






[目录]
0.行文概述
1.Policy Gradient
2.Proximal Policy Optimization
3.总结
0. 行文概述
策略梯度算法是一种强化学习方法,属于策略优化的范畴。它的目标是直接优化智能体的策略,使得智能体在环境中获得的累积奖励最大化。策略梯度算法的核心思想是通过调整策略的参数,使得智能体在决策过程中更倾向于选择那些能够带来更高回报的动作。
PPO(Proximal Policy Optimization)是一种强化学习算法,属于策略梯度方法的一种改进版本。它旨在解决传统策略梯度方法(如REINFORCE)在训练过程中容易出现的样本效率低、训练不稳定等问题。PPO通过引入一些改进机制,使得算法在训练过程中更加高效和稳定。该算法由OpenAI在2017年提出,此处为OpenAI原论文链接。
本文详细地介绍了策略梯度算法和PPO的基本概念并逐步完成了算法的推导过程。个人认为该算法对数学的要求并不算太高,只需要掌握基本的概率统计知识(如求期望、大数定律等等)。
本文的写作依据主要是原论文以及零基础学习强化学习算法。
【强化学习入门】系列主要是喜提双项目的某大二本科生在学习强化学习时的笔记、思路和心得。
1.Policy Gradient
1.1 必备概念
在正式开始推导之前,我们还是先用一张图来回顾一下强化学习最重要的宏观五要素。
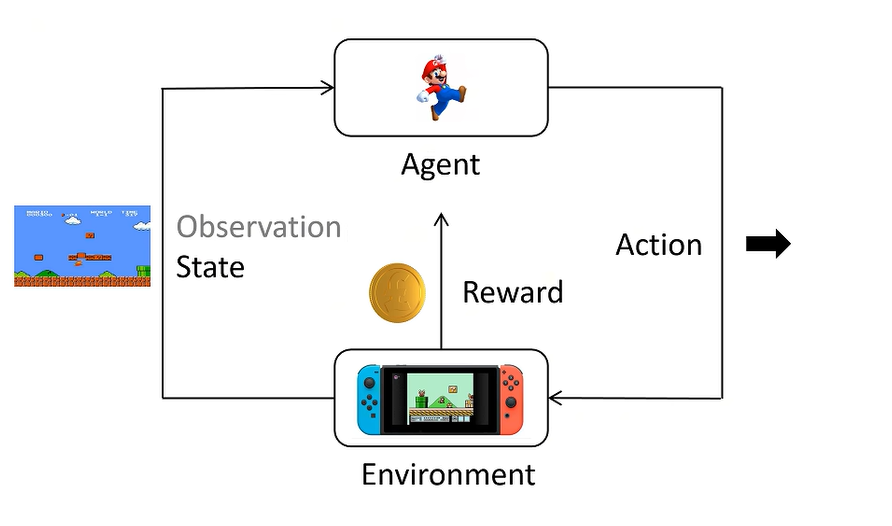
并且再强调一下我们需要用到的概念:
- Policy: 策略函数,输入State,输出Action的概率分布。一般用 π \pi π 表示。
π ( left ∣ s t ) = 0.1 π ( up ∣ s t ) = 0.2 π ( right ∣ s t ) = 0.7 \begin{align*} \pi(\text{left} \mid s_t) &= 0.1 \\ \pi(\text{up} \mid s_t) &= 0.2 \\ \pi(\text{right} \mid s_t) &= 0.7 \end{align*} π(left∣st)π(up∣st)π(right∣st)=0.1=0.2=0.7
-
Action Space: 可选择的动作,比如 { left , up , right } \{ \text{left}, \text{up}, \text{right} \} {left,up,right}
-
Trajectory: 轨迹, 用 τ \tau τ 表示,一连串状态和动作的序列。 { s 0 , a 0 , s 1 , a 1 , … } \{s_0, a_0, s_1, a_1, \ldots\} {s0,a0,s1,a1,…}。有时也表示为Episode, Rollout。 下面的式子给出了两种状态转移的情况:确定的状态转移(比如马里奥被逼入了死胡同只能后退)和随机的状态转移(大部分时候马里奥都能自由选择上窜还是下跳)。
s t + 1 = f ( s t , a t ) 确定 s_{t+1} = f(s_t, a_t) \text{ 确定} st+1=f(st,at) 确定
s t + 1 = P ( ⋅ ∣ s t , a t ) 随机 s_{t+1} = P(\cdot \mid s_t, a_t) \text{ 随机} st+1=P(⋅∣st,at) 随机
- Return: 回报,从当前时间点到游戏结束的Reward的累积和。
1.2 正式的推导过程
回顾一下,我们建立一个强化学习模型,最终极的目标是什么?——最大化收集到的总Reward!
因为我们已经引入了Return的概念,所以我们不妨换一种表示:训练一个神经网络 π \pi π,在所有状态 S S S给定 Action \text{Action} Action的情况下,得到 Return \text{Return} Return的期望最大。
又因为我们引入了Trajectory( τ \tau τ)的概念,所以我们最终表达为:训练一个神经网络 π \pi π,在 Trajectory \text{Trajectory} Trajectory中,得到 Return \text{Return} Return的期望最大。
为了防止读者在这一步出现理解上的问题:
最大化总Reward
≡
最大化Return期望
\text{最大化总Reward} \equiv \text{最大化Return期望}
最大化总Reward≡最大化Return期望
在此处我们可以稍微解释一下两者的数学等价性:
-
总Reward是单条轨迹的累积奖励,而期望是对所有可能轨迹的加权平均。
-
最大化期望等价于在所有可能的随机路径中,选择平均表现最好的策略。
我们继续进行推导。在
Trajectory
\text{Trajectory}
Trajectory中,得到
Return
\text{Return}
Return的期望最大现在是我们的目标函数,其数学表示为:
E
(
R
(
τ
)
)
τ
∼
P
θ
(
τ
)
=
∑
τ
R
(
τ
)
P
θ
(
τ
)
E(R(\tau))_{\tau \sim P_{\theta}(\tau)} = \sum_\tau R(\tau)P_{\theta}(\tau)
E(R(τ))τ∼Pθ(τ)=τ∑R(τ)Pθ(τ)
公式中的
θ
\theta
θ为神经网络的参数,而
R
(
τ
)
R(\tau)
R(τ)则表示选择某条轨迹的回报。为了最大化
E
(
R
(
τ
)
)
τ
∼
P
θ
(
τ
)
E(R(\tau))_{\tau \sim P_{\theta}(\tau)}
E(R(τ))τ∼Pθ(τ),我们对 参数
θ
\theta
θ 求梯度:
∇
E
(
R
(
τ
)
)
τ
∼
P
θ
(
τ
)
=
∇
∑
τ
R
(
τ
)
P
θ
(
τ
)
=
∑
τ
R
(
τ
)
∇
P
θ
(
τ
)
=
∑
τ
R
(
τ
)
∇
P
θ
(
τ
)
P
θ
(
τ
)
P
θ
(
τ
)
=
∑
τ
P
θ
(
τ
)
R
(
τ
)
∇
P
θ
(
τ
)
P
θ
(
τ
)
=
∑
τ
P
θ
(
τ
)
R
(
τ
)
∇
P
θ
(
τ
)
P
θ
(
τ
)
\begin{align*} \nabla E(R(\tau))_{\tau \sim P_\theta(\tau)} &= \nabla \sum_{\tau} R(\tau) P_\theta(\tau) \\ &= \sum_{\tau} R(\tau) \nabla P_\theta(\tau) \\ &= \sum_{\tau} R(\tau) \nabla P_\theta(\tau) \frac{P_\theta(\tau)}{P_\theta(\tau)} \\ &= \sum_{\tau} P_\theta(\tau) R(\tau) \frac{\nabla P_\theta(\tau)}{P_\theta(\tau)} \\ &= \sum_{\tau} P_\theta(\tau) R(\tau) \frac{\nabla P_\theta(\tau)}{P_\theta(\tau)} \end{align*}
∇E(R(τ))τ∼Pθ(τ)=∇τ∑R(τ)Pθ(τ)=τ∑R(τ)∇Pθ(τ)=τ∑R(τ)∇Pθ(τ)Pθ(τ)Pθ(τ)=τ∑Pθ(τ)R(τ)Pθ(τ)∇Pθ(τ)=τ∑Pθ(τ)R(τ)Pθ(τ)∇Pθ(τ)
注意,到这一步就存在两个Trick了:
大数定律:
E
(
X
)
=
∑
x
p
(
x
)
≈
1
N
∑
x
\text{大数定律:}E(X)=\sum xp(x) \approx \frac{1}{N} \sum x
大数定律:E(X)=∑xp(x)≈N1∑x
梯度的对数变换:
∇
f
(
x
)
f
(
x
)
=
∇
l
o
g
f
(
x
)
\text{梯度的对数变换:}\frac{\nabla f(x)}{f(x)} = \nabla logf(x)
梯度的对数变换:f(x)∇f(x)=∇logf(x)
最终我们得到:
∇
E
(
R
(
τ
)
)
τ
∼
P
θ
(
τ
)
≈
1
N
∑
n
=
1
N
R
(
τ
n
)
∇
P
θ
(
τ
n
)
P
θ
(
τ
n
)
=
1
N
∑
n
=
1
N
R
(
τ
n
)
∇
log
P
θ
(
τ
n
)
\begin{align*} \nabla E(R(\tau))_{\tau \sim P_\theta(\tau)} & \approx \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \frac{\nabla P_\theta(\tau^n)}{P_\theta(\tau^n)} \\ &= \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log P_\theta(\tau^n) \end{align*}
∇E(R(τ))τ∼Pθ(τ)≈N1n=1∑NR(τn)Pθ(τn)∇Pθ(τn)=N1n=1∑NR(τn)∇logPθ(τn)
虽然引入
τ
\tau
τ的确是可以帮我们简化运算符号,但真要算起来,这玩意儿也非常棘手。于是,我们还是得老老实实地找找
τ
\tau
τ和
State
\text{State}
State以及
Action
\text{Action}
Action的关系。我们应该首先想想,
τ
\tau
τ和
P
θ
(
τ
)
P_{\theta}(\tau)
Pθ(τ)究竟是指什么?
一条轨迹
τ
\tau
τ 定义为:
τ
=
(
s
1
,
a
1
,
s
2
,
a
2
,
…
,
s
T
,
a
T
)
,
\tau = (s^1, a^1, s^2, a^2, \dots, s^T, a^T),
τ=(s1,a1,s2,a2,…,sT,aT),
其产生这条轨迹的概率可分解为:在每一步时,选择特定动作和转移到特定状态的概率:
P
θ
(
τ
)
=
P
(
s
1
)
∏
t
=
1
T
P
θ
(
a
t
∣
s
t
)
⏟
策略的动作概率
⋅
P
(
s
t
+
1
∣
s
t
,
a
t
)
⏟
环境的状态转移概率
.
P_\theta(\tau) = P(s^1) \prod_{t=1}^{T} \underbrace{P_\theta(a^t \mid s^t)}_{\text{策略的动作概率}} \cdot \underbrace{P(s^{t+1} \mid s^t, a^t)}_{\text{环境的状态转移概率}}.
Pθ(τ)=P(s1)t=1∏T策略的动作概率
Pθ(at∣st)⋅环境的状态转移概率
P(st+1∣st,at).
我们可以发现,环境的状态转移概率和
θ
\theta
θ是无关的,求导是个无关紧要的系数,可以直接扔掉不管。
P
θ
(
τ
)
=
∏
t
=
1
T
P
θ
(
a
t
∣
s
t
)
P_\theta(\tau) = \prod_{t=1}^{T} P_\theta(a^t \mid s^t)
Pθ(τ)=t=1∏TPθ(at∣st)
∇ E ( R ( τ ) ) τ ∼ P θ ( τ ) = 1 N ∑ n = 1 N R ( τ n ) ∇ log P θ ( τ n ) = 1 N ∑ n = 1 N R ( τ n ) ∇ log ∏ t = 1 T n P θ ( a n t ∣ s n t ) = 1 N ∑ n = 1 N R ( τ n ) ∑ t = 1 T n ∇ log P θ ( a n t ∣ s n t ) = 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ∇ log P θ ( a n t ∣ s n t ) \begin{align*} \nabla E(R(\tau))_{\tau \sim P_\theta(\tau)}&= \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log P_\theta(\tau^n) \\ &= \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \nabla \log \prod_{t=1}^{T_n} P_\theta(a_n^t \mid s_n^t) \\ &= \frac{1}{N} \sum_{n=1}^{N} R(\tau^n) \sum_{t=1}^{T_n} \nabla \log P_\theta(a_n^t \mid s_n^t) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log P_\theta(a_n^t \mid s_n^t) \end{align*} ∇E(R(τ))τ∼Pθ(τ)=N1n=1∑NR(τn)∇logPθ(τn)=N1n=1∑NR(τn)∇logt=1∏TnPθ(ant∣snt)=N1n=1∑NR(τn)t=1∑Tn∇logPθ(ant∣snt)=N1n=1∑Nt=1∑TnR(τn)∇logPθ(ant∣snt)
终于,我们得到了我们最终的表达式:
E
(
R
(
τ
)
)
τ
∼
P
θ
(
τ
)
=
1
N
∑
n
=
1
N
∑
t
=
1
T
n
R
(
τ
n
)
log
P
θ
(
a
n
t
∣
s
n
t
)
E(R(\tau))_{\tau \sim P_\theta(\tau)} = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \log P_\theta(a_n^t \mid s_n^t)
E(R(τ))τ∼Pθ(τ)=N1n=1∑Nt=1∑TnR(τn)logPθ(ant∣snt)
Loss函数通常定义为期望的负数,则:
Loss = − 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) log P θ ( a n t ∣ s n t ) \text{Loss} = -\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \log P_\theta(a_n^t \mid s_n^t) Loss=−N1n=1∑Nt=1∑TnR(τn)logPθ(ant∣snt)
1.3 目标函数的改进
我们细细观察一下:
E
(
R
(
τ
)
)
τ
∼
P
θ
(
τ
)
=
1
N
∑
n
=
1
N
∑
t
=
1
T
n
R
(
τ
n
)
log
P
θ
(
a
n
t
∣
s
n
t
)
E(R(\tau))_{\tau \sim P_\theta(\tau)} = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \log P_\theta(a_n^t \mid s_n^t)
E(R(τ))τ∼Pθ(τ)=N1n=1∑Nt=1∑TnR(τn)logPθ(ant∣snt)
对于某一个 Trajectory \text{Trajectory} Trajectory而言,如果获得的 R ( τ ) ) > 0 R(\tau))>0 R(τ))>0,则会增加所有状态下采取当前 Action \text{Action} Action的概率。同理,若是 R ( τ ) ) < 0 R(\tau))<0 R(τ))<0,则会减小所有状态下采取当前 Action \text{Action} Action的概率。
但是,这真的合适吗?至少我们发现了两个问题:
-
壹: 我们是否增大或者减小在某状态下选取该动作的概率应该看的是选取该动作后直到游戏结束的Return,而非整个 Trajectory \text{Trajectory} Trajectory。即该动作不应该影响该动作之前的 R ( τ ) ) R(\tau)) R(τ))。
-
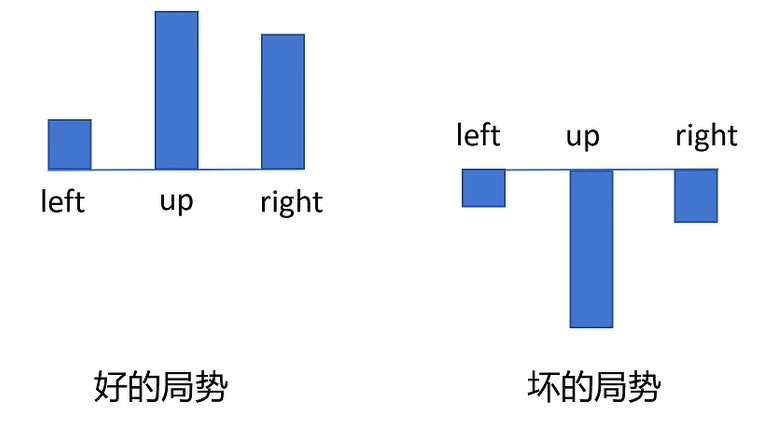
贰: 存在所谓的好局势和坏局势的情况。前者意味,在特定状态下任何动作都有正Reward,后者则都有负Reward。但对于我们现在的 E ( R ( τ ) ) E(R(\tau)) E(R(τ)),在好局势下会增加所有动作的概率,坏局势下则会减少所有动作的概率。例如下图的情况:
相应地,我们也提出了解决方案:
- 壹: 我们将全部轨迹替换为该动作发生之后的轨迹,并引入小于1的折扣因子 γ \gamma γ,来表示该动作对之后 R e t u r n Return Return的影响越来越小( γ n \gamma^n γn单调递减)。
R ( τ n ) → ∑ t ′ = t T n γ t ′ − t r t ′ n = R t n R(\tau^n) \rightarrow \sum_{t'=t}^{T_n} \gamma^{t'-t} r_{t'}^n = R_t^n R(τn)→t′=t∑Tnγt′−trt′n=Rtn
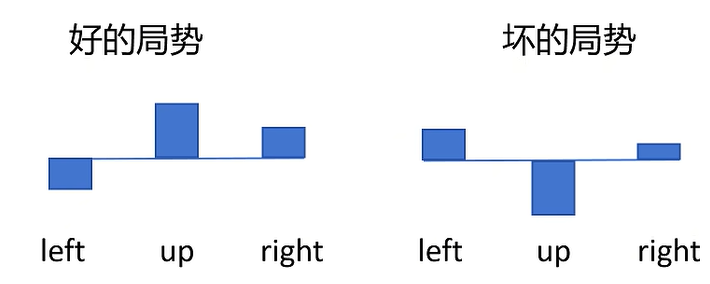
- 贰: 我们的解决方案是减去一个Baseline。效果如下图,就足以区分在“好”“坏”局势下各动作的优劣:
∇ E ( R ( τ ) ) τ ∼ P θ ( τ ) = 1 N ∑ n = 1 N ∑ t = 1 T n R ( τ n ) ∇ log P θ ( a n t ∣ s n t ) = 1 N ∑ n = 1 N ∑ t = 1 T n R t n ∇ log P θ ( a n t ∣ s n t ) = 1 N ∑ n = 1 N ∑ t = 1 T n ( R t n − B ( s n t ) ) ∇ log P θ ( a n t ∣ s n t ) \begin{align*} \nabla E(R(\tau))_{\tau \sim P_\theta(\tau)}&= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R(\tau^n) \nabla \log P_\theta(a_n^t \mid s_n^t) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} R_t^n \nabla \log P_\theta(a_n^t \mid s_n^t) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} (R_t^n - B(s_n^t)) \nabla \log P_\theta(a_n^t \mid s_n^t) \end{align*} ∇E(R(τ))τ∼Pθ(τ)=N1n=1∑Nt=1∑TnR(τn)∇logPθ(ant∣snt)=N1n=1∑Nt=1∑TnRtn∇logPθ(ant∣snt)=N1n=1∑Nt=1∑Tn(Rtn−B(snt))∇logPθ(ant∣snt)
上式中的 B ( s n t ) B(s_n^t) B(snt)即为我们的Baseline。那么这个 B ( s n t ) B(s_n^t) B(snt)应该如何计算呢?——输入为State,输出为Return的期望——是的,学得扎实的读者一定想起了这不是很像我们的Critic网络嘛!我们只需要一个神经网络就可以完成这一件任务。
于是,我们当机立断地引入最后几个概念,就足以完成策略梯度算法的最终推导:
-
Action-Value Function
R t n R_t^n Rtn 每次都是一次随机采样,方差很大,训练不稳定。如果要求结果收敛的话,采样次数需要趋于无穷。
Q θ ( s , a ) Q_\theta(s, a) Qθ(s,a) 定义为动作价值函数。即在 state s s s 下,做出 Action a a a,期望的回报。
-
State-Value Function
V θ ( s ) V_\theta(s) Vθ(s) 在 state s s s 下,期望的回报。状态价值函数。
-
Advantage Function(优势函数)
A θ ( s , a ) = Q θ ( s , a ) − V θ ( s ) A_\theta(s, a) = Q_\theta(s, a) - V_\theta(s) Aθ(s,a)=Qθ(s,a)−Vθ(s) 在 state s s s 下,做出 Action a a a,比其他动作能带来多少优势。
于是终于我们就得到了策略梯度算法最终的表达式
E
(
R
(
τ
)
)
τ
∼
P
θ
(
τ
)
=
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
θ
(
s
n
t
,
a
n
t
)
∇
log
P
θ
(
a
n
t
∣
s
n
t
)
E(R(\tau))_{\tau \sim P_\theta(\tau)} = \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_\theta(s_n^t, a_n^t) \nabla \log P_\theta(a_n^t \mid s_n^t)
E(R(τ))τ∼Pθ(τ)=N1n=1∑Nt=1∑TnAθ(snt,ant)∇logPθ(ant∣snt)
1.4 优势函数的改写
虽然给出了优势函数的定义后,我们能简单地表示出$ E(R(\tau)) ,但事实上,要训练优势函数中的两个神经网络 ,但事实上,要训练优势函数中的两个神经网络 ,但事实上,要训练优势函数中的两个神经网络Q(s,a) 和 和 和V(s)$,也不是那么容易的。于是我们便开始思考,是否存在更简单的表示方法?
通过研究动作-价值函数与状态-价值函数的关系,我们能够得到下列等式:
Q
θ
(
s
t
,
a
)
=
r
t
+
γ
∗
V
θ
(
s
t
+
1
)
Q_\theta(s_t, a) = r_t + \gamma * V_\theta(s_{t+1})
Qθ(st,a)=rt+γ∗Vθ(st+1)
该等式的意义也非常直观: t t t 时刻在状态 s s s 选择动作 a a a的期望回报(Return),等于在t时刻的即时奖励(Reward)加上对未来价值的估计(注意还乘了一个折扣因子 γ \gamma γ)。
于是我们就可以按照下列方式改写:
A
θ
(
s
t
,
a
)
=
r
t
+
γ
∗
V
θ
(
s
t
+
1
)
−
V
θ
(
s
t
)
A_\theta(s_t, a) = r_t + \gamma * V_\theta(s_{t+1}) - V_\theta(s_t)
Aθ(st,a)=rt+γ∗Vθ(st+1)−Vθ(st)
这样,我们就只用训练状态-价值函数的神经网络了。不过,上式还不够完备,因为我们对于 A θ ( s t , a ) A_\theta(s_t, a) Aθ(st,a)的估计,只考虑了下一个时间步,即 t + 1 t+1 t+1。如果我们要考虑得更加精准的话,势必要考虑到从 t t t到游戏结束时刻 T T T的状态-价值函数。
于是,在此处,我们直接给出贝尔曼方程的结论:
V
θ
(
s
t
+
1
)
≈
r
t
+
1
+
γ
∗
V
θ
(
s
t
+
2
)
V_\theta(s_{t+1}) \approx r_{t+1} + \gamma * V_\theta(s_{t+2})
Vθ(st+1)≈rt+1+γ∗Vθ(st+2)
因此,优势函数可以表示为:
A
θ
1
(
s
t
,
a
)
=
r
t
+
γ
∗
V
θ
(
s
t
+
1
)
−
V
θ
(
s
t
)
A
θ
3
(
s
t
,
a
)
=
r
t
+
γ
∗
r
t
+
1
+
γ
2
∗
r
t
+
2
+
γ
3
V
θ
(
s
t
+
3
)
−
V
θ
(
s
t
)
A
θ
2
(
s
t
,
a
)
=
r
t
+
γ
∗
r
t
+
1
+
γ
2
∗
V
θ
(
s
t
+
2
)
⋮
A
θ
T
(
s
t
,
a
)
=
r
t
+
γ
∗
r
t
+
1
+
γ
2
∗
r
t
+
2
+
γ
3
∗
r
t
+
3
+
⋯
+
γ
T
∗
r
T
−
V
θ
(
s
t
)
\begin{align*} A_\theta^1(s_t, a) &= r_t + \gamma * V_\theta(s_{t+1}) - V_\theta(s_t)\\ A_\theta^3(s_t, a) &= r_t + \gamma * r_{t+1} + \gamma^2 * r_{t+2} + \gamma^3 V_\theta(s_{t+3}) - V_\theta(s_t) \\ A_\theta^2(s_t, a) &= r_t + \gamma * r_{t+1} + \gamma^2 * V_\theta(s_{t+2})\\ &\vdots \\ A_\theta^T(s_t, a) &= r_t + \gamma * r_{t+1} + \gamma^2 * r_{t+2} + \gamma^3 * r_{t+3} + \cdots + \gamma^T * r_T - V_\theta(s_t) \end{align*}
Aθ1(st,a)Aθ3(st,a)Aθ2(st,a)AθT(st,a)=rt+γ∗Vθ(st+1)−Vθ(st)=rt+γ∗rt+1+γ2∗rt+2+γ3Vθ(st+3)−Vθ(st)=rt+γ∗rt+1+γ2∗Vθ(st+2)⋮=rt+γ∗rt+1+γ2∗rt+2+γ3∗rt+3+⋯+γT∗rT−Vθ(st)
上式中不同的上标表示不同的采样时间步。采样的时间步越多那么偏差就越小,但也会导致方差增大。上式表达还不够简洁,因故,我们最后引入一个定义:
δ
t
V
=
r
t
+
γ
∗
V
θ
(
s
t
+
1
)
−
V
θ
(
s
t
)
δ
t
+
1
V
=
r
t
+
1
+
γ
∗
V
θ
(
s
t
+
2
)
−
V
θ
(
s
t
+
1
)
\begin{align*} \delta_t^V &= r_t + \gamma * V_\theta(s_{t+1}) - V_\theta(s_t) \\ \delta_{t+1}^V &= r_{t+1} + \gamma * V_\theta(s_{t+2}) - V_\theta(s_{t+1}) \end{align*}
δtVδt+1V=rt+γ∗Vθ(st+1)−Vθ(st)=rt+1+γ∗Vθ(st+2)−Vθ(st+1)
有了
δ
\delta
δ的定义后,表示优势函数就简洁了许多。
现在我们还剩最后一个问题:在实际应用中,我们采样到底是取多少的时间步呢?
答案是:小孩才做选择 全都要! 这也就是我们的GAE(General Advantage Estimation):
A
θ
G
A
E
(
s
t
,
a
)
=
(
1
−
λ
)
(
A
θ
1
+
λ
∗
A
θ
2
+
λ
2
A
θ
3
+
⋯
)
=
(
1
−
λ
)
(
δ
t
V
+
λ
∗
(
δ
t
V
+
γ
δ
t
+
1
V
)
+
λ
2
(
δ
t
V
+
γ
δ
t
+
1
V
+
γ
2
δ
t
+
2
V
)
+
⋯
)
=
(
1
−
λ
)
(
δ
t
V
(
1
+
λ
+
λ
2
+
⋯
)
+
γ
δ
t
+
1
V
∗
(
λ
+
λ
2
+
⋯
)
+
⋯
)
=
(
1
−
λ
)
(
δ
t
V
1
1
−
λ
+
γ
δ
t
+
1
V
λ
1
−
λ
+
⋯
)
=
∑
b
=
0
∞
(
γ
λ
)
b
δ
t
+
b
V
\begin{align*} A_\theta^{GAE}(s_t, a) &= (1 - \lambda)(A_\theta^1 + \lambda * A_\theta^2 + \lambda^2 A_\theta^3 + \cdots)\\ &= (1 - \lambda)(\delta_t^V + \lambda * (\delta_t^V + \gamma \delta_{t+1}^V) + \lambda^2(\delta_t^V + \gamma \delta_{t+1}^V + \gamma^2 \delta_{t+2}^V) + \cdots) \\ &= (1 - \lambda)(\delta_t^V(1 + \lambda + \lambda^2 + \cdots) + \gamma \delta_{t+1}^V * (\lambda + \lambda^2 + \cdots) + \cdots) \\ &= (1 - \lambda)(\delta_t^V \frac{1}{1 - \lambda} + \gamma \delta_{t+1}^V \frac{\lambda}{1 - \lambda} + \cdots) \\ &= \sum_{b=0}^{\infty} (\gamma \lambda)^b \delta_{t+b}^V \end{align*}
AθGAE(st,a)=(1−λ)(Aθ1+λ∗Aθ2+λ2Aθ3+⋯)=(1−λ)(δtV+λ∗(δtV+γδt+1V)+λ2(δtV+γδt+1V+γ2δt+2V)+⋯)=(1−λ)(δtV(1+λ+λ2+⋯)+γδt+1V∗(λ+λ2+⋯)+⋯)=(1−λ)(δtV1−λ1+γδt+1V1−λλ+⋯)=b=0∑∞(γλ)bδt+bV
上式中的
λ
\lambda
λ为超参数,用于控制各时间步的优势函数对于GAE的贡献。
Proximal Policy Optimization
2.1 On or Off Policy
在已经了解策略梯度算法之后,PPO只差临门一脚了。于是,我们不妨先从一些例子来了解一下,为什么我们需要PPO?
首先我们需要知道On Policy和Off Policy这两个概念。

这个概念也十分简单:前者是一边训练一边采集数据——可想而知,游戏每完成一轮,才能训练一次,效率较低。而后者则是拿数据直接去训练模型,效率包在线的!
那么这和我们需要使用PPO有什么关系嘛?请不必着急,先看下面的例子:

不难看出,图中的男孩(不如就叫他李华)正在接受老师的表扬而春风满面,身旁的同学也拍手称赞。假如小华是因为努力学习而受到老师表扬,那么他就会暗暗地强化努力学习这一行为,如果下一次又因为努力学习而被表扬了,则又会强化。这就是On Policy。问题就在于,李华很难一天被老师表扬两次。
而身旁的同学,看到李华因为好好学习被表扬了,在自己心中也强化努力学习的行为。接着,比如又看到小畅因为好好学习被表扬了,同样也会强化该行为。这就是Off Policy。虽然不是自己被表扬,但是好在学习的榜样多。
但是,并不是班上每一个学生被老师表扬,我们都应该去强化被表扬的行为。例如,班上总是辱骂老师的小锴终于没有辱骂老师了,老师狠狠地表扬了他;但这样的强化对于优秀的小畅而言毫无意义——她对老师向来毕恭毕敬。
所以,这启发我们——只有当两个样本足够接近,才有学习的意义。这就是我们为什么需要PPO。
2.2 目标函数变形
我们已经充分了解到了Off Policy相较于On Policy的好处,那么我们应该想想办法,将我们的目标函数变做Off Policy的形式。
首先在此处需要介绍一个数学上的技巧:
E
(
f
(
x
)
)
x
∼
p
(
x
)
=
∑
x
f
(
x
)
∗
p
(
x
)
=
∑
x
f
(
x
)
∗
p
(
x
)
q
(
x
)
q
(
x
)
=
∑
x
f
(
x
)
p
(
x
)
q
(
x
)
∗
q
(
x
)
=
E
(
f
(
x
)
p
(
x
)
q
(
x
)
)
x
∼
q
(
x
)
大数定律
≈
1
N
∑
n
=
1
N
f
(
x
)
p
(
x
)
q
(
x
)
x
∼
q
(
x
)
\begin{align*} E(f(x))_{x \sim p(x)} &= \sum_{x} f(x) * p(x) \\ &= \sum_{x} f(x) * p(x) \frac{q(x)}{q(x)} \\ &= \sum_{x} f(x) \frac{p(x)}{q(x)} * q(x) \\ &= E\left(f(x) \frac{p(x)}{q(x)}\right)_{x \sim q(x)} \\ \text{大数定律}&\approx \frac{1}{N} \sum_{n=1}^{N} f(x) \frac{p(x)}{q(x)}_{x \sim q(x)} \end{align*}
E(f(x))x∼p(x)大数定律=x∑f(x)∗p(x)=x∑f(x)∗p(x)q(x)q(x)=x∑f(x)q(x)p(x)∗q(x)=E(f(x)q(x)p(x))x∼q(x)≈N1n=1∑Nf(x)q(x)p(x)x∼q(x)
将上述结论代入我们的目标函数:
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
θ
G
A
E
(
s
n
t
,
a
n
t
)
∇
log
P
θ
(
a
n
t
∣
s
n
t
)
=
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
θ
′
G
A
E
(
s
n
t
,
a
n
t
)
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
∇
log
P
θ
(
a
n
t
∣
s
n
t
)
=
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
θ
′
G
A
E
(
s
n
t
,
a
n
t
)
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
∇
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
(
a
n
t
∣
s
n
t
)
=
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
θ
′
(
s
n
t
,
a
n
t
)
∇
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
\begin{align*} &\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_\theta^{GAE}(s_n^t, a_n^t) \nabla \log P_\theta(a_n^t \mid s_n^t) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)} \nabla \log P_\theta(a_n^t \mid s_n^t) \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)} \frac{\nabla P_\theta(a_n^t \mid s_n^t)}{P_\theta(a_n^t \mid s_n^t)} \\ &= \frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_{\theta'}(s_n^t, a_n^t) \frac{\nabla P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)} \end{align*}
N1n=1∑Nt=1∑TnAθGAE(snt,ant)∇logPθ(ant∣snt)=N1n=1∑Nt=1∑TnAθ′GAE(snt,ant)Pθ′(ant∣snt)Pθ(ant∣snt)∇logPθ(ant∣snt)=N1n=1∑Nt=1∑TnAθ′GAE(snt,ant)Pθ′(ant∣snt)Pθ(ant∣snt)Pθ(ant∣snt)∇Pθ(ant∣snt)=N1n=1∑Nt=1∑TnAθ′(snt,ant)Pθ′(ant∣snt)∇Pθ(ant∣snt)
这一段变形中,存在一定理解难度的是第一个等号。我们还是以老师教育学生来举例:
P
θ
(
a
n
t
∣
s
n
t
)
P_\theta(a_n^t \mid s_n^t)
Pθ(ant∣snt)是小畅的策略,而
P
θ
′
(
a
n
t
∣
s
n
t
)
P_\theta'(a_n^t \mid s_n^t)
Pθ′(ant∣snt)则是小锴的策略,
A
θ
′
G
A
E
(
s
n
t
,
a
n
t
)
A_{\theta'}^{GAE}(s_n^t, a_n^t)
Aθ′GAE(snt,ant)是老师对小锴的表扬。假如小锴上课攻击老师的概率为20%,而小畅上课攻击老师的概率为0.1%,那么小畅强化自己“上课不要攻击老师”的行为的强度,就应该是
P
θ
P_\theta
Pθ与
P
θ
′
P_\theta'
Pθ′之比,也就是
1
200
\displaystyle \frac{1}{200}
2001。
得到对于期望的梯度之后,我们也能顺理成章地得到损失函数:
Loss
=
−
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
θ
G
A
E
(
s
n
t
,
a
n
t
)
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
\text{Loss} = -\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_\theta^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)}
Loss=−N1n=1∑Nt=1∑TnAθGAE(snt,ant)Pθ′(ant∣snt)Pθ(ant∣snt)
至此,我们就可以利用采集到的数据进行Off Policy的训练了。
2.3 PPO
我们在2.1节提到过:—只有当两个样本足够接近,才有学习的意义。于是,PPO在我们2.2节推导出的公式的基础上,采取了两种方式来确保样本的相似性。
Loss
p
p
o
=
−
1
N
∑
n
=
1
N
∑
t
=
1
T
n
A
θ
G
A
E
(
s
n
t
,
a
n
t
)
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
+
β
K
L
(
P
θ
,
P
θ
′
)
\text{Loss}_{ppo} = -\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} A_\theta^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)} + \beta KL(P_\theta, P_\theta')
Lossppo=−N1n=1∑Nt=1∑TnAθGAE(snt,ant)Pθ′(ant∣snt)Pθ(ant∣snt)+βKL(Pθ,Pθ′)
第一种方法是增加KL散度。KL散度是用于衡量两个概率分布差异的方法。对于离散概率分布 (P) 和 (Q),KL散度的公式为:
D
K
L
(
P
∥
Q
)
=
∑
x
P
(
x
)
log
P
(
x
)
Q
(
x
)
D_{KL}(P \parallel Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)}
DKL(P∥Q)=x∑P(x)logQ(x)P(x)
显然,当两者完全相同,即
P
(
x
)
Q
(
x
)
=
1
\displaystyle \frac{P(x)}{Q(x)} =1
Q(x)P(x)=1s时,KL散度为0。
第二种方法是直接为
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
\displaystyle \frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)}
Pθ′(ant∣snt)Pθ(ant∣snt)设置一个区间:
Loss
p
p
o
2
=
−
1
N
∑
n
=
1
N
∑
t
=
1
T
n
min
(
A
θ
G
A
E
(
s
n
t
,
a
n
t
)
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
,
clip
(
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
,
1
−
ε
,
1
+
ε
)
A
θ
G
A
E
(
s
n
t
,
a
n
t
)
)
\text{Loss}_{ppo2} = -\frac{1}{N} \sum_{n=1}^{N} \sum_{t=1}^{T_n} \min \left( A_\theta^{GAE}(s_n^t, a_n^t) \frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)}, \text{clip}\left(\frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)}, 1 - \varepsilon, 1 + \varepsilon \right) A_\theta^{GAE}(s_n^t, a_n^t) \right)
Lossppo2=−N1n=1∑Nt=1∑Tnmin(AθGAE(snt,ant)Pθ′(ant∣snt)Pθ(ant∣snt),clip(Pθ′(ant∣snt)Pθ(ant∣snt),1−ε,1+ε)AθGAE(snt,ant))
截断函数
c
l
i
p
clip
clip将为
P
θ
(
a
n
t
∣
s
n
t
)
P
θ
′
(
a
n
t
∣
s
n
t
)
\displaystyle \frac{P_\theta(a_n^t \mid s_n^t)}{P_\theta'(a_n^t \mid s_n^t)}
Pθ′(ant∣snt)Pθ(ant∣snt)强制限定在
[
1
−
ϵ
,
1
+
ϵ
]
[1-\epsilon,1+\epsilon]
[1−ϵ,1+ϵ]之中。根据OpenAI的原论文,
ϵ
\epsilon
ϵ一般取0.2。
总结
无论是策略梯度算法还是在其基础上改进的PPO,其算法的推导过程事实上并不困难,难点在于对于一系列概念的理解。
不过,应该实际上手做点项目就熟练了

















 312
312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









