchCV(estimator, param_grid=None, cv=None)
5、手写字识别案例
from collections import Counter
import joblib
import pandas as pd
from sklearn.metrics import accuracy_score
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
def train_model():
# 获取数据
write_num = pd.read_csv(
r'.\data\手写数字识别.csv')
# print(write_num)
# 数据划分 并归一化
x = write_num.iloc[:, 1:] / 255
y = write_num.iloc[:, 0]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=0, stratify=y)
# 模型训练
knn_model = KNeighborsClassifier(n_neighbors=3)
knn_model.fit(x_train.values, y_train.values)
# 模型评估
y_pred = knn_model.predict(x_test.values)
score = accuracy_score(y_test.values, y_pred)
print(f"模型分数:{score}")
# 6 模型保存
joblib.dump(knn_model, './model/knn.pth')
return knn_model
def test(model):
test_img = plt.imread(r'.\data\demo.png')
plt.imshow(test_img.reshape(28, 28))
plt.axis('off')
plt.imshow(test_img, cmap='gray')
plt.show()
# print(test_img)
# print("-----------------------------------------")
y_pred = model.predict(test_img.reshape(1,-1))
# print(test_img)
# print("-----------------------------------------")
print(f'预测的数字是:{y_pred}')
model2 = joblib.load('./model/knn.pth')
# print(model)
# print(model2)
def show_digit(idx):
data = pd.read_csv(r'.\data\手写数字识别.csv')
if idx < 0 or idx > len(data)-1:
return
x = data.iloc[:, 1:]
y = data.iloc[:, 0]
print(x.shape)
print(Counter(y))
print(y[idx])
data_ = x.iloc[idx].values
data_ = data_.reshape(28, 28)
plt.axis('off')
plt.imshow(data_, cmap='gray')
plt.show()
if __name__ == '__main__':
model = train_model()
test(model)
# show_digit(5)
解决UserWarning: X does not have valid feature names, but KNeighborsClassifier was fitted without feature names问题
原因:
主要原因是data是一个带有特征名称(feature names)的DataFrame,由于带有名称,模型在拟合和预测的时候只需要输入数值,因此才会报这个错误。
解决办法:
使用DataFrame.values
# 模型训练
knn_model = KNeighborsClassifier(n_neighbors=3)
knn_model.fit(x_train.values, y_train.values)
# 模型评估
y_pred = knn_model.predict(x_test.values)
score = accuracy_score(y_test.values, y_pred)
print(f"模型分数:{score}")
解决AttributeError: 'FigureCanvasInterAgg' object has no attribute 'tostring_rgb'. Did you mean: 'tostring_argb'?问题
导包方式做如下变换:
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt

















 5640
5640

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









