



1、Series对象
Series也是Pandas中的最基本的数据结构对象;是DataFrame的列对象或者行对象,series本身也具有行索引。
Series是一种类似于一维数组的对象,由下面三个部分组成:
- values:一组数据(numpy.ndarray类型)
- index:相关的数据行索引标签;如果没有为数据指定索引,于是会自动创建一个0到N-1(N为数据的长度)的整数型索引。
- name: 列标签
-
创建方式
-
自动生成索引
-
指定索引
-
2、创建DataFrame对象
-
概述
- DataFrame是一个表格型的结构化数据结构,它含有一组或多组有序的列(Series),每列可以是不同的值类型(数值、字符串、布尔值等)。
- DataFrame是Pandas中的最基本的数据结构对象,简称df;可以认为df就是一个二维数据表,这个表有行有列有索引
- DataFrame是Pandas中最基本的数据结构,Series的许多属性和方法在DataFrame中也一样适用.
-
创建方式
-
字典方式创建
传入一个字典的键值对方式;
-
列表+列表方式创建
a=[[1,2,3,4],[5,6,7,8]]#包含两个不同的子列表[1,2,3,4]和[5,6,7,8] data=DataFrame(a)#这时候是以行为标准写入的
-
3、Series的常用属性
-
常见属性
属性 说明 loc 使用索引值取子集 iloc 使用索引位置取子集 dtype或dtypes Series内容的类型 T Series的转置矩阵 shape 数据的维数 size Series中元素的数量 values Series的值 index Series的索引值
4、Series的常用方法
-
常见方法
方法 说明 append 连接两个或多个Series corr 计算与另一个Series的相关系数 cov 计算与另一个Series的协方差 describe 计算常见统计量 drop_duplicates 返回去重之后的Series equals 判断两个Series是否相同 get_values 获取Series的值,作用与values属性相同 hist 绘制直方图 isin Series中是否包含某些值 min 返回最小值 max 返回最大值 mean 返回算术平均值 median 返回中位数 mode 返回众数 quantile 返回指定位置的分位数 replace 用指定值代替Series中的值 sample 返回Series的随机采样值 sort_values 对值进行排序 to_frame 把Series转换为DataFrame unique 去重返回数组 value_counts 统计不同值数量 keys 获取索引值 head 查看前5个值 tail 查看后5个值
5、Series的布尔索引
从
scientists.csv数据集中,列出大于Age列的平均值的具体值,具体步骤如下:
-
加载并观察数据集
import pandas as pd df = pd.read_csv('data/scientists.csv') print(df) # print(df.head()) # 输出结果如下 Name Born Died Age Occupation 0 Rosaline Franklin 1920-07-25 1958-04-16 37 Chemist 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 3 Marie Curie 1867-11-07 1934-07-04 66 Chemist 4 Rachel Carson 1907-05-27 1964-04-14 56 Biologist 5 John Snow 1813-03-15 1858-06-16 45 Physician 6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist 7 Johann Gauss 1777-04-30 1855-02-23 77 Mathematicia # 演示下, 如何通过布尔值获取元素. bool_values = [False, True, True, False, False, False, True, False] df[bool_values] # 输出结果如下 Name Born Died Age Occupation 1 William Gosset 1876-06-13 1937-10-16 61 Statistician 2 Florence Nightingale 1820-05-12 1910-08-13 90 Nurse 6 Alan Turing 1912-06-23 1954-06-07 41 Computer Scientist -
计算
Age列的平均值
mean_num = df['age'].mean()
- 输出大于
Age列的平均值的具体值
df[df['age'] > mean_num]
6、Series的运算
Series和数值型变量计算时,变量会与Series中的每个元素逐一进行计算;
两个Series之间计算时,索引值相同的元素之间会进行计算;索引值不同的元素的计算结果会用NaN值(缺失值)填充。
- Series和数值型变量计算
series * 100
- 两个Series之间计算时,索引值相同的元素之间会进行计算;索引值不同的元素的计算结果会用NaN值(缺失值)填充
7、DataFrame常用属性和方法
-
基础演示
import pandas as pd # 加载数据集, 得到df对象 df = pd.read_csv('data/scientists.csv') print('=============== 常用属性 ===============') # 查看维度, 返回元组类型 -> (行数, 列数), 元素个数代表维度数 print(df.shape) # 查看数据值个数, 行数*列数, NaN值也算 print(df.size) # 查看数据值, 返回numpy的ndarray类型 print(df.values) # 查看维度数 print(df.ndim) # 返回列名和列数据类型 print(df.dtypes) # 查看索引值, 返回索引值对象 print(df.index) # 查看列名, 返回列名对象 print(df.columns) print('=============== 常用方法 ===============') # 查看前5行数据 print(df.head()) # 查看后5行数据 print(df.tail()) # 查看df的基本信息 df.info() # 查看df对象中所有数值列的描述统计信息 print(df.describe()) # 查看df对象中所有非数值列的描述统计信息 # exclude:不包含指定类型列 print(df.describe(exclude=['int', 'float'])) # 查看df对象中所有列的描述统计信息 # include:包含指定类型列, all代表所有类型 print(df.describe(include='all')) # 查看df的行数 print(len(df)) # 查看df各列的最小值 print(df.min()) # 查看df各列的非空值个数 print(df.count()) -
DataFrame的布尔索引
# 小案例, 同上, 主演脸书点赞量 > 主演脸书平均点赞量的 movie[movie['actor_1_facebook_likes'] > movie['actor_1_facebook_likes'].mean()] # df也支持索引操作 movie.head()[[True, True, False, True, False]] -
DataFrame的计算
scientists * 2 # 每个元素, 分别和数值运算 scientists + scientists # 根据索引进行对应运算 scientists + scientists[:4] # 根据索引进行对应运算, 索引不匹配, 返回NAN
8、DataFrame-索引操作
Pandas中99%关于DF和Series调整的API, 都会默认在副本上进行修改, 调用修改的方法后, 会把这个副本返回
这类API都有一个共同的参数: inplace, 默认值是False
如果把inplace的值改为True, 就会直接修改原来的数据, 此时这个方法就没有返回值了
-
通过 set_index()函数 设置行索引名字
# 读取文件, 不指定索引, Pandas会自动加上从0开始的索引 movie = pd.read_csv('data/movie.csv') movie.head() # 设置 电影名 为索引列. movie1 = movie.set_index('movie_title') movie1.head() # 如果加上 inplace=True, 则会修改原始的df对象 movie.set_index('movie_title', inplace=True) movie.head() # 原始的数据并没有发生改变. -
加载数据的时候, 直接指定索引列
-
通过reset_index()函数, 可以重置索引
# 加上inplace, 就是直接修改 源数据. movie.reset_index(inplace=True) movie.head()
9、DataFrame-修改行列索引
-
方式1: rename()函数, 可以对原有的行索引名 和 列名进行修改
movie = pd.read_csv('data/movie.csv', index_col='movie_title') movie.index[:5] # 前5个行索引名 movie.columns[:5] # 前5个列名 # 手动修改下 行索引名 和 列名 idx_rename = {'Avatar': '阿凡达', "Pirates of the Caribbean: At World's End": '加勒比海盗'} col_rename = {'color': '颜色', 'director_name': '导演名'} # 通过rename()函数, 对原有的行索引名 和 列名进行修改 movie.rename(index=idx_rename, columns=col_rename).head() -
**方式2:**把 index 和 columns属性提取出来, 修改之后, 再赋值回去
index类型不能直接修改,需要先将其转成列表, 修改列表元素, 再整体替换movie = pd.read_csv('data/movie.csv', index_col='movie_title') # 提取出 行索引名 和 列名, 并转成列表. index_list = movie.index.tolist() columns_list = movie.columns.tolist() # 修改列表元素值 index_list[0] = '阿凡达' index_list[1] = '加勒比海盗' columns_list[0] = '颜色' columns_list[1] = '导演名' # 重新把修改后的值, 设置成 行索引 和 列名 movie.index = index_list movie.columns = columns_list # 查看数据 movie.head(5)
10、添加-删除-插入列
-
添加列
movie = pd.read_csv('data/movie.csv') # 通过 df[列名] = 值 的方式, 可以给df对象新增一列, 默认: 在df对象的最后添加一列. movie['has_seen'] = 0 # 新增一列, 表示: 是否看过(该电影) # 新增一列, 表示: 导演和演员 脸书总点赞数 movie['actor_director_facebook_likes'] = ( movie['actor_1_facebook_likes'] + movie['actor_2_facebook_likes'] + movie['actor_3_facebook_likes'] + movie['director_facebook_likes'] ) movie.head() # 查看内容 -
删除列 或者 行
# movie.drop('has_seen') # 报错, 需要指定方式, 按行删, 还是按列删. # movie.drop('has_seen', axis='columns') # 按列删 # movie.drop('has_seen', axis=1) # 按列删, 这里的1表示: 列 movie.head().drop([0, 1]) # 按行索引删, 即: 删除索引为0和1的行 -
插入列
有点特殊, 没有inplace参数, 默认就是在原始df对象上做插入的.
# insert() 表示插入列. 参数解释: loc:插入位置(从索引0开始计数), column=列名, value=值 # 总利润 = 总收入 - 总预算 movie.insert(loc=1, column='profit', value=movie['gross'] - movie['budget']) movie.head()
13、DataFrame导入和导出操作
1.DataFrame-保存数据到文件
-
格式
df对象.to_数据格式(路径) # 例如: df.to_csv('data/abc.csv') -
代码演示
如要保存的对象是计算的中间结果,或者以后会在Python中复用,推荐保存成pickle文件
如果保存成pickle文件,只能在python中使用, 文件的扩展名可以是
.p,.pkl,.pickl# output文件夹必须存在 df.to_pickle('output/scientists.pickle') # 保存为 pickle文件 df.to_csv('output/scientists.csv') # 保存为 csv文件 df.to_excel('output/scientists.xlsx') # 保存为 Excel文件 df.to_excel('output/scientists_noindex.xlsx', index=False) # 保存为 Excel文件 df.to_csv('output/scientists_noindex.csv', index=False) # 保存为 Excel文件 df.to_csv('output/scientists_noindex.tsv', index=False, sep='\t') print('保存成功') -
注意, pandas读写excel需要额外安装如下三个包
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlwt pip install -i https://pypi.tuna.tsinghua.edu.cn/simple openpyxl pip install -i https://pypi.tuna.tsinghua.edu.cn/simple xlrd
2.DataFrame-读取文件数据
-
格式
pd对象.read_数据格式(路径) # 例如: pd.read_csv('data/movie.csv') -
代码演示
# pd.read_pickle('output/scientists.pickle') # 读取Pickle文件中的内容 # pd.read_excel('output/scientists.xlsx') # 多1个索引列 # pd.read_csv('output/scientists.csv') # 多1个索引列 pd.read_csv('output/scientists_noindex.csv') # 正常数据
读取tsv:需要设置sep参数为 “\t”
14、Pandas数据加载
- 按列加载:
- 加载一列
import pandas as pd
emp_df = pd.read_csv(r'..\pandas数据集\emp_with_head.csv')
# ----------获取一列数据-----------
# df.列名
emp_df.sal
s = emp_df['sal']
# s.sale # 'Series' object has no attribute 'sal'
# df[列标签]
emp_df['sal']
# df[[双层列标签]]
df1 = emp_df[['sal']]
type(emp_df[['sal']]) # pandas.core.frame.DataFrame
type(df1['sal'])
# loc获取指定列
emp_df.loc[0:'sal']
# iloc获取一列数据
emp_df.iloc[:,0]
细节: 如果写 df[‘country’] 则是Series对象, 如果写 df[[‘country’]]则是df对象
- 加载多列
# df.loc[行标签,列标签] 所有行这么写df.loc[:,列标签]
emp_df.loc[0,'sal']
emp_df.loc[:,['sal','comm']]
# 获取多个连续列
emp_df.loc[:, 'job':'sal'] # 切片 包含结尾
emp_df.take([0,1,2])
# iloc获取一列数据
emp_df.iloc[:,0]
# emp_df.iloc[0,0]
# iloc获取一行数据
emp_df.iloc[0,:]
# iloc获取不连续列
emp_df.iloc[:,[0,1,2]]
# iloc获取连序列
emp_df.iloc[:,0:3]
- 按行加载
# ---------------------获取行数据-------------------------
emp_df[:4]
emp_df[2:] # 切片也可以用于直接获取行,但不能用于列切片,注意loc可以。
emp_df.head(2)
emp_df.tail(2)
emp_df.sample(2)
emp_df.take([0,1])
emp_df.loc[0:2, :]
emp_df.loc[0:2]
type(emp_df.loc[2])
emp_df.iloc[0:2,:]
emp_df.iloc[0:2]
emp_df.iloc[0]
emp_df.iloc[[0,1,4]]
- 获取指定的行、列
print('============== 传统方式=======麻烦==========')
print(df.head(3)[['name','job']])
print('============== 获取多行多列数据 ===loc=================')
# df.loc[[行标签],[列标签]]
print(df.loc[[0,2,3],['name','job']])
print('============== 获取多行多列数据 ===loc==切片===[包含]====')
print(df.loc[0:3,'id':'job'])
print('============== 获取多行多列数据 ===iloc=================')
print(df.iloc[[0,2,3],[0,1]])
print('============== 获取多行多列数据 ===iloc==切片==[不包含]====')
print(df.iloc[0:3,0:2])
loc和iloc的对比:
| loc | iloc |
|---|---|
| 按照tag来索引,类似于记录的元素的相对位置,当前未设置行头标签的时候与iloc索引一致 | 按照索引来取数据,绝对位置 |
| 支持切片获取,左闭右闭 | 支持切片获取,左闭右开 |
15、分组聚合
思路为:先将数据分组,对每组数据统计计算(平均、max、min、sum),再将每一组计算结果合并起来。
import pandas as pd
df = pd.read_csv(r'..\pandas数据集\gapminder.tsv', sep='\t')
df.head()
语法
df.groupby(‘分组字段’)[‘要聚合的字段’].聚合函数()
df.groupby([‘分组字段’,‘分组字段2’])[[‘要聚合的字段’,‘要聚合的字段2’]].聚合函数()
#-------------------单分组单聚合-------------
groups = df.groupby('year')
df.groupby('year')['lifeExp'].mean ()
#-------------------多分组多聚合-------------
df.groupby(['year', 'continent'])['lifeExp'].mean ()
df.groupby(['year', 'continent'])[['lifeExp', 'gdpPercap']].mean ()
#------------------多分组多聚合(聚合函数不同)-----------
df.groupby(['year','continent']).agg({'lifeExp':'mean','gdpPercap':'max'})
#---------------------常用聚合函数-------------- -
df.groupby('continent')['gdpPercap'].count () # 不去重统计
df.groupby('continent')['gdpPercap'].nunique () #去重统计
df.info
# ------------------分组后的第一条数据、最后一条数据------------
df.groupby('continent')['gdpPercap'].first()
df.groupby('continent')['gdpPercap'].last()
# ------------前 n 个指定列最大的数据-------
emp_df = pd.read_csv(r'pandas数据集\emp_with_head.csv')
emp_df.nlargest(5, 'sal')
emp_df.sort_values('sal', ascending=True).drop_duplicates(subset='sal', keep='first').head(3)
# ------------前 n 个最小的数据-----------
emp_df.nsmallest(5, 'sal')
pandas的plot()方法
常用参数:
-
kind
kind 参数用于指定绘制的图表类型。它接受以下几种值:‘line’:折线图(默认)。
‘bar’:条形图。
‘barh’:水平条形图。
‘hist’:直方图。
‘box’:箱型图。
‘kde’ 或 ‘density’:核密度估计图(平滑直方图)。
‘area’:区域图(类似堆叠区域图)。
‘pie’:饼图。 -
x y 指定行和列
-
title 参数用于设置图表的标题。
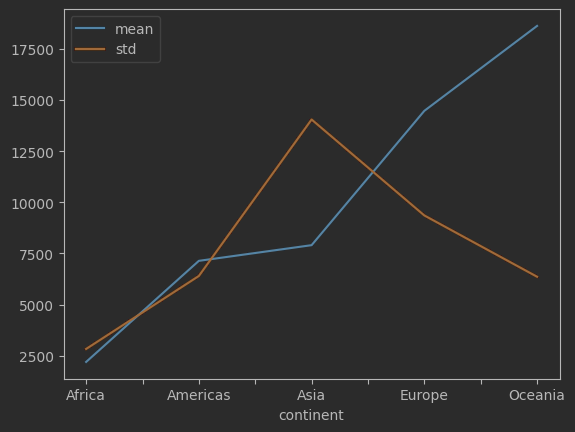
df.groupby('continent')['gdpPercap'].agg(['mean', 'std']) .plot()
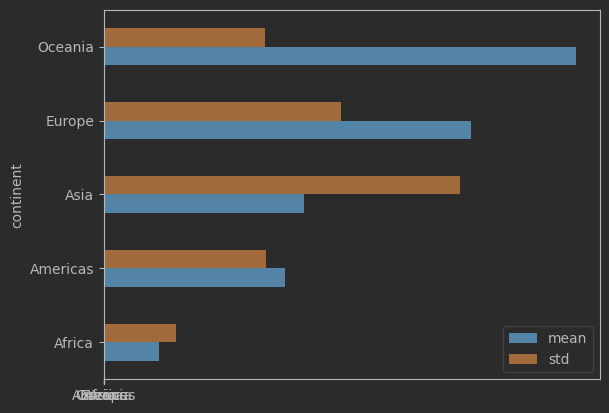
df.groupby('continent')['gdpPercap'].agg(['mean', 'std']) .plot(kind='barh')
line = df.groupby('continent')['gdpPercap'].agg(['mean', 'std'])
import matplotlib.pyplot as plt
plt.plot(line)
16、缺失值处理
缺失值和其它类型的数据不同,它毫无意义,NaN不等于0,也不等于空串;在python中做数学计算时 True 为 1 ,False 为 0
缺失值测试方法:
- isnull() / isna()方法
- notnull() / notna() 方法
import pandas as pd
import numpy as np
# isnan() 判空
print(pd.isna(''))
print(pd.isna(np.nan))
print(pd.isna(pd.NA))
print('------------------------')
# isnull() 判空
print(pd.isnull(''))
print(pd.isnull(np.nan))
print(pd.isnull(pd.NA))
print('------------------------')
# notna() 判非空
print(pd.notna(''))
print(pd.notna(np.nan))
print(pd.notna(pd.NA))
print('------------------------')
# notnull() 判非空
print(pd.notnull(''))
print(pd.notnull(np.nan))
print(pd.notnull(pd.NA))
print('------------------------')
print(None == None)
print(np.nan == np.nan)
print(pd.NA == pd.NA)
print(pd.NA == 100) # NA 在运算中具有传播性
- NA 在运算中具有传播性
缺失值在加载时可以直接进行操作:
- 加载数据不加载缺失值:
pd.read_csv() keep_default_na = False 表示加载数据时, 不加载缺失值.
pd.read_csv(r'..\pandas数据集\survey_visited.csv', keep_default_na=False)

- 也可以指定数据中的哪些值加载为缺失值:
设置na_values=[值1, 值2…] 表示加载数据时, 设定哪些值为缺失值.
train = pd.read_csv(r'..\pandas数据集\titanic_train.csv', keep_default_na=False, na_values=['DR-1','MSK-4'])
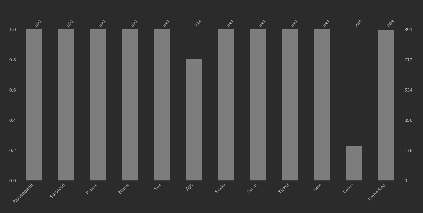
在加载数据后可以通过可视化看出缺失值大致比例:
使用 missingno库的bar()方法或者heatmap()方法
import missingno as msno
msno.bar(train)
删除缺失值:
- dropna()
参数
subset=None默认是: 删除有缺失值的行, 可以通过这个参数来指定, 哪些列有缺失值才会被删除
例如: subset = [‘Age’] 只有当年龄有缺失才会被删除
inplace=False通用参数, 是否修改原始数据默认False
axis=0通用参数 按行按列删除 默认行
how='any'只要有缺失就会删除 还可以传入’all’ 全部都是缺失值才会被删除
- drop()
参数
labels指定要删除的行或列标签
axis删除方向:0表示删除行,1表示删除列index指定要删除的行(等价于axis=0)
columns指定要删除的列(等价于axis=1)inplace是否在原DataFrame上直接修改,True表示原地删除
drop和dropna对比:

填充缺失值:
- fillna()
语法
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
- 非时间序列数据
使用统计量替换(缺失值所处列的平均值、中位数、众数) - 时序数据填充
同样可以使用pandas的fillna来处理这类情况
用时间序列中空值的上一个非空值填充fillna(method='ffill'),新版本可直接使用ffill()
用时间序列中空值的下一个非空值填充fillna(method='bfill'),新版本可直接使用bfill()
train.fillna(value=0)
train.fillna(method='ffill')
train.fillna(method='bfill')
m = train['ident'].mean()
train.fillna(value=m)
df1.ffill()
df1.bfill()
- interpolate()
线性插值方法填充缺失值,它假定数据点之间存在线性关系,利用相邻数据点中的非缺失值来计算缺失数据点的值。
语法
DataFrame.interpolate(method=‘linear’, axis=0, limit=None, limit_direction=‘both’, limit_area=None, downcast=None)
参数:

df1.interpolate(limit_direction='both')
17、Apply接口自定义函数
当Pandas自带的API不能满足需求就可以使用Apply自定义函数;apply函数可以接收一个自定义函数;Series传入每次按照单元素传,Data Frame传入时按照一列一列数据传入。
语法:
- 用于DataFrame
DataFrame.apply(func, axis=0, raw=False, result_type=None, args=(), **kwds)
- 对于Series
Series.apply(func, convert_dtype=True, args=(), **kwds)
参数:

apply传入的函数可以带有参数,参数通过apply的args、**kwds参数传递,在apply中指定关键字传参就可以。
简单的函数可以直接写lambda表达式传入;
df1.apply(lambda x: x*2)
# 1.先定义函数
def func1(x, n=2):
return x + n
def func2(x, n=2):
return x - n
def func3(x, n=2):
return x * n
def func4(x, n=2):
return x / n
# TODO s对象调用apply函数(依次操作的s对象中每个元素)
# 注意: apply函数的参数是函数名没有括号(),返回值是新的Series对象
print(s.apply(func1, n=3))
print(s.apply(func2, n=3))
print(s.apply(func3, n=3))
print(s.apply(func4, n=3))
注意对于DataFrame对象,传入apply的函数里是一列一列的Series对象;对于Series对象,传入的是Series的每一个元素。
18、向量化
NumPy 提供了 numpy.vectorize 函数,可以将一个标量函数转换为一个可以应用于数组(或 pandas.Series)的向量化函数。np.vectorize 其实是一个简单的循环封装器,它将一个标量函数转换为可以作用于数组(或其他可迭代对象)的函数。它内部并没有直接优化数组操作(如 NumPy 内置的加法和乘法那样快速),但它提供了类似广播的机制,可以将标量操作应用于数组。
- 使用方法
1、函数调用: np.vectorize(avg_2_mod)
# 先定义函数
def avg2(x, y):
if x == 20:
return np.nan
else:
return (x + y) / 2
np.vectorize(avg2)
# 调用函数
avg2(df['A'], df['B'])
2、装饰器:@ np.vectorize # 装饰器方式实现向量化
# 语法糖方式添加@np.vectorize,作用是将函数向量化
# 再添加@np.vectorize
@np.vectorize
# 先定义函数
def avg2_zsq(x, y):
if x == 20:
return np.nan
else:
return (x + y) / 2
# 调用函数
avg2_zsq(df['A'], df['B'])
19、Pandas聚合
groupby函数:分组之后,每组都会有至少1条数据, 将用内置函数这对些数据进一步处理
可与groupby一起使用的内置函数

aggregate()
aggregate() 是 pandas 中用于对数据进行聚合操作的函数。它可以用来对 DataFrame 或 Series 进行分组后,对每个分组应用某些聚合函数(如求和、平均值、最大值、最小值等)。agg()与之一样.
语法
DataFrame.aggregate(func, axis=0, *args, **kwargs)
Series.aggregate(func, axis=0, *args, **kwargs)
df.groupby(['year']).agg({'lifeExp': 'mean'}) # 键值对传函数方式
df.groupby(['year']).agg({'lifeExp': np.mean}) # 非pandas函数不需要引号
df.groupby(['year']).lifeExp.agg(np.mean) # 也可以使用只传函数的方式,就会对前部的结果进行运算
df.groupby(['year']).lifeExp.agg([np.mean, np.max, np.min]) # 传递多个函数对同一列信息计算
df.groupby(['year']).lifeExp.aggregate([np.mean, np.max, np.min]) # aggregate效果相同
df.groupby(['year', 'continent']).agg({'lifeExp': np.mean, 'gdpPercap': np.max}) # 多个列进行多个聚合操作
- 此外agg还接受自定义函数,如同apply:
# 需求: 模仿已有的mean()等函数,自定义一个my_mean()函数
def my_mean(values):
# 平均数=总和/总个数
# 先计算总和
sum = 0
for value in values:
sum += value
# 再计算总个数
cnt = len(values)
# 计算平均数
avg = sum / cnt
return avg
# 需求: 使用自定义的聚合函数求每年的平均寿命
df.groupby('year').lifeExp.agg(my_mean)
对于有参数的自定义函数可以由agg传参:
def my_mean(values, x):
# 平均数=总和/总个数
# 先计算总和
print(x)
sum = 0
for value in values:
sum += value
# 再计算总个数
cnt = len(values)
# 计算平均数
avg = sum / cnt
return avg
print(df.groupby('City').Xylene.agg(my_mean, x=1))
19、分组转换
transform()
transform 需要把DataFrame中的值传递给一个函数, 而后由该函数"转换"数据。aggregate(聚合) 返回单个聚合值,但transform 不会减少数据量。
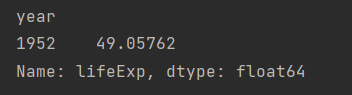
# 需求: 求1952年的平均寿命
# 方式1: 原来的agg得到结果就1个
df[df.year == 1952].groupby('year').lifeExp.agg(my_mean)
# 方式2: transform得到的结果是142个
df[df.year == 1952].groupby('year').lifeExp.transform(my_mean)
效果类似于SQL中的开窗函数over()
20、分组过滤
filter()
1、filter()函数的功能是传入一个返回布尔值的函数,自动判断出True和False,最后自动过滤掉False的数据,返回True的数据
2、在 pandas 中,filter() 是一个用于 选择 列(或行)名字的函数。它允许通过指定模式、标签或列(行)名的前缀或后缀来过滤 DataFrame 或 Series 的列名或行索引。
new_df = df.groupby(‘size’).filter(lambda x: x[‘size’].count() > 30)
分组对象
经过groupby()函数分组后的DataFrame对象是DataFrameGroupBy它具有分组后操作的函数功能。如 first()、last() 以及各类聚合函数。
通过 groups 属性能查看分组对象中的数据,格式是(分组的列名,分组的索引)。
多个分组时可以通过 index 属性查看结果中的行索引。columns 属性可以用来查看结果中的列标签。分组之后也可以通过T转置。
# 单独获取性别为male的数据
dfg.get_group('Male')
# 获取每组的平均total_bill
dfg.total_bill.mean()
# 获取每组的第一条数据
dfg.first()
# 获取每组的最后一条数据
dfg.last()
# 查看分组对象中的数据
# 数据格式: (分组的列名,分组的索引)
dfg.groups
group_avg = df.groupby(['sex', 'time'])[['size']].mean()
# 查看分组聚合结果中行索引
group_avg.index
# 查看分组聚合结果中列标签
group_avg.columns
分组默认会将分组的列作为索引列,多个分组会由多个级别的索引组成,级别先后按照分组先后顺序确定。
比如
group_avg = df.groupby([‘sex’, ‘time’])[[‘size’]].mean()
分组后可以使用:
group_avg[(‘sex’,‘time’)]
取到对应的行信息。
- 如果不希望使用分组索引:
- 可以使用reset_index()重置索引;
- 也可以在分组时设置as_index()属性
group_avg4 = tips10.groupby([‘sex’, ‘time’], as_index=False)[[‘size’]].mean()
21、透视表
数据透视表(Pivot Table)是一种交互式的表,可以进行某些计算,如求和与计数等.
所进行的计算与数据跟数据透视表中的排列有关。之所以称为数据透视表,是因为可以动态地
改变它们的版面布置,以便按照不同方式分析数据,也可以重新安排行号、列标和页字段。每
一次改变版面布置时,数据透视表会立即按照新的布置重新计算数据;如果原始数据发生更改,则可以更新数据透视表;Pandas透视表功能,对应的API为pivot_table
语法:
DataFrame.pivot_table(data=None, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, margins_name=‘All’, dropna=True)
参数:
-
data:
说明:要进行透视的 DataFrame。默认是当前的 DataFrame。 -
values:
说明:你希望进行聚合统计的列名。通常是一个数值列,pivot_table() 会基于该列进行汇总。如果不指定,默认为所有数值列。 -
index:
说明:用于指定数据透视表的行索引,通常是分类变量。也可以理解为数据透视表中的“行”维度。 -
columns:
说明:用于指定数据透视表的列索引,通常是另一个分类变量。也可以理解为数据透视表中的“列”维度。 -
aggfunc:
说明:聚合函数,决定如何对数据进行聚合(汇总统计)。默认是 ‘mean’(均值),也可以使用其他聚合函数,如 ‘sum’(求和)、‘count’(计数)、‘min’(最小值)、‘max’(最大值)等。你还可以传入多个聚合函数。 -
fill_value:
说明:指定填充空值的位置。如果某个单元格没有数据,可以使用此参数来填充缺失值。默认值为 None。 -
margins:
说明:是否添加汇总行和汇总列,默认值是 False。如果设置为 True,则会在数据透视表的最后一行和最后一列显示汇总值(例如:所有行/列的总和或平均值)。 -
margins_name:
说明:指定汇总行和汇总列的名称,默认是 ‘All’。 -
dropna:
说明:是否去掉包含所有缺失值的列或行,默认为 True。
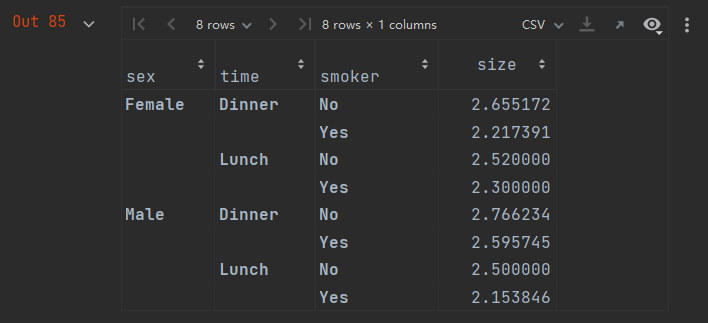
df.pivot_table(index=['sex', 'time', 'smoker'], values='size', aggfunc='mean')



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









