




 Wide&Deep模型通过结合线性模型(Wide部分)和深度神经网络(Deep部分)来提升推荐系统的性能。Wide部分利用关联规则记忆用户商品共现性,如用户购买尿布常伴随啤酒的推荐;Deep部分通过Embedding和全连接网络挖掘用户潜在兴趣,如根据足球视频推荐C罗视频。模型最终通过Joint Training优化,使用Sigmoid函数压缩输出并以Logistic Loss进行训练。
Wide&Deep模型通过结合线性模型(Wide部分)和深度神经网络(Deep部分)来提升推荐系统的性能。Wide部分利用关联规则记忆用户商品共现性,如用户购买尿布常伴随啤酒的推荐;Deep部分通过Embedding和全连接网络挖掘用户潜在兴趣,如根据足球视频推荐C罗视频。模型最终通过Joint Training优化,使用Sigmoid函数压缩输出并以Logistic Loss进行训练。
1、介绍
Wide & Deep模型的出发点是兼顾模型的记忆能力和泛化能力,下面解释一下这两者的含义。
- 记忆 (Memorization):指的是模型记住商品共现性的能力。举个例子,一个父亲逛淘宝通常会同时买尿布和啤酒,这就体现了商品的共现性。购买的次数多了,当模型看到尿布,自然会给用户推荐啤酒,这就是模型的记忆能力。
- 泛化( Generalization)能力:只是的模型挖掘用户潜在喜好的能力。比方说,你经常刷足球类的短视频,软件就会根据足球去联想,你是不是有可能喜欢C罗呢?然后软件就会尝试给你推荐C罗的视频,这就体现了模型的泛化能力。
在Wide & Deep论文中,由线性模型加上人工设计的关联规则,来负责记忆(Memorization),称为Wide部分;由深层神经网络来负责泛化( Generalization),称为Deep部分。
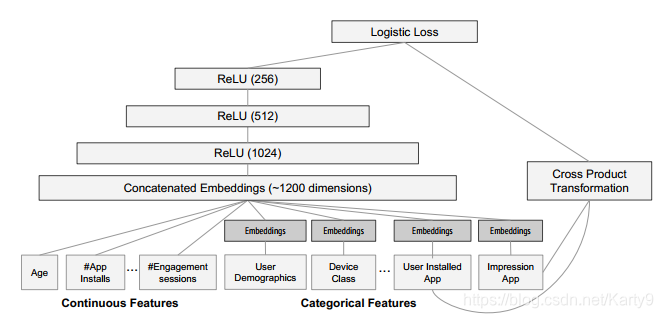
2、Wide
广义线性模型的表达式是:
y=wTx+b
y=w^Tx+b
y=wTx+b
其中,xxx表示特征向量。然后WideWideWide部分定义了一个关联规则,用它来表示特征之间的共现性:
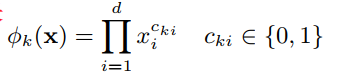
关联规则的具体表示是:只有当iii特征和kkk特征同时为1时,ckic_{ki}cki才为1,否则为0。文中选择的特征是“用户下载的APP”和“用户感兴趣的APP”。
3、Deep
DeepDeepDeep部分,首先会把稀疏的原始向量经过EmbeddingEmbeddingEmbedding层,得到稠密向量,然后再经过全连接网络,进行特征交叉,提取高阶特征:
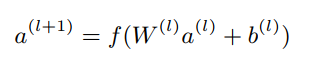
4、Join Training
最后,我们把WideWideWide部分和DeepDeepDeep部分的输出加在一起,经过一个SigmoidSigmoidSigmoid函数,把输出压缩到01之间,最后用LogisticLogisticLogistic LossLossLoss进行训练。
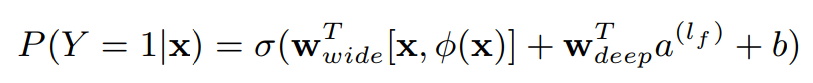

















 572
572

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









