



论文下载:https://arxiv.org/pdf/2012.09841v3.pdf
代码下载:https://github.com/CompVis/taming-transformers
大家在看这篇论文之前,请先看论文VQ-VAE详解(PyTorch) ,因为VQ-GAN是基于VQ-VAE方法来的。和之前一样,之所以将这篇论文主要是为后面CLIP-GEN论文打下基础,因此,建议小伙伴先看VQ-VAE和VQ-GAN,之后再去学习CLIP-GEN的时候会很快。但是对于本文里面一些知识点,感觉自己的理解并不是很好,所以较多的地方并没有去拓展讲解。

目录
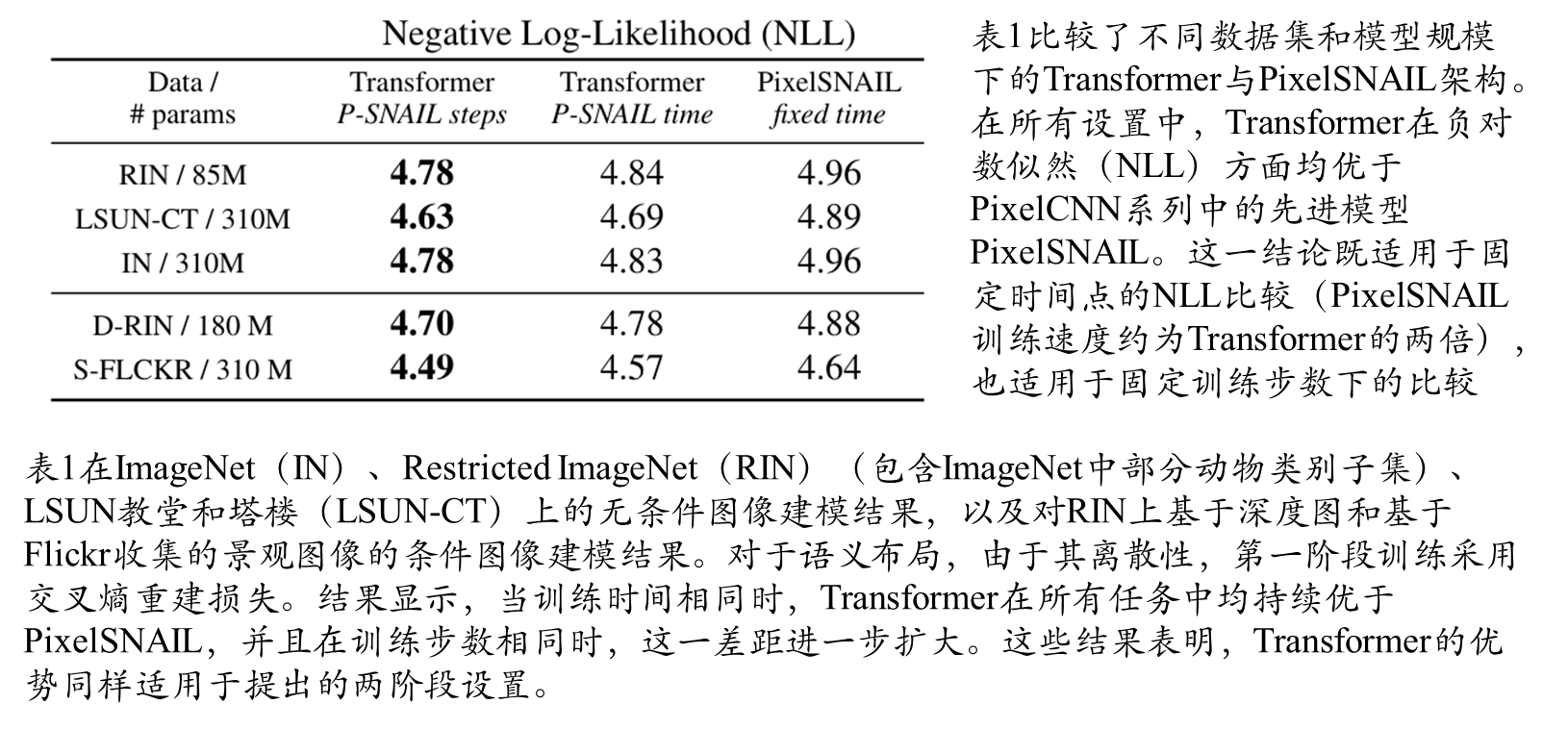
不同数据集和模型规模下的Transformer与PixelSNAIL架构
一 提出目的和方法
提出目的
Transformer旨在学习序列数据中的长距离依赖关系,已在众多任务中持续展现出最先进的效果。与卷积神经网络(CNN)不同,Transformer不包含优先考虑局部交互的归纳偏置。这使得它们表达能力强,但在处理长序列(如高分辨率图像)时计算成本极高。
提出方法
将CNN的归纳偏置优势与Transformer的表达能力相结合,使其能够建模并合成高分辨率图像。具体来说,我们展示了如何(i)利用CNN学习具有丰富上下文信息的图像组成单元词汇,进而(ii)利用Transformer高效地建模它们在高分辨率图像中的组合方式。我们的方法可以直接应用于条件合成任务,其中非空间信息(如物体类别)和空间信息(如分割图)都能控制生成的图像.
首先采用卷积方法高效地学习一个富含上下文信息的视觉组成部分词典,随后学习这些组成部分的全局组合模型。这些组合中的长距离交互需要一个表达力强的Transformer架构来建模其组成视觉部分的分布。此外,采用对抗训练的方法,确保局部部分的词典能捕捉到感知上重要的局部结构,从而减轻Transformer需要处理低级统计信息的负担。通过让Transformer专注于其独特优势——建模长距离关系,使其能够生成如图1所示的高分辨率图像,这在此前是难以实现的。本文方法通过关于目标类别或空间布局的条件信息,实现了对生成图像的控制。
二 整体模型架构
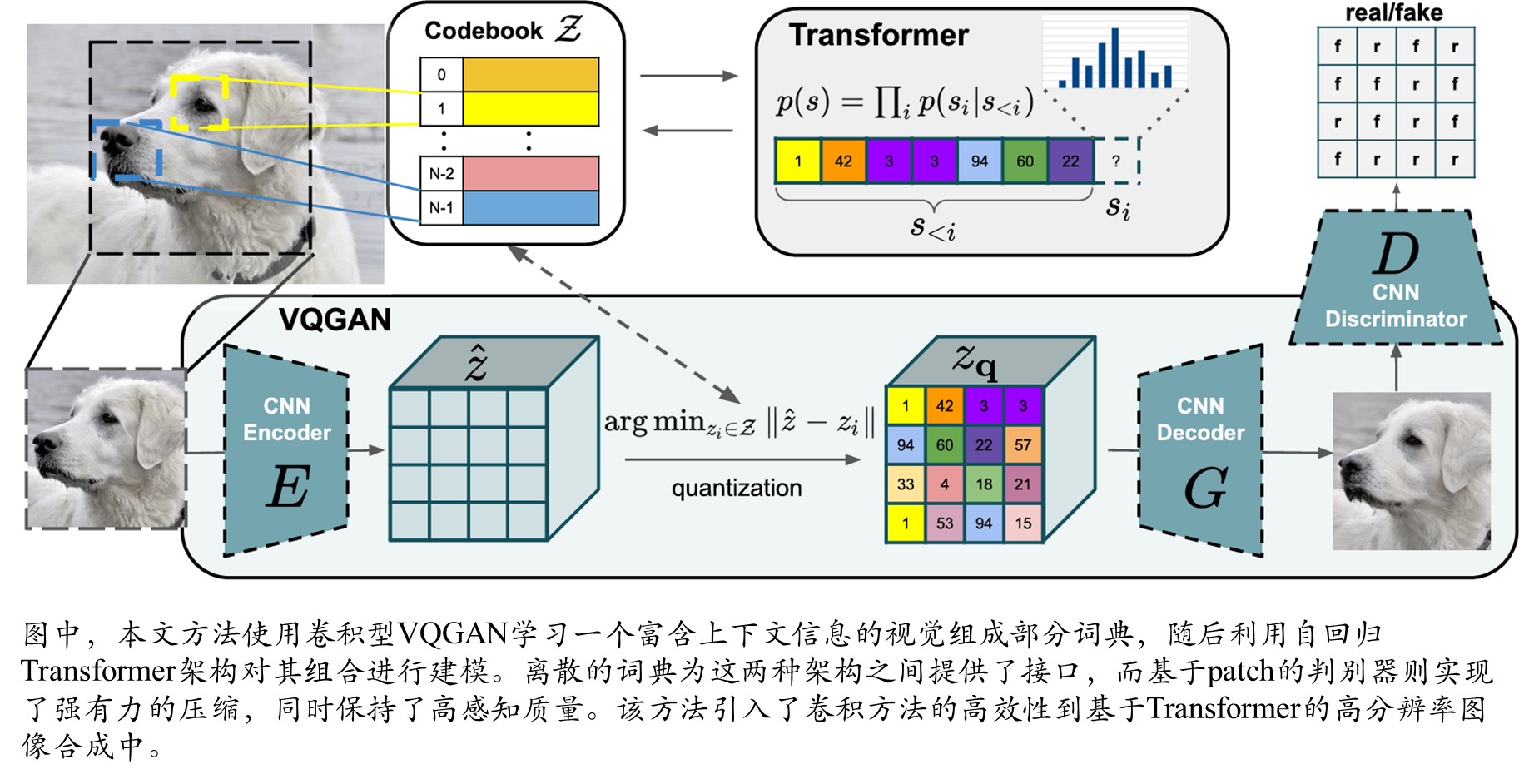
模型编码器和解码器细节

用于Transformer的图像组成部分有效词典学习

学习具有感知丰富性的codebook

Transformer学习图像的组成

基于条件合成图像

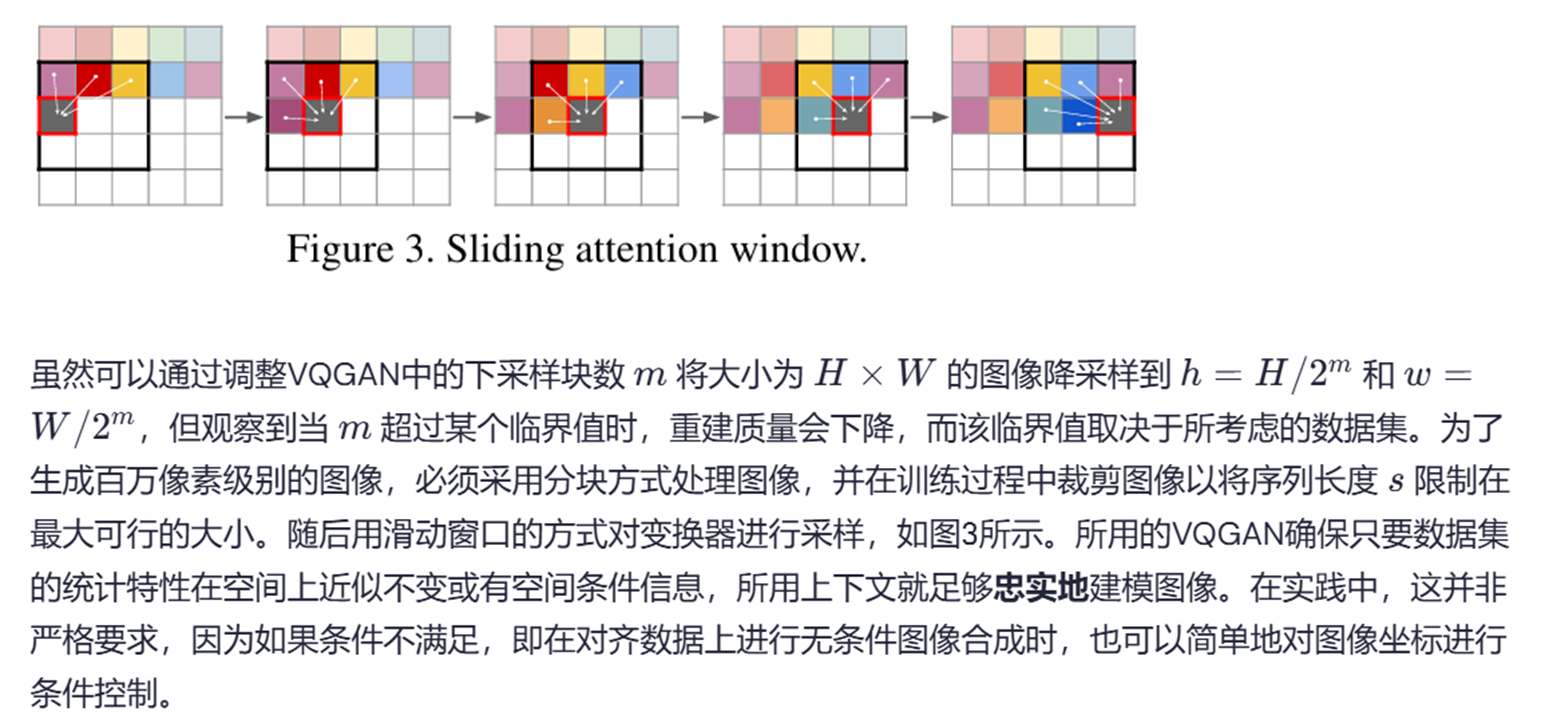
生成高分辨率图像
不同数据集和模型规模下的Transformer与PixelSNAIL架构

评估有效码本

FID评估模型性能
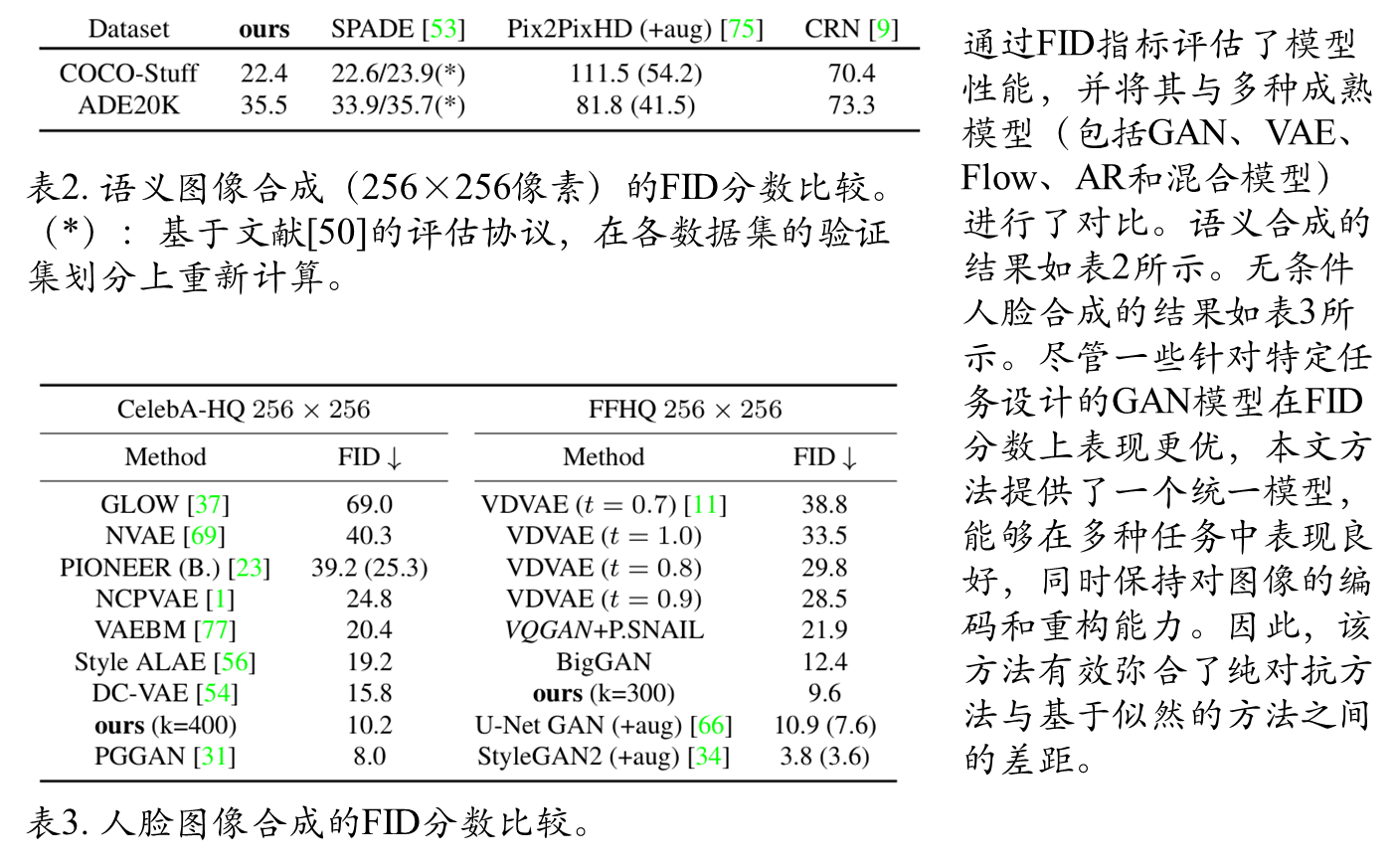
类条件合成FID分数对比

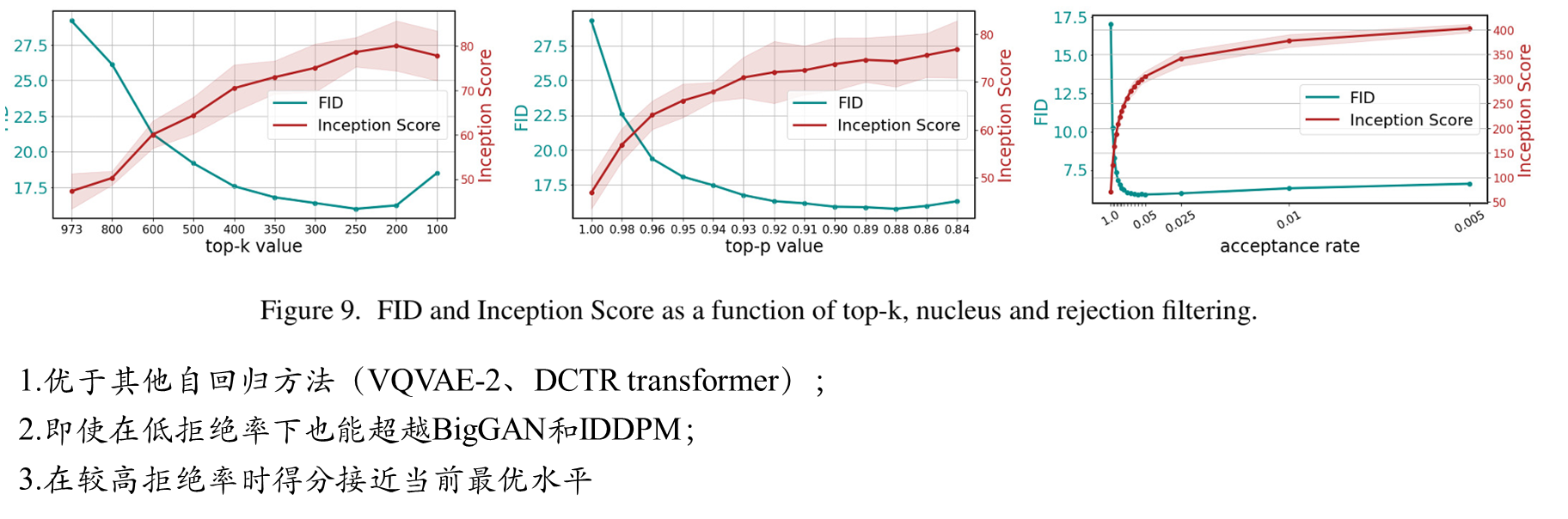
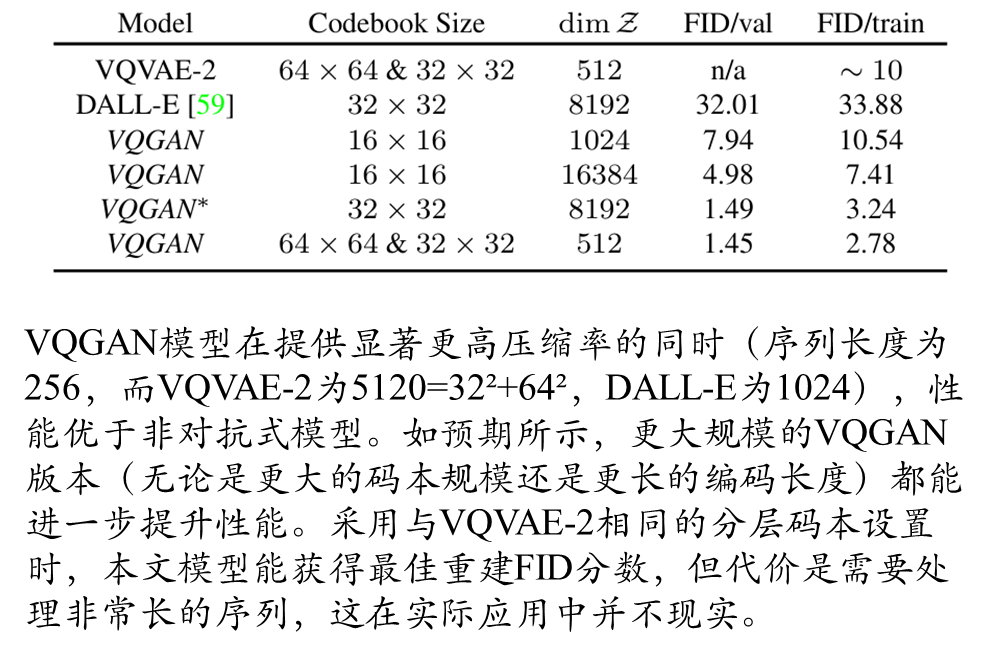
附件部分大家自己可以看一下。




















 2266
2266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









