




视频讲解1:Biliili视频讲解
视频讲解2:https://www.douyin.com/video/7579828631925460265
论文下载:https://arxiv.org/abs/2502.20625
代码下载:https://github.com/cha15yq/T2ICount
论文CLIP-Count(基于文本指导的零样本目标计数)详解(PyTorch)
目录
分层语义校正模块(Hierarchical Semantic Correction Module, HSCM)
表征区域一致性损失(Representational Regional Coherence Loss, L_RRC)
分层语义相关模块(Hierarchical Semantic Correction Module)
语义增强模块(Semantic Enhancement Module ,SEM)
语义校正模块(Semantic Correction Module ,SCM)
零样本物体计数,旨在根据文本描述(而非视觉示例)来统计图像中任意类别物体的数量。这是一个具有挑战性的像素级任务,需要深入理解文本引导的局部语义。
本文提出的T2ICount框架通过创新性地利用扩散模型和引入HSCM与L_RRC,有效解决了零样本计数中的文本不敏感性难题。同时,通过构建FSC-147-S基准,为未来文本引导计数研究提供了更严格的评估标准。实验表明,该方法在现有基准和新的挑战性任务上均达到了领先水平。

现有方法的局限性
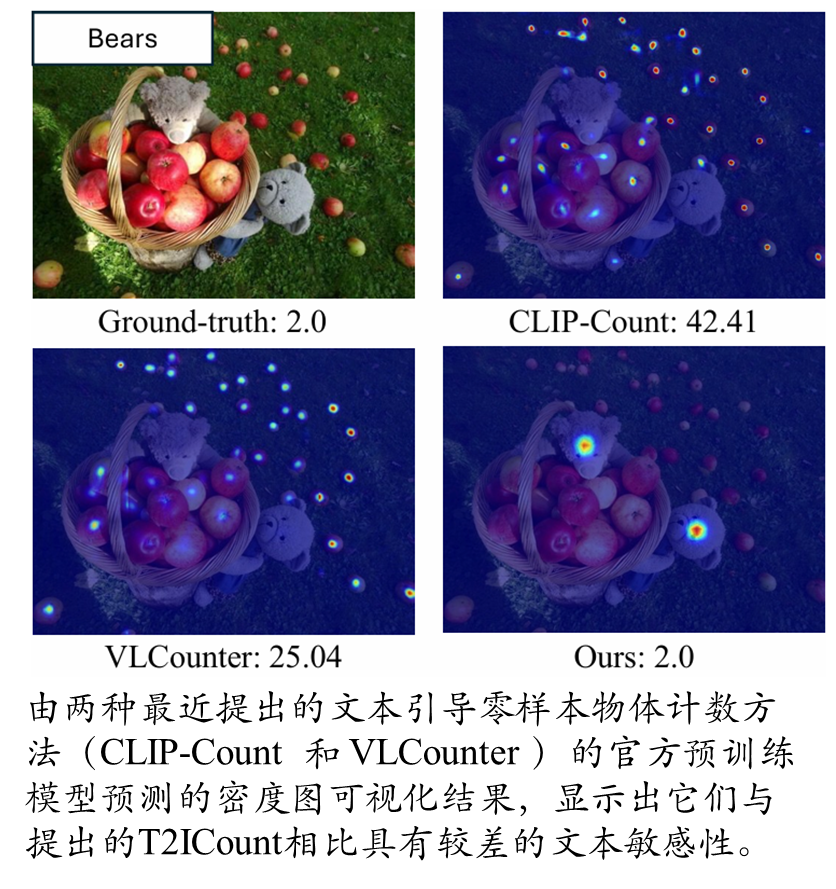
当前最先进的方法(如CLIP-Count, VLCounter)主要依赖于预训练的视觉-语言模型(如CLIP)。然而,这些模型存在一个关键缺陷——文本不敏感性。如图1所示,当文本指定的类别与图像中的多数类别不同时,这些模型往往无法准确计数,因为它们倾向于关注图像中占主导地位的物体,而忽略了文本提示的指导。
数据集偏差:本文指出,常用基准数据集(如FSC-147)的标注存在偏差,每张图像通常只标注了数量上占多数的物体类别。这种偏差与CLIP模型的全局语义偏见相结合,掩盖了现有方法在文本引导计数能力上的根本缺陷。
提出方法
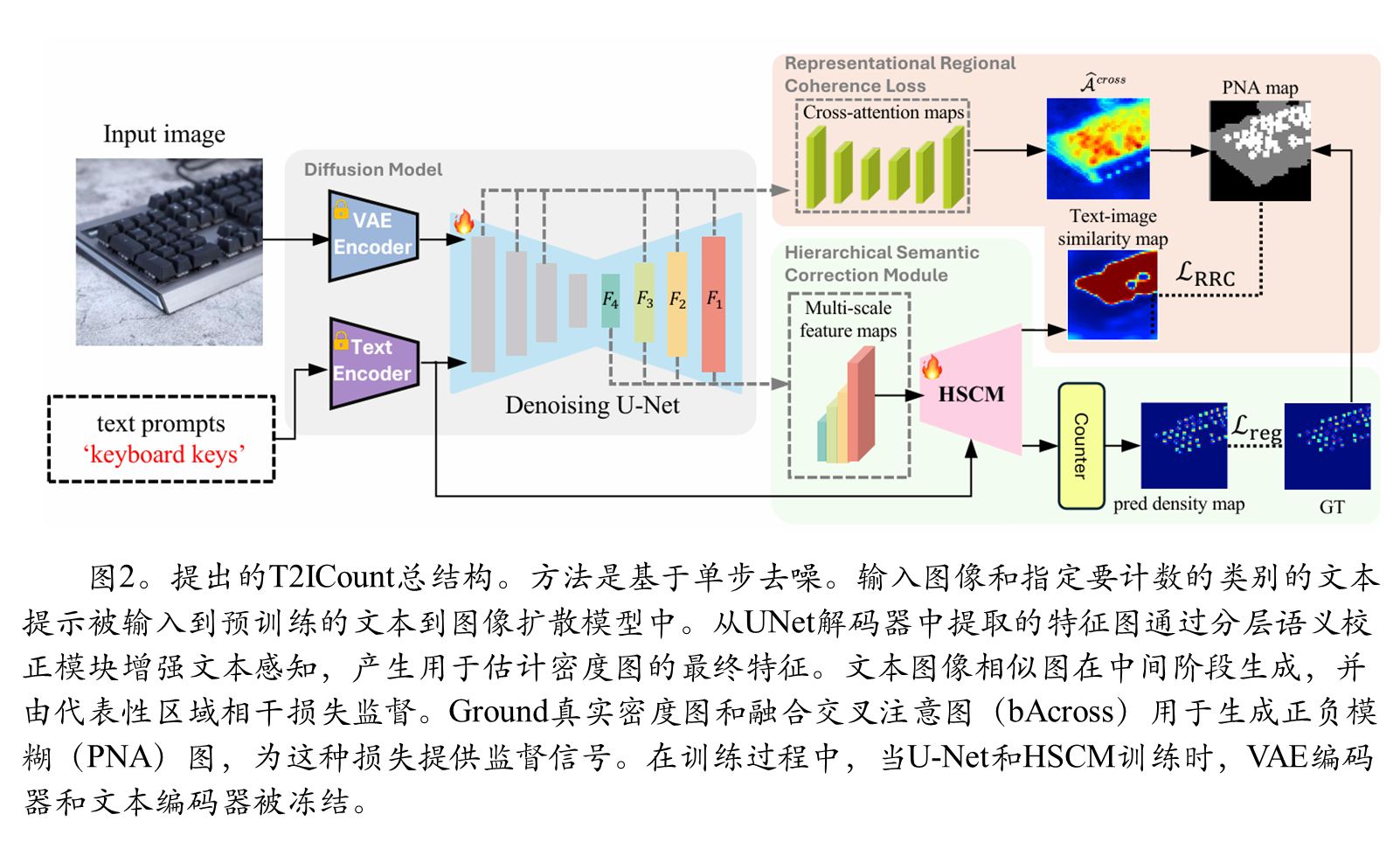
本文提出了T2ICount,一个基于扩散模型的框架。其核心思想是利用预训练文本到图像扩散模型(如Stable Diffusion)中蕴含的丰富先验知识和细粒度视觉理解能力。为了追求实际应用中的效率,T2ICount采用单步去噪来提取特征,而非耗时的多步去噪过程。但这导致了文本-图像交互的减弱,即文本敏感性降低。
分层语义校正模块(Hierarchical Semantic Correction Module, HSCM)
- 第一目的:补偿单步去噪造成的文本-图像特征对齐弱化问题,进行渐进式的特征细化;
- 第二实现方法:该模块分阶段处理从去噪U-Net中提取的多尺度特征。它包含两个子模块:•语 义增强模块(SEM):通过双向跨模态注意力机制增强文本和图像特征的交互,并 生成文本-图像相似度图;
- 第三语义校正模块(SCM):利用上一阶段生成的相似度图作为注意力引导,来校正当前阶 段的特征表示,将模型的注意力重新定向到文本相关的区域。通过这种级联设计, HSCM确保了文本-图像对齐能力得到逐步增强。
表征区域一致性损失(Representational Regional Coherence Loss, L_RRC)
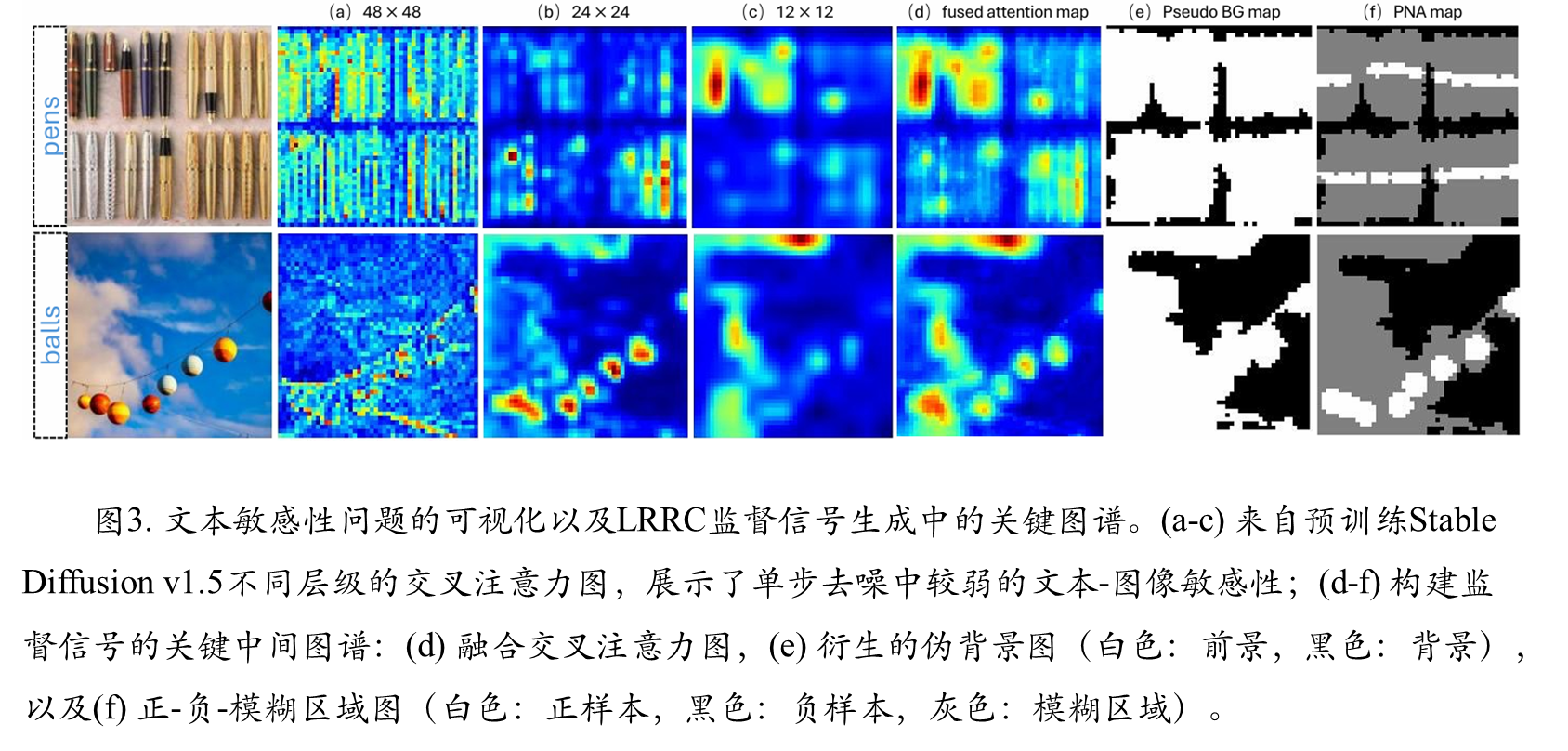
首先:为中间生成的相似度图提供可靠的监督信号,解决计数数据集中缺乏实例级标注所带来的正负样本难以区分的问题。本文发现,尽管单步去噪的交叉注意力图对特定类别不敏感,但它们能有效捕捉图像中的整体前景区域。
最后,融合多尺度交叉注意力图生成一个统一的前景区域估计图。将此图与真实密度图结合,生成一个正-负-模糊区域(PNA)map(图3f)。该map明确标明了正样本(高密度区域)、负样本(低注意力背景区域)和模糊区域。L_RRC损失函数在此基础上,鼓励正样本区域有高相似度,负样本区域有低相似度,而对模糊区域不施加约束,从而实现了更精确的特征学习。
CLIP的图像编码器局限性

输入流程:
图像 + 文本提示 → CLIP图像编码器 → 特征提取 → n} → 计数专用头 → 密度图预测
文本 → CLIP文本编码器 → 文本特征
微调重点:
- 图像编码器的计数偏置学习
- 跨模态特征对齐优化
- 密度回归网络设计
具体方法
单步去噪中的文本不敏感

分层语义相关模块(Hierarchical Semantic Correction Module)

语义增强模块(Semantic Enhancement Module ,SEM)

语义校正模块(Semantic Correction Module ,SCM)

表征区域一致性损失


def get_reg_loss(pred, gt, threshold, level=3, window_size=3):
mask = gt > threshold
loss_ssim = cal_avg_ms_ssim(pred * mask,
gt * mask,
level=level,
window_size=window_size)
mu_normed = get_normalized_map(pred)
gt_mu_normed = get_normalized_map(gt)
tv_loss = (nn.L1Loss(reduction='none')(mu_normed,
gt_mu_normed
).sum(1).sum(1).sum(1)).mean(0)
return loss_ssim + 0.1 * tv_loss
def RRC_loss(simi, ambiguous_negative_map, positive_map):
# 其中simi表示计算的文本和图像特征之间的相似性结果
# ambiguous_negative_map表示模棱两可的负样本区域
# positive_map表示正样本区域
pos = (1 - simi) * positive_map
# 负样本
neg = torch.clamp(simi, min=0) * (ambiguous_negative_map == 0) * (positive_map == 0)
# 正样本区域求和
pos_num = positive_map.flatten(1).sum(dim=1)
# 负样本区域求和
neg_num = ((ambiguous_negative_map == 0) * (positive_map == 0)).flatten(1).sum(dim=1)
loss = 2 * pos.flatten(1).sum(dim=1) / (pos_num + 1e-7) + neg.flatten(1).sum(dim=1) / (neg_num + 1e-7)
return loss.mean()FSC_147数据集介绍
1 数据集背景与定位
FSC-147(Few-Shot Counting 147)是第一个大规模类别无关计数数据集,专门为推进少样本和零样本物体计数研究而创建。该数据集突破了传统类别特定计数(如只计数人群、车辆)的限制,使模型能够计数任意类别的物体实例。其核心目标是开发通用型物体计数器,仅需少量示例(甚至零示例)即可计数从未见过的新类别。
2 数据内容与统计信息
根据文档内容,FSC-147数据集包含6,135张图像,覆盖了147个完全不同的物体类别。这些类别具有极高的多样性,涵盖了动物、厨房用具、交通工具等各种日常物品。
数据集划分特点:
- 训练集:包含来自89个类别的图像
- 验证集:包含来自29个类别的图像
- 测试集:包含来自29个类别的图像
- 关键特性:训练集、验证集和测试集中的类别是完全不相交的,这确保了评估的公平性,能够真实反映模型对全新类别的泛化能力。
标注信息:
- 每张图像都标注了物体中心的点级标注,可用于生成真实密度图(npy格式)
- 提供每个图像的类别名称信息
- 为每张图像提供3个视觉示例(边界框box),用于指定要计数的物体
实验结果
综合比较
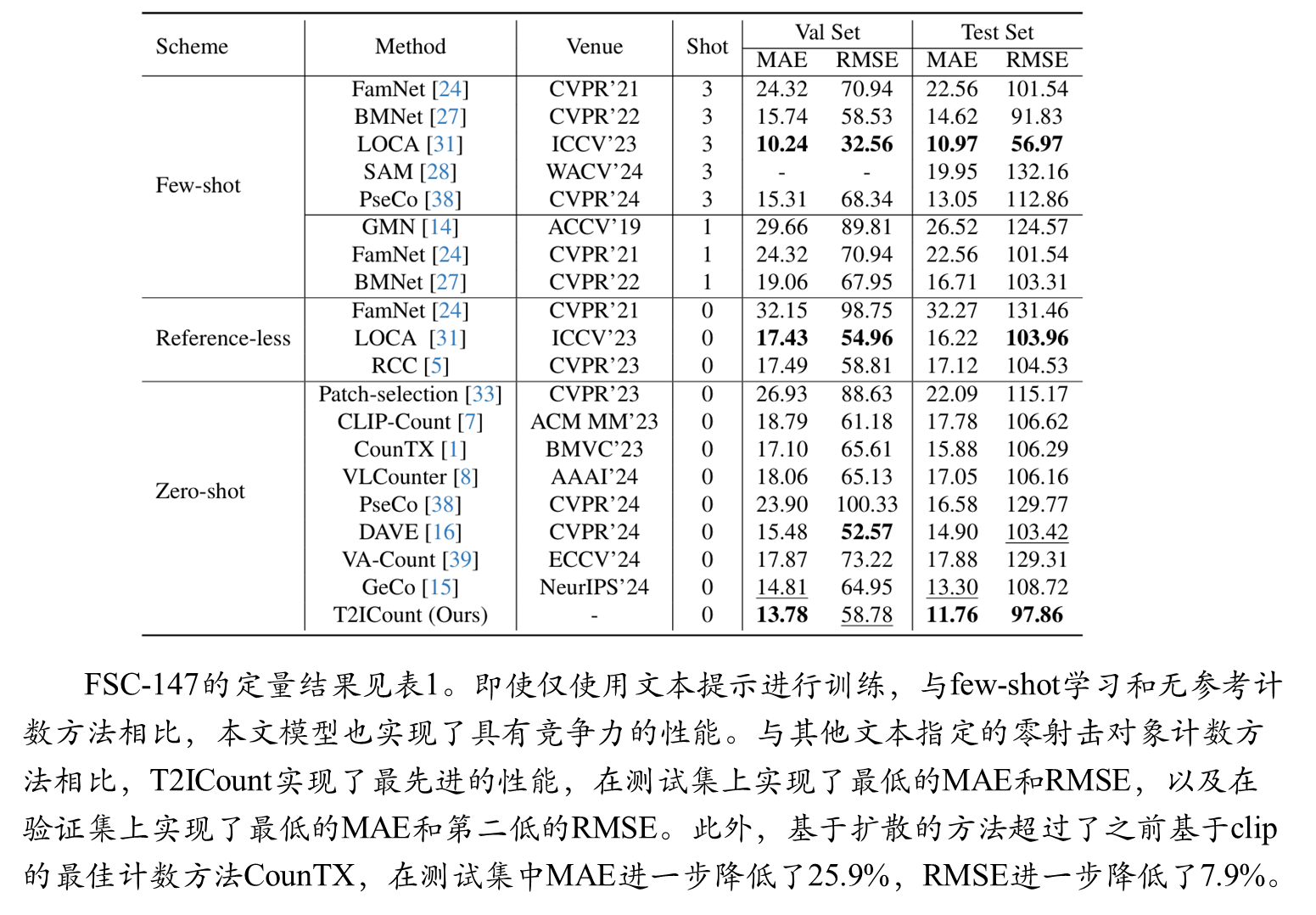
FSC-147-S实验结果

CARPK测试结果
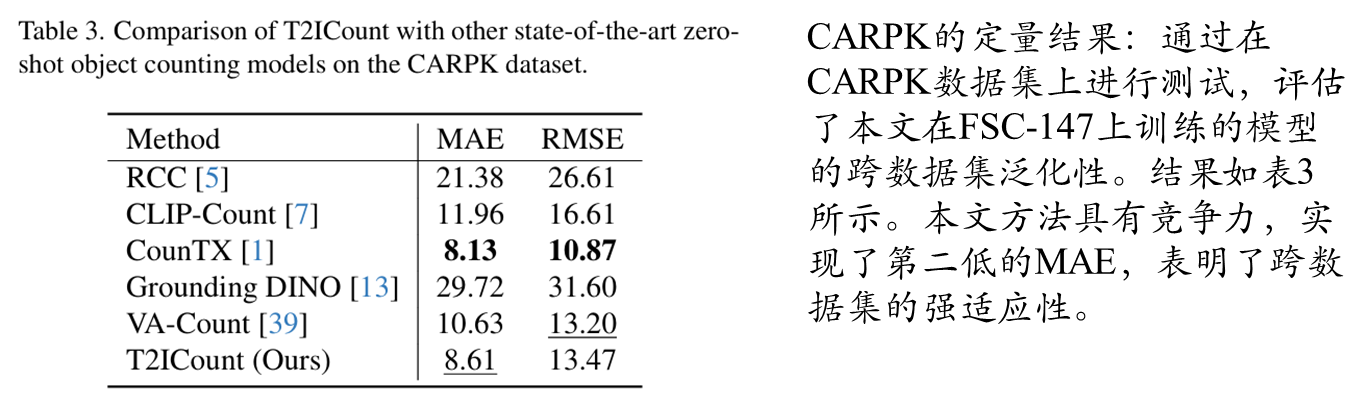
可视化结果

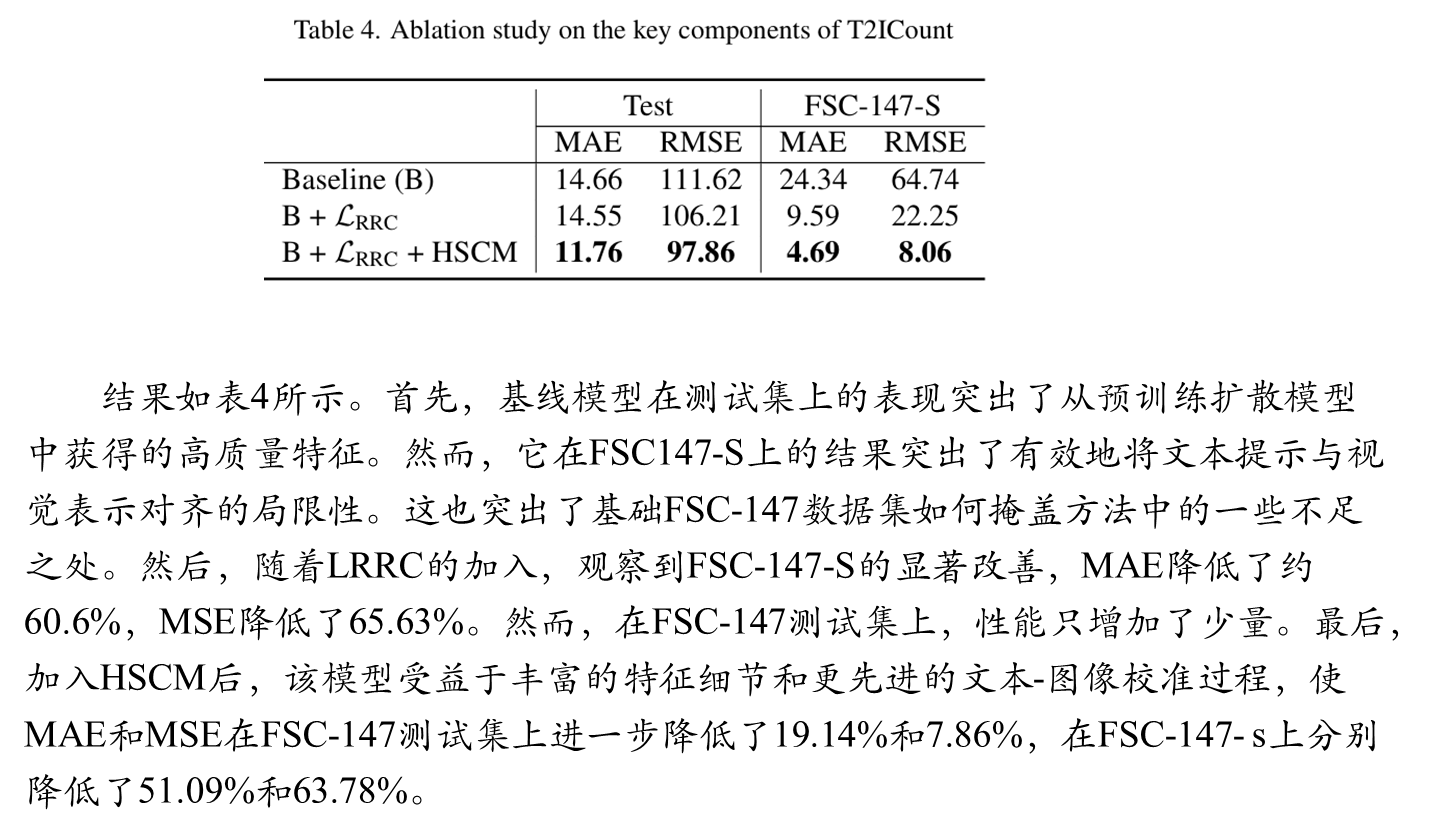
消融实验


















 2146
2146

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









