




1 CNN网络基础
1.1 背景
CNN带来了哪些好处?
- 参数共享,相较于全连接,大大减少了学习参数量
- 稀疏连接,每个神经元只需要链接如数图像的一个局部
- 平移不变形,无论目标出现在图片哪里,filter都可以扫到
- 多层次特征提取,通过多层卷积和池化来实现
- CNN考虑空间关系适合处理图像,而全连接是一维的
主要用来做什么?
图像分类、目标检测、图像分割、超分(变清晰)、图像风格迁移、图像修复、图像生成
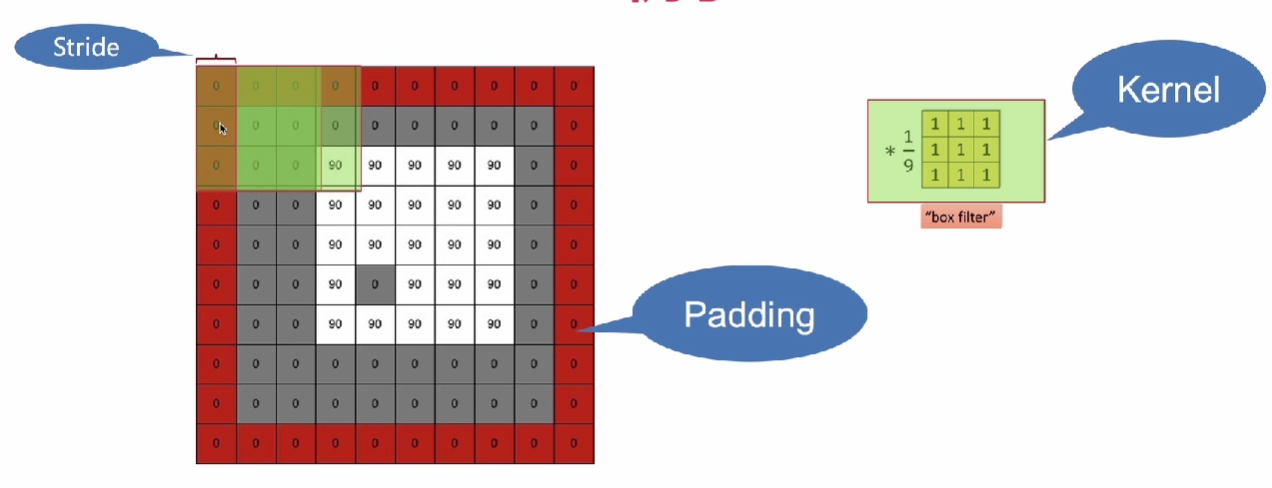
1.2 卷积操作
Kernel、Pading、Stride
- 传统计算机视觉:检测边缘需要自己定义kernel
- 深度学习:深度神经网络自己找到kernel:是通过用户传入的数据学习到的
Pading:为了让输出等于原图,在外围加一圈为0的padding
stride:在kernel原图上移动的距离,一般为1
输出维度
- n原图的宽和高
- f为kernel的大小
- p为padding填充的圈数
- s表示kernel跨度
- 计算结果向下取整
例如:原图8*8,kernal 3*3,padding1,stride1,则为 (8+2*1-3)/1 + 1 = 7+1=8
2.3 三维卷积与多核卷积
三维卷积
先乘法,再相加:三维变成一维
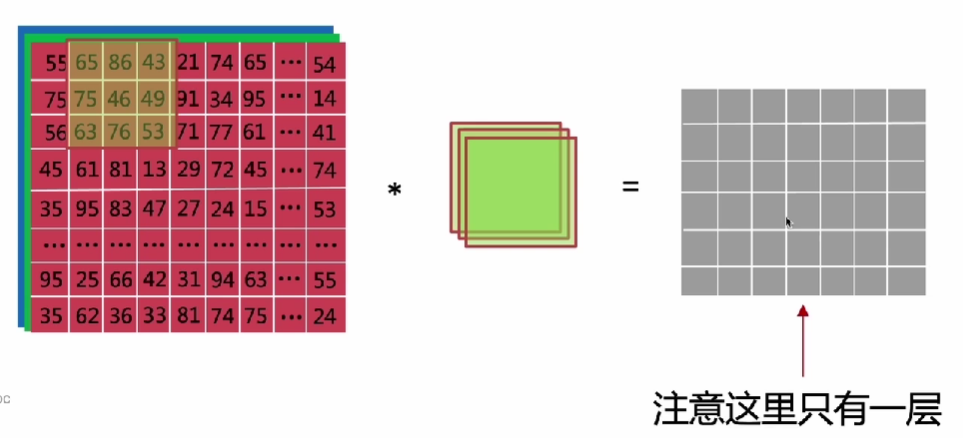
多核卷积
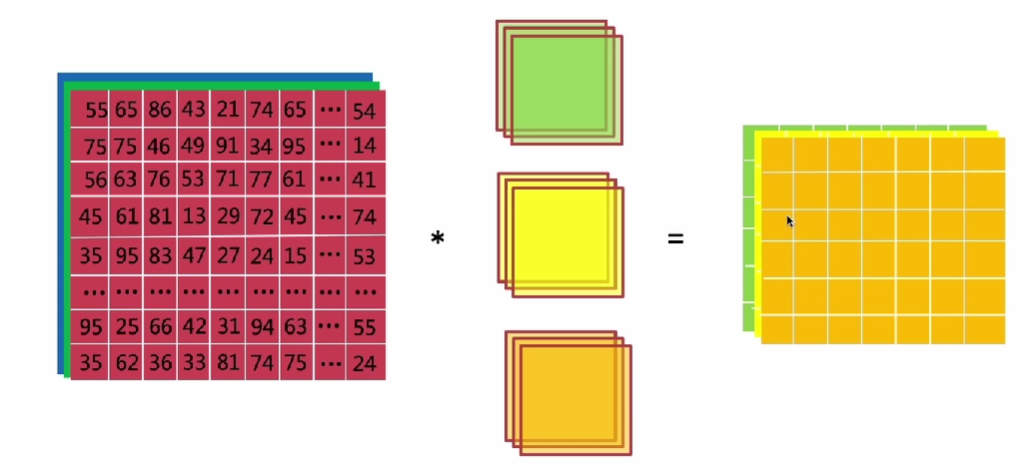
卷积过程
- 每个核卷出一个二维数据 :w·a
- 对于二维数据中的每一项加入偏置d: z=w·a+b
- 放入relu激活函数中:g(z)
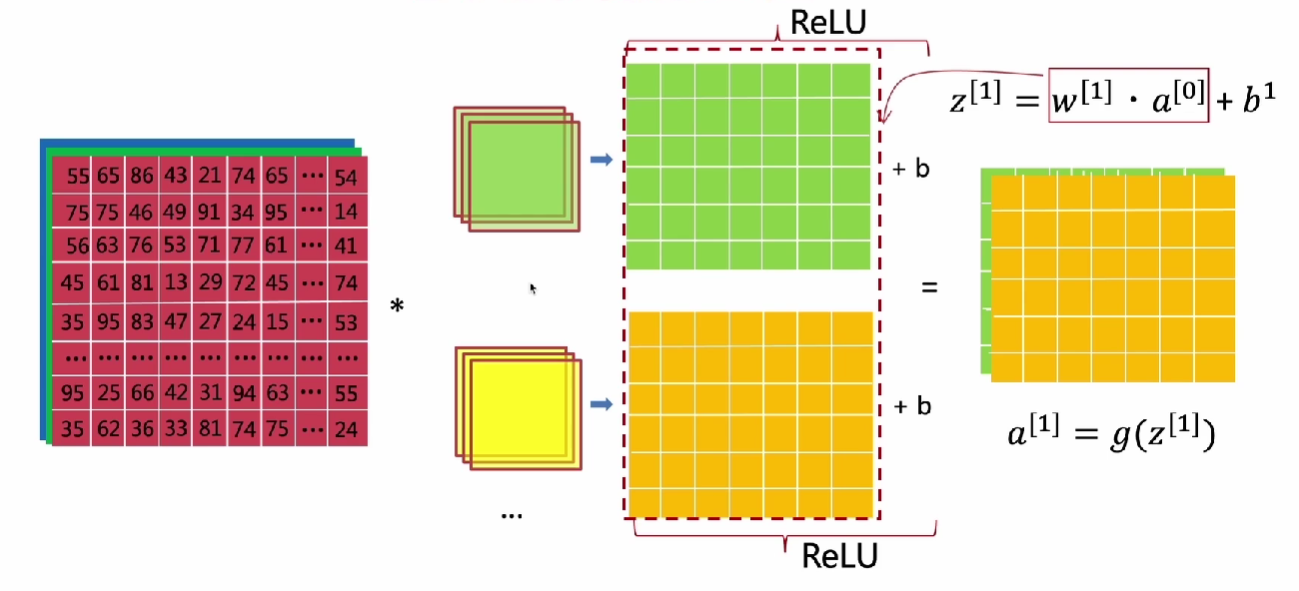
符号
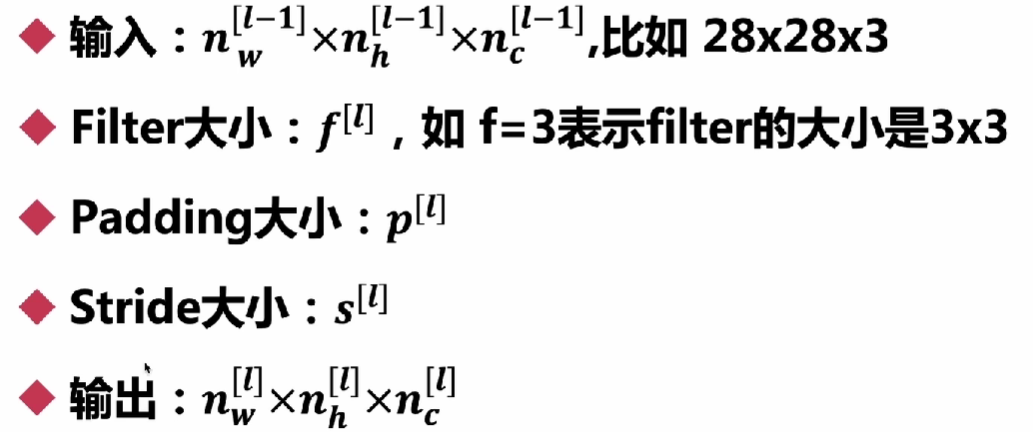

1.3 池化操作
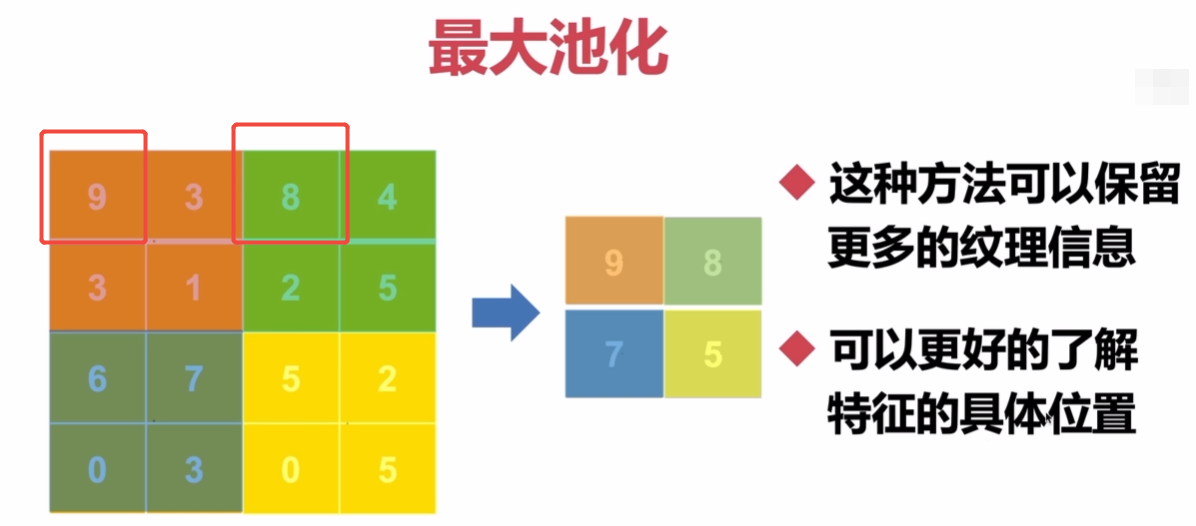
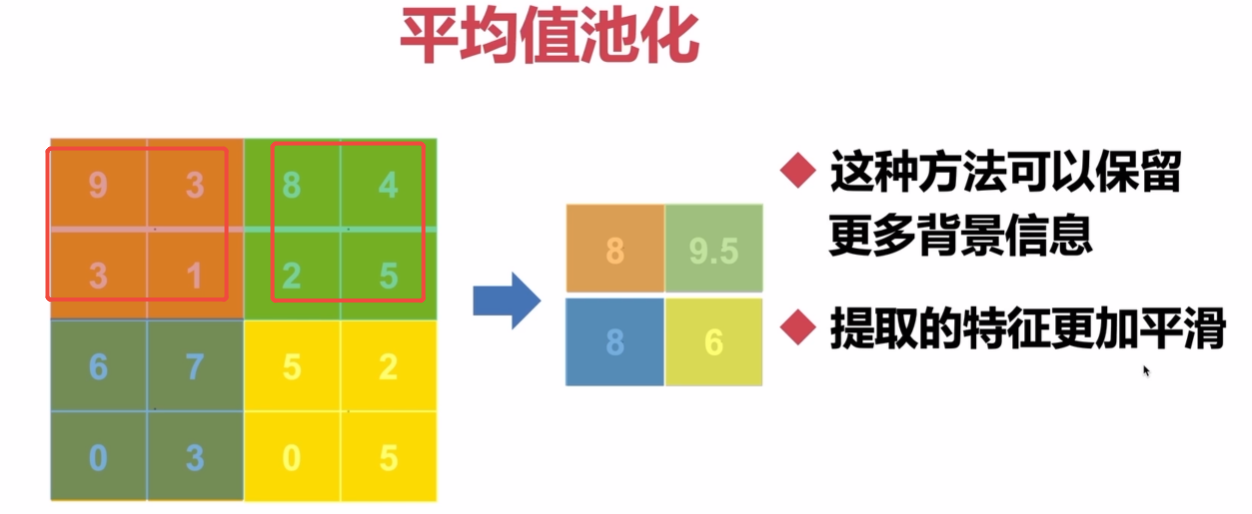
目的:减少特征图的大小,降低计算量和参数数量,同时保留重要特征
好处:降低计算量、防止过拟合(减少特征尺寸->降低模型复杂度)
什么时候:卷积后使用池化
种类:最大值池化,平均值池化
2 标准的卷积网络CNN
标准流程 / 层
卷积层 - CONV -Convolution
池化层 - POOL - Pooling
全连接层 - PC - Fully Connected
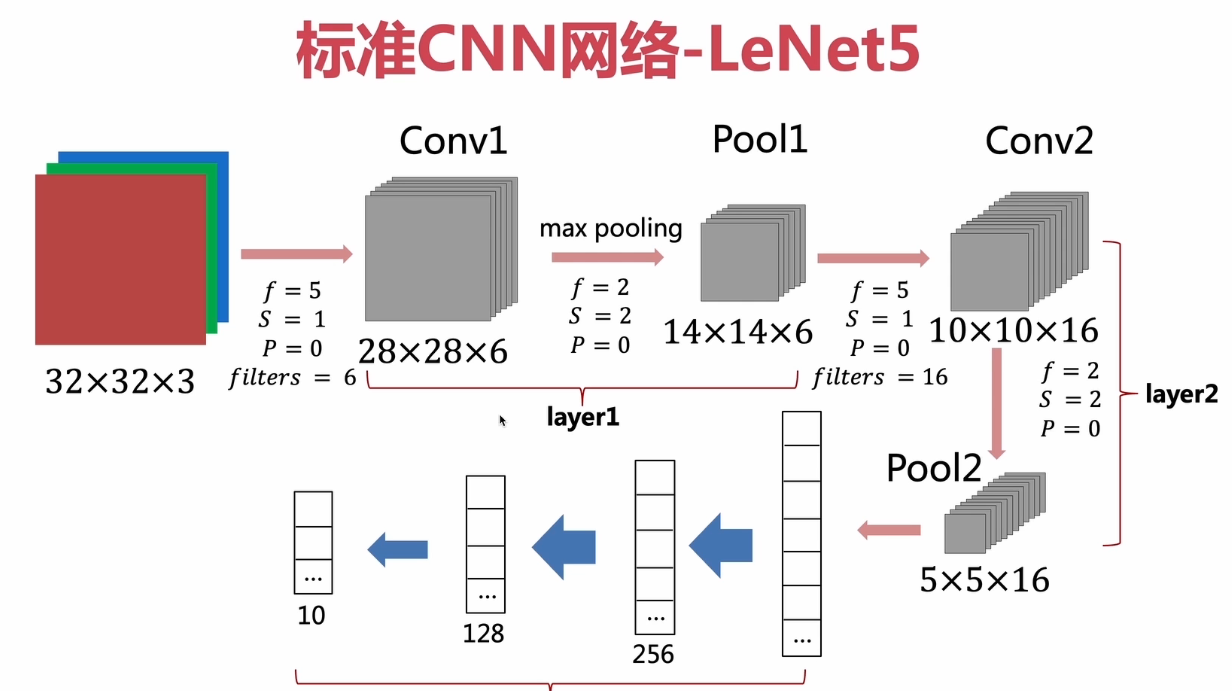
LeNet5(经典)
Pytorch实现网络(基于全连接网络进行修改)
# 构建神经网络 2层 输入28*28,第一层128个神经元,激活函数relu,第二层10个神经元
class NeunalNetwork(nn.Module):
def __init__(self):
super().__init__()
self.nmodel = nn.Sequential(
# layer 1 卷积层
nn.Conv2d(1, 32, 3),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(2, 2), # 池化层,减少特征图的尺寸
# layer 2 卷积层
nn.Conv2d(32, 64, 3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2, 2), # 池化层,减少特征图的尺寸
# 全连接层
nn.Flatten(), # 卷积后的结果转为列向量,作为参赛传给全连接
nn.Linear(5*5*64, 128), # 输入层到隐藏层
nn.BatchNorm1d(128), # 优化点:批归一化层
nn.ReLU(), # 激活函数
nn.Dropout(0.2), # 优化点:Dropout层,防止过拟合
nn.Linear(128, 10) # 隐藏层到输出层
)
def forward(self, x):
# x = nn.Flatten(1)(x) # 将输入展平
output = self.nmodel(x) #对模型训练
return output
model = NeunalNetwork().to(device)
print(model)

训练结果明细优于全接连
经典CNN架构
LeNet5(经典)
作者:深度学习三剑客的杨丽坤
2个卷积层、3个全连接层
使用平均池化、
使用MNIST数据集,较小
AlexNet 2012
ImageNet 2012 冠军、作者:辛顿团队2个学生
- 5个卷积层、3个全连接层:对比LeNet5 网络规模更大
- 开始使用激活函数Relu
- 开始使用Dropout正则化
- 开始使用最大值池化
- 开始使用数据增强技术:图像平移、翻转、裁剪
- 使用ImageNet大型数据集
- 开始使用多GPU训练
——AlexNet 算法的改进、ImageNet数据的革命、算力由英伟达引领

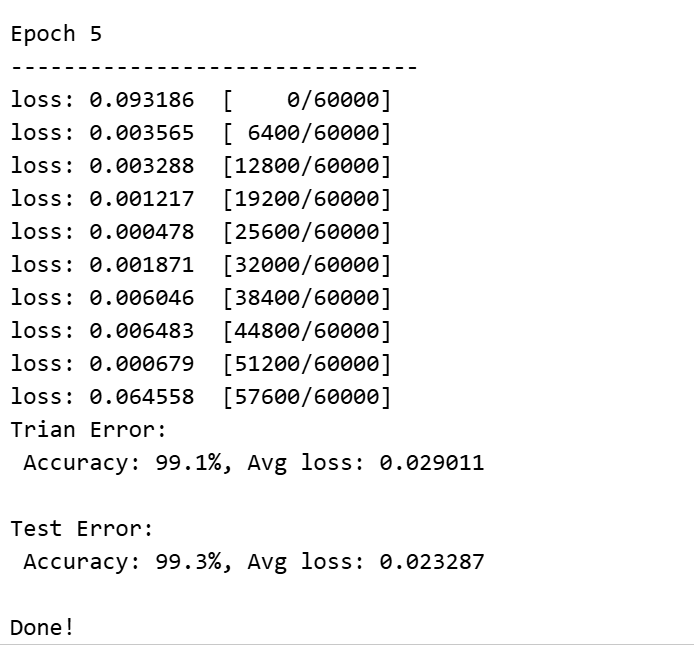
VGGNet 2014
作者:英国剑桥
使用多个3*3卷积核替代AlexNet的大卷积核
具有大卷积核相关的视野,同时参数大幅减少
具有更深层次VGG-16 VGG-19,小卷积核支持构建更深网络
更深网络可以学习更复杂的特征,性能更优
网络结构更简单一致、都是3*3卷积 + 2*2最大池化
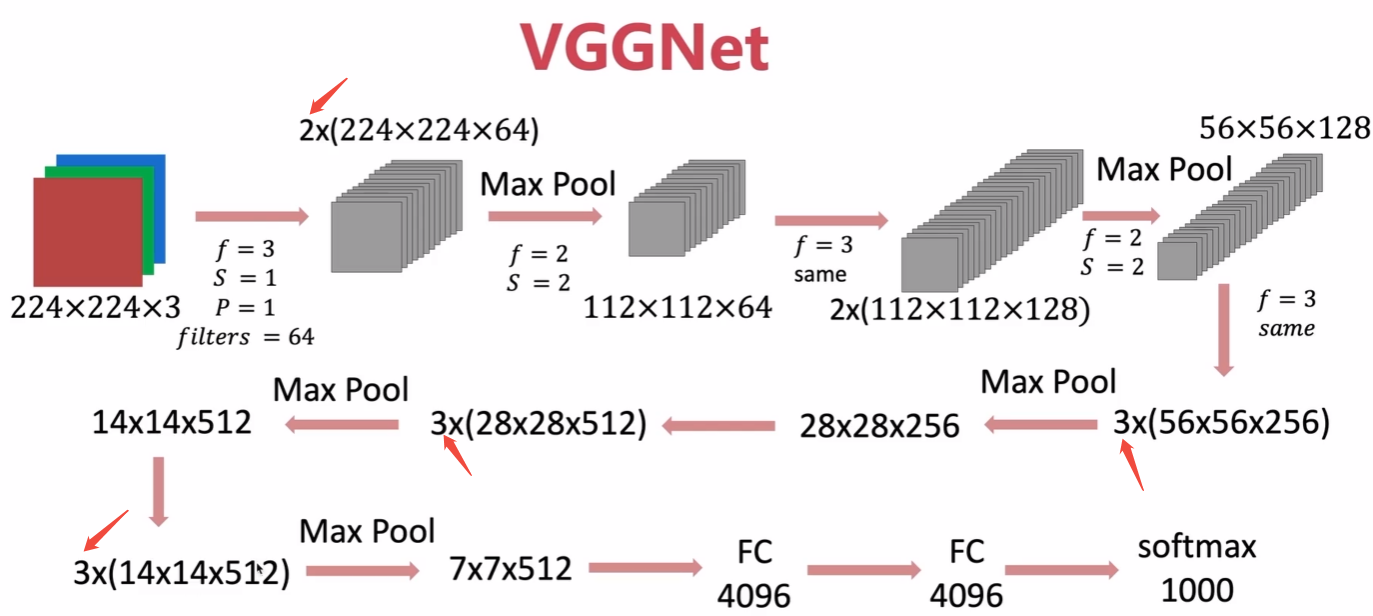
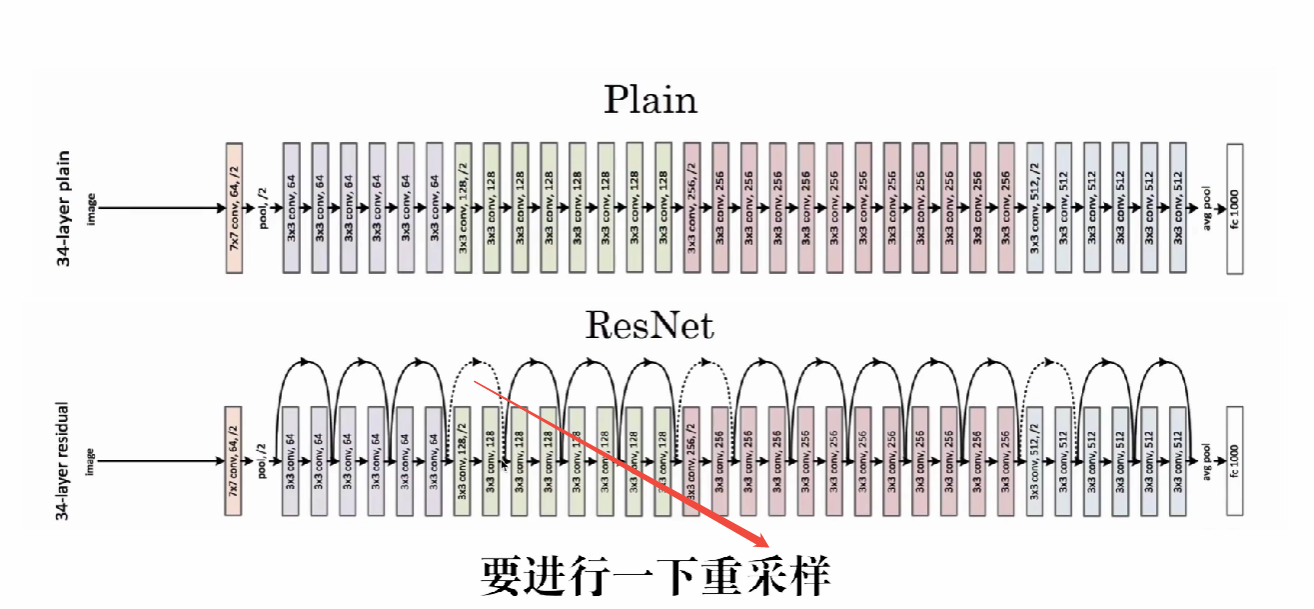
ResNet
作者:微软研究院何等人
- 解决深度网络梯度消失与爆炸问题
- 可以让神经网络达到上百层甚至上千层
- 即使残差函数学习的权重是0,仍可以表现像一个恒等映射,从而保障训练更深的网络时,性能不会退化
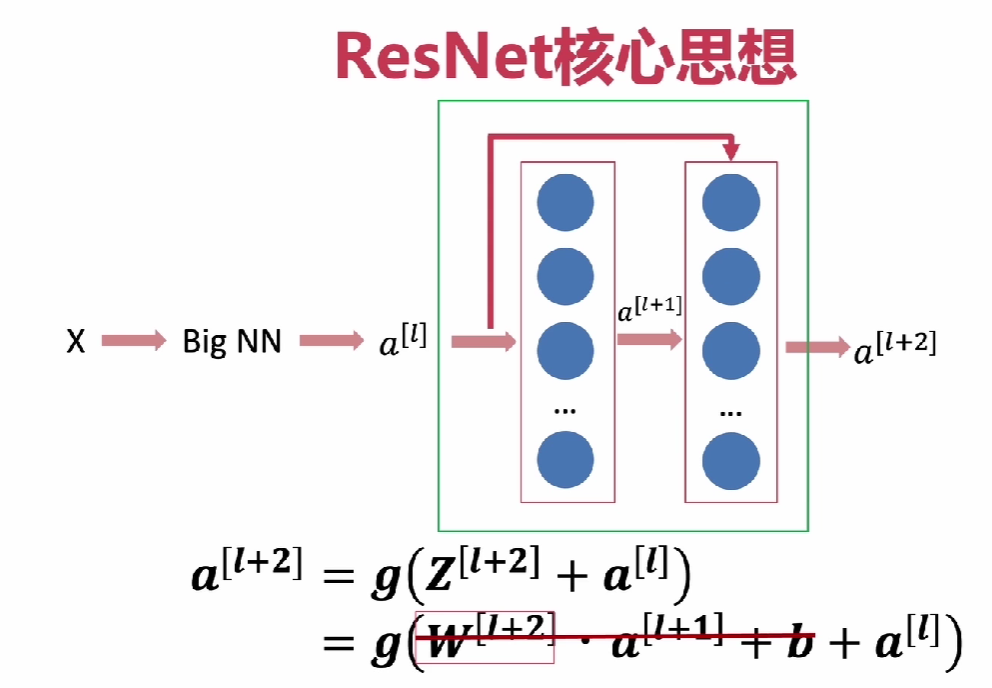
ResBlock


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









