




 本文介绍了Attentional Factorization Machines (AFM),它将注意力机制应用于Factorization Machines,解决了特征重要性的问题。AFM通过注意力权重调整特征组合的影响,其网络结构包括Embedding Layer、Pair-wise Interaction Layer和Attention-based Pooling。模型的输出结合了所有特征及其交互的注意力加权,损失函数采用了均方误差损失。
本文介绍了Attentional Factorization Machines (AFM),它将注意力机制应用于Factorization Machines,解决了特征重要性的问题。AFM通过注意力权重调整特征组合的影响,其网络结构包括Embedding Layer、Pair-wise Interaction Layer和Attention-based Pooling。模型的输出结合了所有特征及其交互的注意力加权,损失函数采用了均方误差损失。
引言
本篇文章介绍的是Attentional Factorization Machines(AFM)。AFM开创性地将注意力机制引入到因子分解机(Factorization Machines)中,可视为FM和NFM的延续之作,这两个模型在前面博客中已经进行了介绍,有兴趣的读者可以点击蓝色链接进行深入了解。
简单回顾一下,FM使用两个隐向量的内积来表示一对特征组合的权重,增强了模型的泛化性;NFM为了弥补FM中特征交叉阶数有限的缺点,引入深度神经网络(DNNs)构建交叉特征,并提出了一种新的特征交叉操作。
概括来说,NFM基于因子分解机的框架,在单纯的特征交叉方面已经做到了力所能及的最大限度。 而AFM解决的是特征交叉过程中的一个痛点,哪些特征是重要的?哪些特征是不重要的?这个问题FM和NFM都回答不了。解决的方法在今天看来也很简单,但是在当时是巨大的飞跃:通过引入注意力机制,对特征组合赋予注意力权重的方式,就可以让重要的特征发挥更显赫的作用。
Attentional Factorization Machines
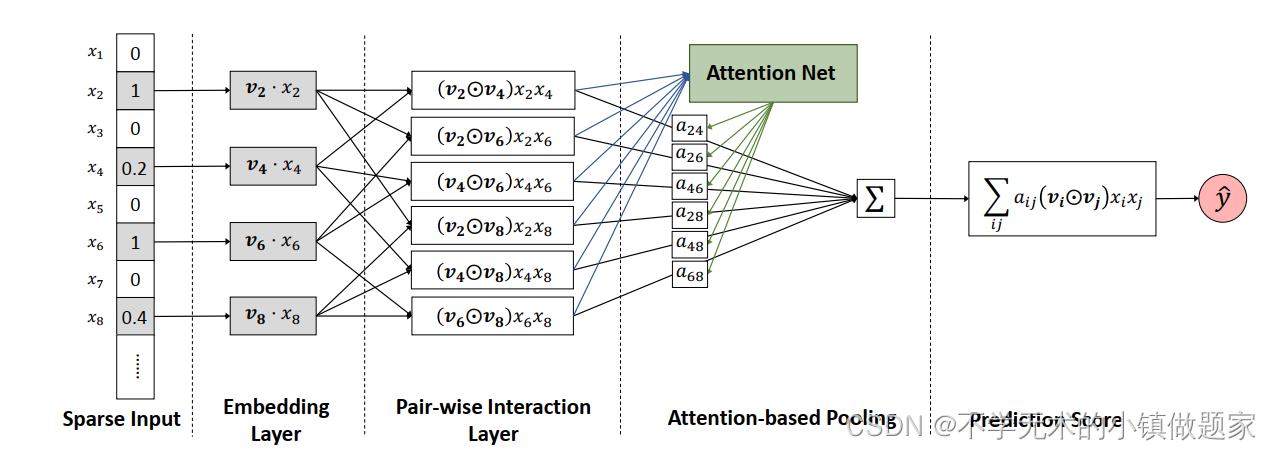
上图是AFM的网络结构图。Embedding Layer层的作用是把高维的稀疏编码转换为低维的稠密向量。Pair-wise Interaction Layer引入了基于特征对的特征交叉操作,而Attention-based Pooling则为特征交叉提供注意力机制的权重预测,用公式表达如下:
f A t t ( f P I ( X ) ) = ∑ ( i , j ) ∈ R x a i j ( v i ⊙ v j ) x i x j f_{Att}(f_{PI}(X)) = \sum_{(i,j)∈R_x}a_{ij}(v_i⊙v_j)x_ix_j fAtt(fPI(X))=(i,j)∈Rx∑aij(vi⊙vj)x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 557
557

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









