




1 数据集
引用
import torch
from torch import nn ##nn创建神经网络
from torch.utils.data import DataLoader #DataLoader加载数据
from torchvision import datasets #datasets加载数据集
from torchvision.transforms import ToTensor #ToTensor将数据转换为张量
下载数据集
# 下载数据
training_data = datasets.MNIST(
root="data",
train=True,
download=True,
transform=ToTensor()
)
testing_data = datasets.MNIST(
root="data",
train=False,
download=True,
transform=ToTensor()
)
导入数据
# 加载数据
batch_size = 64
train_dataloader = DataLoader(training_data, batch_size=batch_size)
test_dataloader = DataLoader(testing_data, batch_size=batch_size)
# 打印第一个批次的数据形状
for X, y in train_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}")
print(f"Shape of y: {y.shape} {y.dtype}")
break
2 构建神经网络的方法
2.1 构建神经网络
定义神经网络类,继承自nn.Moudule
Pytorch使用nn.Sequentail对象创建神经网络
神经网络必须实现前向传播forward()方法
使用nn.Flatten对象将图片转成列列向量【对比Kares ,pytorch是面向对象的思路】
nn.to方法可以让模型运行在不同的硬件上
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
# 打印设备信息
print(f"Using {device} device")
# 构建神经网络 2层 输入28*28,第一层128个神经元,激活函数relu,第二层10个神经元
class NeunalNetwork(nn.Module):
def __init__(self):
super().__init__()
self.nmodel = nn.Sequential(
nn.Linear(28*28, 128), # 输入层到隐藏层
nn.ReLU(), # 激活函数
nn.Linear(128, 10) # 隐藏层到输出层
)
def forward(self, x):
x = nn.Flatten(1)(x) # 将输入展平
output = self.nmodel(x) #对模型训练
return output
model = NeunalNetwork().to(device)
print(model)
2.2 训练神经网络
指定model模式:train训练
循环读取小批量数据
进行训练:前向传播
通过损失函数计算本次的损失
损失函数:
回归:均方差nn.MESLoss、平均绝对差nn.L1Loss
多分类:交叉熵nn.CrossEntopyLoss 包含了softmax、nn.NULLLoss需手动添加softmax
反向传播,计算梯度
优化器:
SGD 随机梯度下降
Adam 最佳优化器
RMSprop
更新梯度
清空本次小批量梯度,确保每次小批次都重新计算梯度
loss_fn = nn.CrossEntropyLoss() # 交叉熵损失函数 多分类
optimizer = torch.optim.Adam(model.parameters(), lr=1e-3) # 随机梯度下降优化器
# 训练神经网络
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 数据集大小
model.train() # 设置模型为训练模式
train_correct, train_loss = 0, 0
for bacth, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) # 将数据移动到GPU/或CPU上
pred = model(X)
loss = loss_fn(pred, y)
loss.backward() # 反向传播后,计算出梯度
optimizer.step() # 使用优化器,更新参数
optimizer.zero_grad() # 清除本次梯度
train_loss += loss.item() # 获取损失
train_correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 计算正确率
if bacth % 100 == 0:
loss, current = loss.item(), bacth * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
train_loss /= len(dataloader) # 所有的损失/所有批次=平均损失
correct /= size # 所有的正确数/所以样本=平均正确率
print(f"Trian Error: \n Accuracy: {(100*train_correct):>0.1f}%, Avg loss: {train_loss:>8f} \n") # 打印平均正确率和平均损失
2.3 评估神经网络
指定model模式:eval训练
禁止梯度计算与跟踪,测试阶段不需要计算梯度
进行预测:前向传播
损失函数计算损失
# 评估神经网络
def test(dataLoader, model, loss_fn):
size = len(dataLoader.dataset) # 数据集大小
num_batches = len(dataLoader) # 获取批次数
model.eval() # 设置模型为评估模式
with torch.no_grad(): # 在评估时不需要计算梯度
for X, y in dataLoader:
X, y = X.to(device), y.to(device)
pred = model(X)
test_loss += loss_fn(pred, y).item() # 计算损失累加,需要张量转为python数值
correct += (pred.argmax(1) == y).type(torch.float).sum().item() # 获取64y样本最大可能性对比y,累加后,计算正确预测的数量
test_loss /= num_batches # 所有损失/所有批次=平均损失
correct /= size # 所有的正确数/所以样本=平均正确率
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n") # 打印平均正确率和平均损失
2.4 开始训练与评估
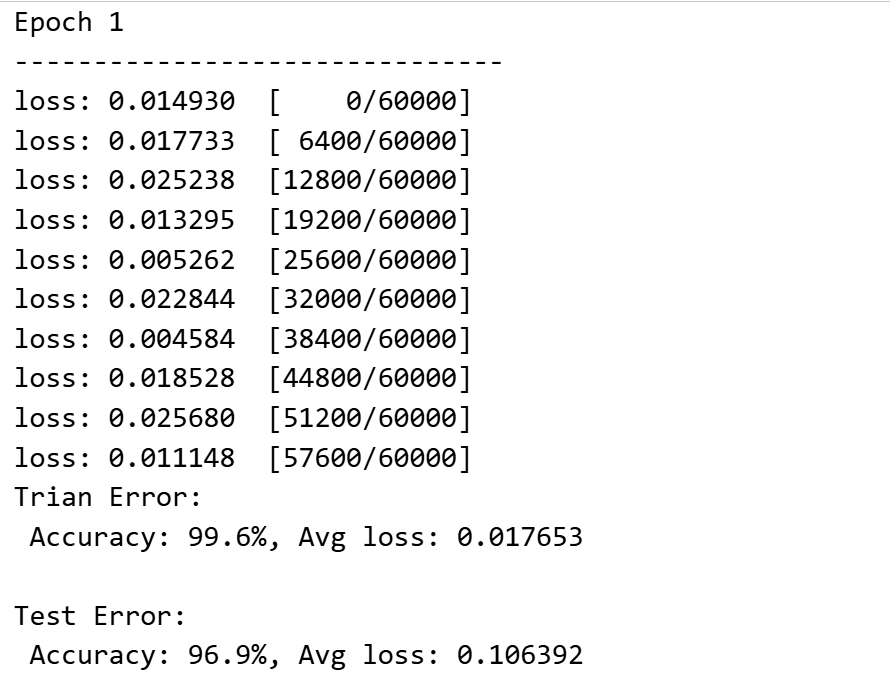
epochs = 5 # 训练轮数
for epoch in range(epochs):
print(f"Epoch {epoch+1}\n-------------------------------")
train(train_dataloader, model, loss_fn, optimizer) # 训练模型
test(test_dataloader, model, loss_fn) # 测试模型
print("Done!") # 训练完成
3 模型保存部署与使用
3.1 保存模型
# 部署模型:模拟在服务器上,将模型加载进来
saved_model = NeunalNetwork().to(device) # 将模型加载到设备上
model_weight_only=torch.load("model_weight.pth", weights_only=True) # 加载:已有的模型参数
saved_model.load_state_dict(model_weight_only) # 导入:将加载的参数应用到模型中
3.2 部署与使用
saved_model.eval() # 设置模型为评估模式
# 测试部署模型
x, y = next(iter(test_dataloader)) # 获取测试数据的第一个批次
# 获取测试数据的第一批次的第一个样本和标签
x, y = x.to(device), y.to(device) # 将数据移动到设备
with torch.no_grad(): # 在评估时不需要计算梯度
pred = saved_model(x) # 使用部署模型进行预测
print(f"Predicted: {pred.argmax(1)}") # 打印预测结果
print(f"Actual: {y}") # 打印实际标签
import matplotlib.pyplot as plt # 导入matplotlib库用于绘图
plt.imshow(x[0].cpu().numpy().squeeze(), cmap='gray') # 显示第一个测试样本的图像
plt.title(f"Predicted: {pred.argmax(1)[0].item()}, Actual: {y[0].item()}") # 设置图像标题
plt.axis('off') # 关闭坐标轴显示
plt.show() # 显示图像

4 评估与神经网络优化
优化点:增加层数
class NeunalNetwork(nn.Module):
def __init__(self):
super().__init__()
self.nmodel = nn.Sequential(
nn.Linear(28*28, 128), # 输入层到隐藏层
nn.BatchNorm1d(128), # 优化点:批归一化层
nn.ReLU(), # 激活函数
nn.Dropout(0.2), # 优化点:Dropout层,防止过拟合
nn.Linear(128, 10) # 隐藏层到输出层
)
def forward(self, x):
x = nn.Flatten(1)(x) # 将输入展平
output = self.nmodel(x) #对模型训练
return output
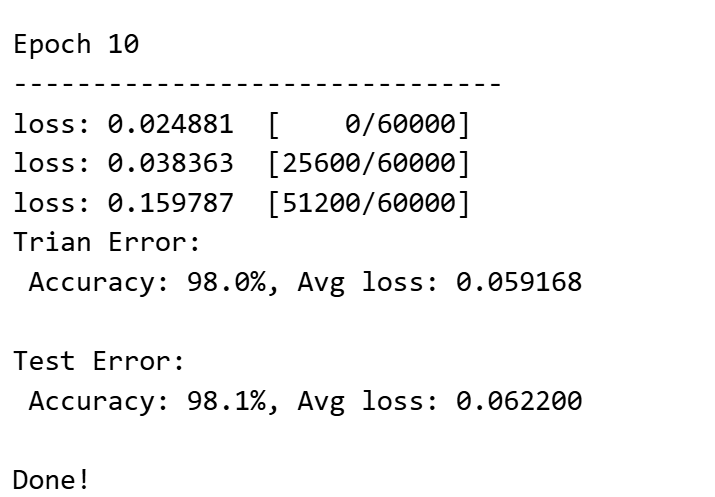
优化点:轮次、数据打乱、批次
epochs = 10 # 训练轮数加大 一般更优
batch_size = 64 # batch_size 变大 更稳定
# 加载数据 shuffle
train_dataloader = DataLoader(training_data, batch_size=batch_size, shuffle=True)

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









