






 文章探讨了优化算法在深度学习中的应用,包括动量法解决梯度下降的病态曲率问题,以及AdaGrad、RMSProp和Adam等自适应梯度算法的原理和优缺点。此外,还介绍了卷积神经网络的基础,如LeNet-5网络的结构和特点。
文章探讨了优化算法在深度学习中的应用,包括动量法解决梯度下降的病态曲率问题,以及AdaGrad、RMSProp和Adam等自适应梯度算法的原理和优缺点。此外,还介绍了卷积神经网络的基础,如LeNet-5网络的结构和特点。
4 性能优化
4.1 动量法
4.1.1 病态曲率问题
图为损失函数轮廓。在进入以蓝色标记的山沟状区域之前随机开始。颜色实际上表示损失函数在特定点处的值有多大,红色表示最大值,蓝色表示最小值。我们想要达到最小值点,为此但需要我们穿过山沟。这个区域就是所谓的病态曲率。
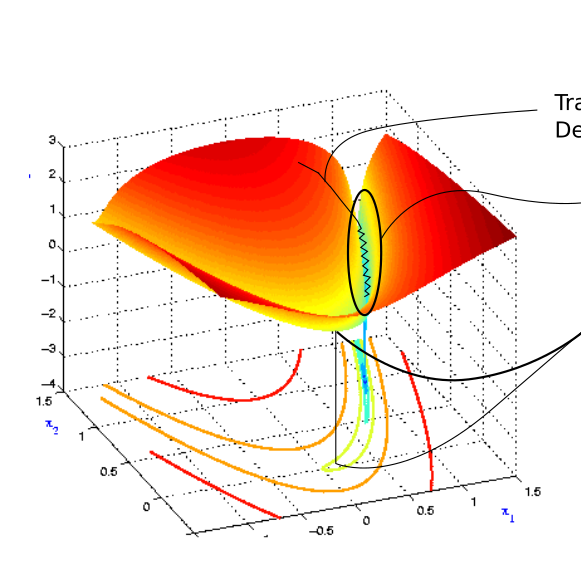
梯度下降沿着山沟的山脊反弹,向极小的方向移动较慢。这是因为脊的表面在W1方向上弯曲得更陡峭。

如果把原始的 SGD 想象成一个纸团在重力作用向下滚动,由于质量小受到山壁弹力的干扰大,导致来回震荡;或者在鞍点处因为质量小速度很快减为 0,导致无法离开这块平地。
动量方法相当于把纸团换成了铁球;不容易受到外力的干扰,轨迹更加稳定;同时因为在鞍点处因为惯性的作用,更有可能离开平地。
4.1.2 动量法
动量法更新公式:
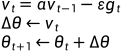
算法流程如下:

4.2 自适应梯度算法
4.2.1 AdaGrad
Adaptive Gradient:自适应梯度
参数自适应变化:具有较大偏导的参数相应有一个较大的学习率,而具有小偏导的参数则对应一个较小的学习率
具体来说,每个参数的学习率会缩放各参数反比于其历史梯度
算法流程:

存在问题:
学习率是单调递减的,训练后期学习率过小会导致训练困难,甚至提前结束
需要设置一个全局的初始学习率
4.2.2 RMSProp
RMSProp: Root Mean Square Prop
RMSProp 解决 AdaGrad 方法中学习率过度衰减的问题
RMSProp 使用指数衰减平均以丢弃遥远的历史,使其能够快速收敛;此外,RMSProp 还加入了超参数 𝜌 控制衰减速率。
具体来说(对比 AdaGrad 的算法描述),即修改 𝑟 为
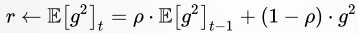
记
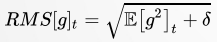
则
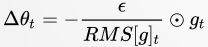
算法流程:

4.2.3 Adam
Adam算法
Adam 在 RMSProp 方法的基础上更进一步:
➢ 除了加入历史梯度平方的指数衰减平均(𝑟)外,
➢ 还保留了历史梯度的指数衰减平均(𝑠),相当于动量。
Adam 行为就像一个带有摩擦力的小球,在误差面上倾向于平坦的极小值。
算法流程:

4.3 性能优化问题描述
4.3.1 待解决问题
权值𝐰取何值,指标函数𝐽(𝐰)最小?
恰恰是最优化方法中的基本问题:函数最小化。
进一步,我们希望建立迭代形式,并且形式尽量简单,类似基本BP算法(最速梯度法):

如何选取 、
、 构成优化核心内容
构成优化核心内容
4.3.1基本思想
考虑函数𝑓(𝑥), 在某点𝑥∗上进行Taylor展开,
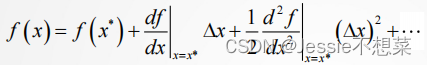
考虑函数𝑓(𝐱),在某点𝐱∗展开,类似的,有
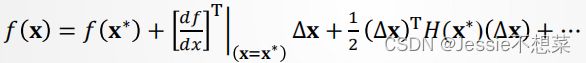
或形象化记法:
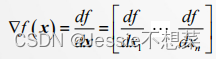

全局极小点, 局部极小点
◼ 一阶条件:必要条件𝛻𝑓 (𝐱∗)= 0 (驻点)
◼ 二阶条件:充分条件 H半正定
鞍点:沿某方向是极大值点,沿另一方向是极小值。
前面讲述:二次型近似任意函数
进一步 :某一算法是有效的<->对二次型应该有好的效果
所以:一般以二次型函数为例进行优化
5 卷积神经网络基础
5.1 深度学习平台介绍
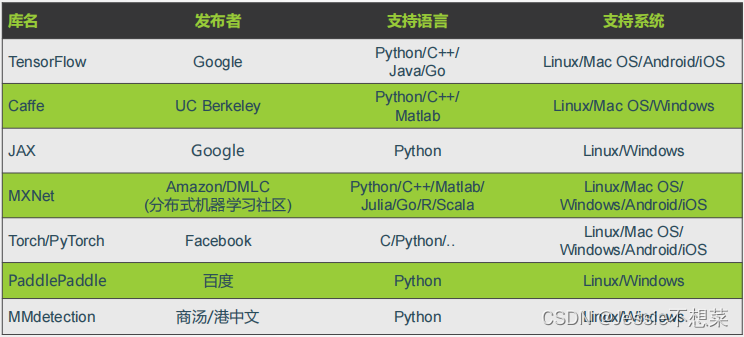
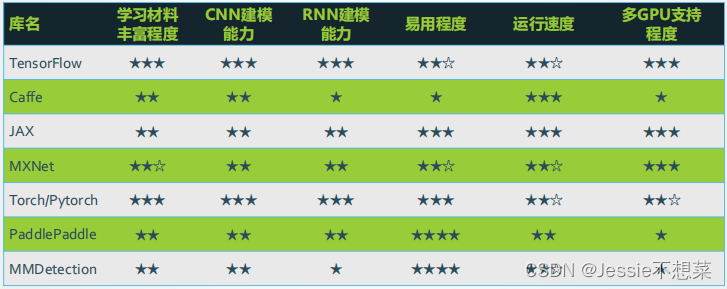
5.2.1 进化史




5.2.2 基本概念
全连接网络:链接权过多,难算难收敛,同时可能进入局部极小值,也容易产生过拟合问题
e.g. 输入为96x96图像,要学习100个特征
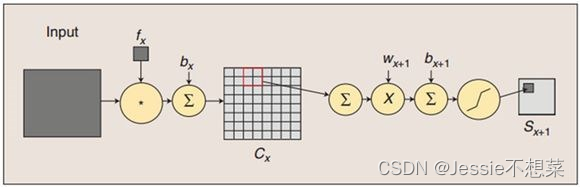
局部连接网络:顾名思义,只有一部分权值连接。部分输入和权值卷积。
填充(Padding):在矩阵的边界上填充一些值,以增加矩阵的大小,通常用0或者复制边界像素来进行填充。
步长(Stride):略
多通道卷积:如RGB
思想:使用局部统计特征,如均值或最大值。解决特征过多问题
构成:由多个卷积层和下采样层构成,后面可连接全连接网络
卷积层:k个滤波器
下采样层:采用mean或max
后面:连着全连接网络
5.3 LeNet-5网络
5.3.1 网络介绍
网络提出:

网络结构
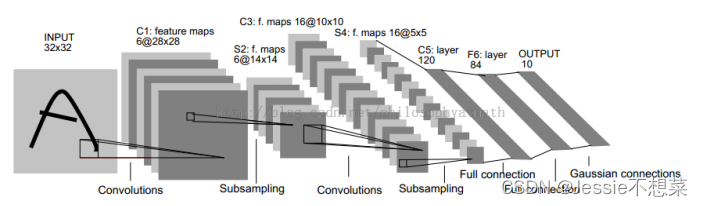
5.3.2 结构详解
C1层:
6个Feature map构成
每个神经元对输入进行5*5卷积
每个神经元对应5*5+1个参数,共6个feature map,28*28个神经元,因此共有(5*5+1)*6*(28*28)=122,304连接
S2层(Pooling层):
C3层(卷积层):
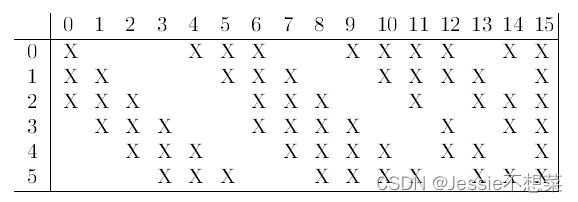
S4层:与S2工作相同
C5层:
120个神经元
每个神经元同样对输入进行5*5卷积,与S4全连接
总连接数(5*5*16+1)*120=48120
F6层
84个神经元
与C5全连接
总连接数(120+1)*84=10164
输出层
由欧式径向基函数单元构成
每类一个单元
输出RBF单元计算输入向量和参数向量之间的欧式距离
网络结构:
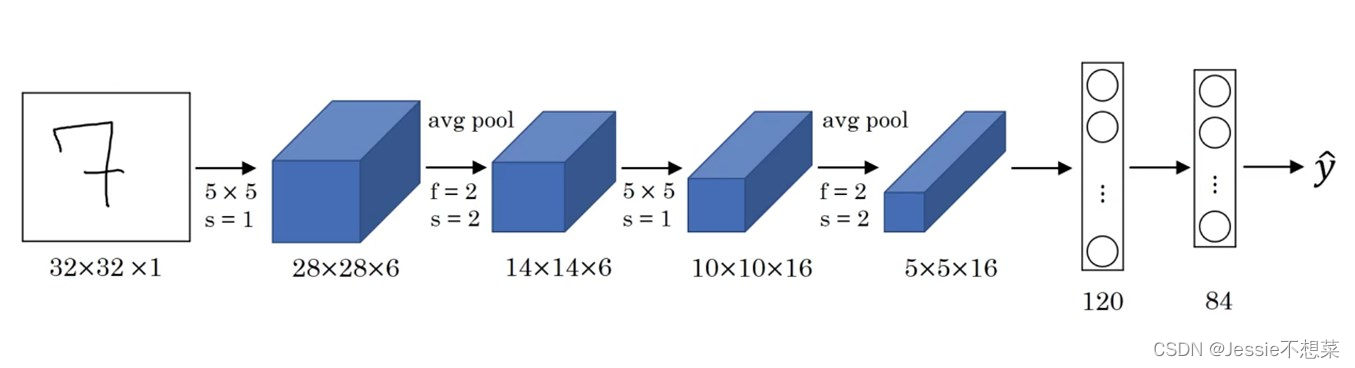
网络说明:
与现在网络的区别
卷积时不进行填充(padding)
池化层选用平均池化而非最大池化
选用Sigmoid或tanh而非ReLU作为非线性环节激活函数
层数较浅,参数数量小(约为6万)
普遍规律
随网络深入,宽、高衰减,通道数增加

















 125
125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









