






[目录]
0.BNN直观对比与行文概述
1.DF One:贝叶斯估计求参数
2.DF Two:优化算法训参数
3.BNN实战论文复现(附源代码)
4.总结及本人写作动机
0.行文概述与BNN直观对比
大部分讲BNN(Bayesian Neural Networks)的文章开局即BNN的建模过程,但不少读者(至少本人)读完甚至都不知道为什么要这样进行建模。除了看了一通酣畅淋漓(又不知所云)的公式后,感觉也没什么留在自己的大脑里。大概是源于本人层次还是太低(非CS专业大二本科生)。
但这并不意味着没有解决办法。经过一番思考后,决定首先为读者直观地呈现BNN与一般MLP的差异,然后从差异入手开始推导。有了一个整体框架对比的概念后,或许理解起来就会容易很多。目录中的DF,即为Difference的意思。
完成推导后,会给出本人最近正在完成的一篇基于BNN对原子质量的预测的论文复现过程,展示BNN真正的科研实战能力。
如果有希望获取完整源码和数据以实战的读者,可以在公众号HORSE RUNNING WILD的后台回复BNN复现。
| 特性 | 其它常见MLP | 贝叶斯神经网络 (BNN) |
|---|---|---|
| 1.对神经网络的理解 | 视作黑盒模型逼近函数,输出的 y y y为一个值: y = ∑ i = 1 N ( e ) a i σ ( w i ⋅ x + b i ) y = \sum_{i=1}^{N(e)} a_i \sigma(\mathbf{w}_i \cdot \mathbf{x} + b_i) y=∑i=1N(e)aiσ(wi⋅x+bi) | 视作条件分布模型,输出的 y y y为分布: P ( y ∣ x , w ) P(y \mid x, w) P(y∣x,w) |
| 2.求参数 w \mathbf{w} w的思路 | 最大似然估计或引入最大后验估计,其中 D \mathcal{D} D为数据集:KaTeX parse error: {align*} can be used only in display mode. KaTeX parse error: {align*} can be used only in display mode. | 贝叶斯估计 P ( w ∣ D ) = P ( w , D ) P ( D ) = P ( D ∣ w ) P ( w ) P ( D ) P(\mathbf{w} \mid \mathcal{D}) = \frac{P(\mathbf{w}, \mathcal{D})}{P(\mathcal{D})} = \frac{P(\mathcal{D} \mid \mathbf{w}) P(\mathbf{w})}{P(\mathcal{D})} P(w∣D)=P(D)P(w,D)=P(D)P(D∣w)P(w) |
| 3.激活函数 | ReLU、Sigmoid、Tanh等。 | 与一般神经网络类似,常用tanh |
| 4.目标函数(损失函数) | 分类:常用交叉熵(2式中代入逻辑函数得);回归:常用均方误差(2式中代入高斯分布)。 | 若为MCMC,则是采样至收敛到权重的后验分布;若为变分推断,则是最小化KL散度 |
| 5.优化算法 | (最常用)梯度下降及其变体,如SGD、Adam。 | 通过变分推断(Variational Inference)、马尔可夫链蒙特卡洛(MCMC)等技术来近似后验分布。 |
| 6.权重和偏置 | 权重 W W W:信号传递的强度,表征节点联系及重要性;偏置 b b b:允许每个神经元有一个额外的输入。这俩都是数值而非分布 | W W W与 b b b都不再是一个值,而是概率分布 |
| 7.修改网络结构(权重与偏置)的方式 | 主要依赖于反向传播算法(如5中的一些优化算法): w j = w j − l r ∂ L ∂ w j w_j = w_j - lr \frac{\partial L}{\partial w_j} wj=wj−lr∂wj∂L | 若为MCMC,则是采样至收敛到权重的后验分布;有局部重参数化+反向传播等技巧 |
| 8.两者的一些联系 | 常用的SGD(随机梯度下降)算法等,都是可以说是使用了MC(马尔可夫链)的随机采样思想 | 对于最大后验估计,若参数 w \mathbf{w} w满足高斯分布,其实就得到的是常用的L2正则化 |
本人的一点想法:从原理上看,似乎一般的神经网络是BNN的特例,BNN在算法上更本质。
如果读者对于权重为分布这一点感到困惑的话,可以参考下面两张图:
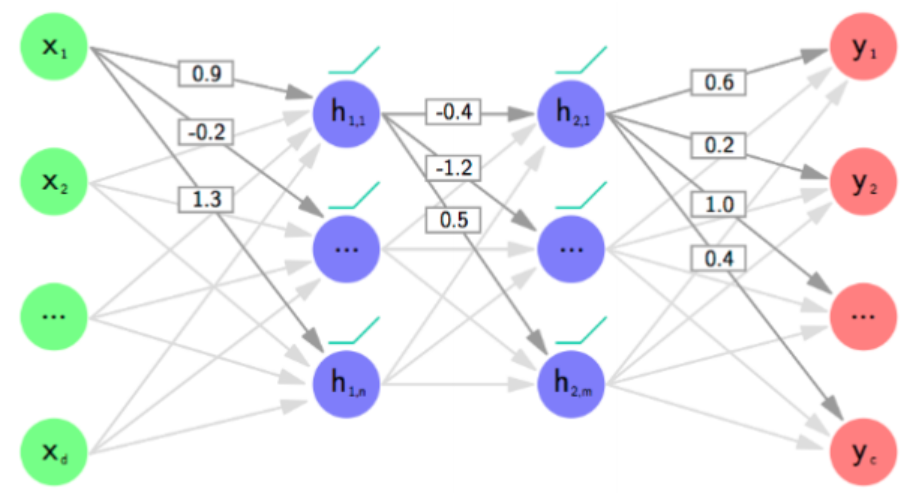
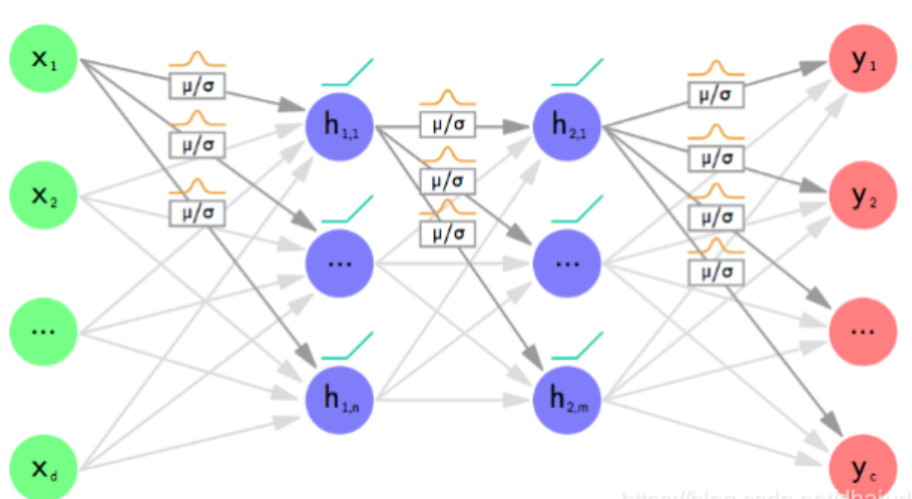
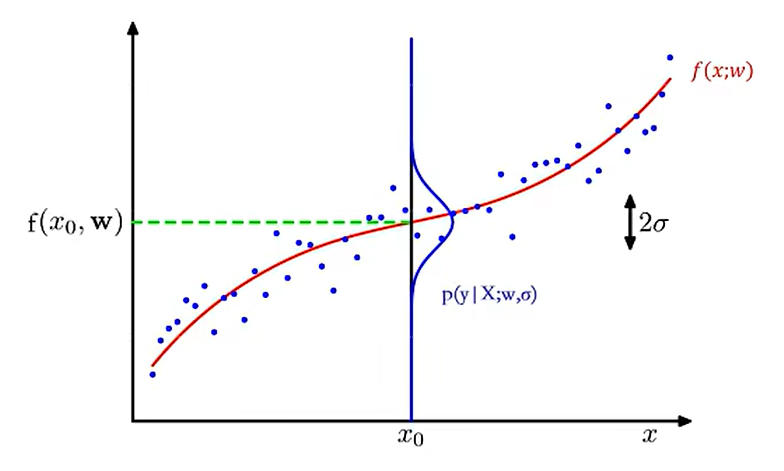
如果对输出 y y y 为分布感到不理解,可以参考下面这张图
1.DF One:贝叶斯估计求参数
根据上述表格,我们可以发现,在求参数部分,BNN就已经不走寻常路了。根据贝叶斯定理,我们有以下等式:
P
(
H
∣
D
)
=
P
(
D
∣
H
)
P
(
H
)
P
(
D
)
=
P
(
D
∣
H
)
P
(
H
)
∫
H
P
(
D
∣
H
′
)
P
(
H
′
)
d
H
′
=
P
(
D
,
H
)
∫
H
P
(
D
,
H
′
)
d
H
′
P(H|D) = \frac{P(D|H)P(H)}{P(D)} \\ = \frac{P(D|H)P(H)}{\int_{H} P(D|H')P(H') dH'} \\ = \frac{P(D, H)}{\int_{H} P(D, H') dH'}
P(H∣D)=P(D)P(D∣H)P(H)=∫HP(D∣H′)P(H′)dH′P(D∣H)P(H)=∫HP(D,H′)dH′P(D,H)
| 随机变量 | 定义 |
|---|---|
| H H H | 假设 |
| D D D | 数据 |
| p ( H ∣ D ) p(H\mid D) p(H∣D) | 后验概率 (posterior) |
| p ( H ) p(H) p(H) | 先验概率 (prior) |
| p ( D ∣ H ) p(D\mid H) p(D∣H) | 似然概率 (likelihood) |
怎么将上述公式与我们的神经网络训练建立联系呢?其实我们只需要将其中的符号进行一些替换即可:
p
(
θ
∣
D
)
=
p
(
D
y
∣
D
x
,
θ
)
p
(
θ
)
∫
θ
p
(
D
y
∣
D
x
,
θ
′
)
p
(
θ
′
)
d
θ
′
∝
p
(
D
y
∣
D
x
,
θ
)
p
(
θ
)
p(\theta | D) = \frac{p(D_y | D_x, \theta) p(\theta)}{\int_{\theta} p(D_y | D_x, \theta') p(\theta') d\theta'} \propto p(D_y | D_x, \theta) p(\theta)
p(θ∣D)=∫θp(Dy∣Dx,θ′)p(θ′)dθ′p(Dy∣Dx,θ)p(θ)∝p(Dy∣Dx,θ)p(θ)
其中,
θ
\theta
θ 替换了
H
H
H,作为我们神经网络中训练的参数。具体展示如下
| 随机变量 | 定义 |
|---|---|
| θ \theta θ | 神经网络参数 |
| D x D_x Dx, D y D_y Dy | 特征与标签 |
| p ( θ ∣ D ) p(\theta \mid D) p(θ∣D) | 网络参数的后验概率 (posterior) |
| p ( θ ) p(\theta) p(θ) | 网络参数的先验概率 (prior) |
| p ( D y ∣ D x , θ ) p(D_y \mid D_x, \theta) p(Dy∣Dx,θ) | 网络的估计性能 |
分母被称为"Evidence",通常难以计算。但在此处,我们先假设上式的各个部分我们都能够成功算出,我们就得到了
p
(
θ
∣
D
)
p(\theta \mid D)
p(θ∣D),这就意味着,我们能够成功算出我们想要的结果:
p
(
y
∣
x
,
D
)
=
∫
θ
p
(
y
∣
x
,
θ
′
)
p
(
θ
′
∣
D
)
d
θ
′
.
p(y | x, D) = \int_{\theta} p(y | x, \theta') p(\theta' | D) d\theta'.
p(y∣x,D)=∫θp(y∣x,θ′)p(θ′∣D)dθ′.
即,给定输入
x
x
x和数据集
D
D
D 的条件下,输出
y
y
y 的后验概率分布。
2.DF Two:优化算法训参数
2.1 MCMC(马尔可夫链蒙特卡洛算法)
为了得到我们的 p ( y ∣ x , D ) p(y | x, D) p(y∣x,D),我们应该想办法计算后验概率了。首先我们推出MCMC算法,即Markov Chain Monte Carlo。
坦言之,如果要非常严肃地推导MCMC方法,不仅需要大量数学知识,计算过程也十分复杂。但是,正如大部分数据科学方法一样,其实背后的基本原理也是通俗易懂的。于是在此处,我主要介绍MCMC方法的基本原理,以及最常用的一种MCMC方法:Metropolis-Hastings算法。
如果读者希望深入了解其背后的数学,建议参考:
2.1.1 Monte Carlo & Markov Chain
- Monte Carlo
先说蒙特卡洛(Monte Carlo)方法,相信绝大部分读者都不陌生。举一个最简单的例子,如果要求你计算出一个圆的面积,告诉了你半径,你可以以迅雷不及掩耳之势写下
S
=
π
∗
r
2
S = \pi * r^{2}
S=π∗r2
但是如果要求你计算下列蝙蝠侠的面积,大概率只能以迅雷不及掩耳之势发呆:
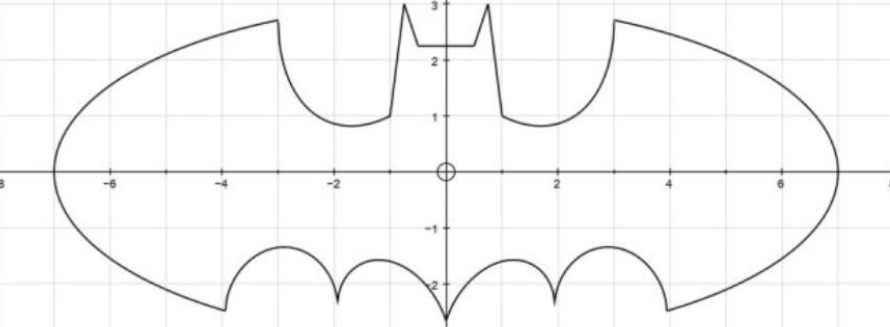
但其实我们是可以通过蒙特卡洛方法来近似计算的。例如,固定了一个可以框住上述蝙蝠侠的长方形,假设其面积为 S 1 S_1 S1 ,向其中随机抛撒一千个点.如果我们发现了有800个点都在蝙蝠侠内部,那蝙蝠侠的面积就能够被近似为 0.8 ∗ S 1 0.8 * S_1 0.8∗S1。
马尔可夫性质:马尔可夫链是一种具有“无记忆”性质的随机过程,当前状态的下一个状态只依赖于当前状态,而不依赖于历史状态。数学上,设 X 1 , X 2 , … X_1, X_2, \ldots X1,X2,… 是马尔可夫链中的状态序列,满足:
P ( X n + 1 ∣ X 1 , X 2 , … , X n ) = P ( X n + 1 ∣ X n ) P(X_{n+1} | X_1, X_2, \ldots, X_n) = P(X_{n+1} | X_n) P(Xn+1∣X1,X2,…,Xn)=P(Xn+1∣Xn)
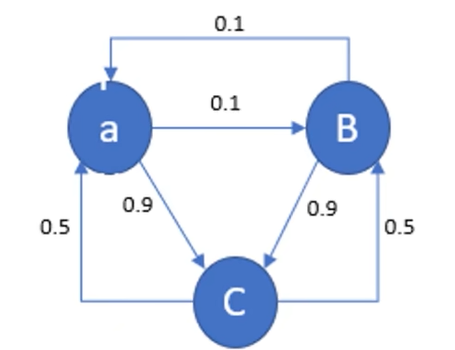
如上图所示,从B点到a或C点的概率,与该点是从a或C点到B点的概率无关,仅有在B点这一事件能够唯一确定下一步去哪里的概率。
转移矩阵:马尔可夫链通过转移概率矩阵(或转移核)定义,设 P i j P_{ij} Pij 表示从状态 i i i 转移到状态 j j j 的概率,则有:
P i j = P ( X n + 1 = j ∣ X n = i ) P_{ij} = P(X_{n+1} = j | X_n = i) Pij=P(Xn+1=j∣Xn=i)
对于上图,我们也能写出转移矩阵
P
=
[
0
0.1
0.9
0.1
0.0
0.9
0.5
0.5
0.0
]
P = \begin{bmatrix} 0 & 0.1 & 0.9 \\ 0.1 & 0.0 & 0.9 \\ 0.5 & 0.5 & 0.0 \end{bmatrix}
P=
00.10.50.10.00.50.90.90.0
细致平衡条件:在实际的MCMC应用中,重要的是确保马尔可夫链的平稳分布满足“细致平衡条件”(detailed balance)。即:
π ( i ) P i j = π ( j ) P j i \pi(i) P_{ij} = \pi(j) P_{ji} π(i)Pij=π(j)Pji
这一条件保证了链的平稳分布为目标分布。
稳态分布:经过足够多的迭代,马尔可夫链会收敛到一个稳定的分布 π \pi π,该分布满足:
π = π P \pi = \pi P π=πP
在 MCMC 中,我们构建的马尔可夫链会收敛到我们感兴趣的目标分布 p ( θ ∣ x ) p(\theta | x) p(θ∣x)。换句话说,该性质可以保证,只要我们的链足够长,初值再烂也无所谓。
B站大学上有一位Up主做了该过程的可视化:
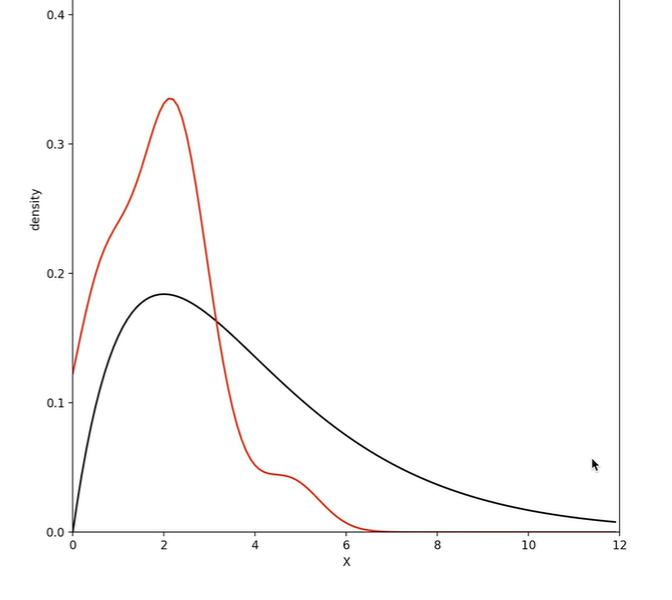
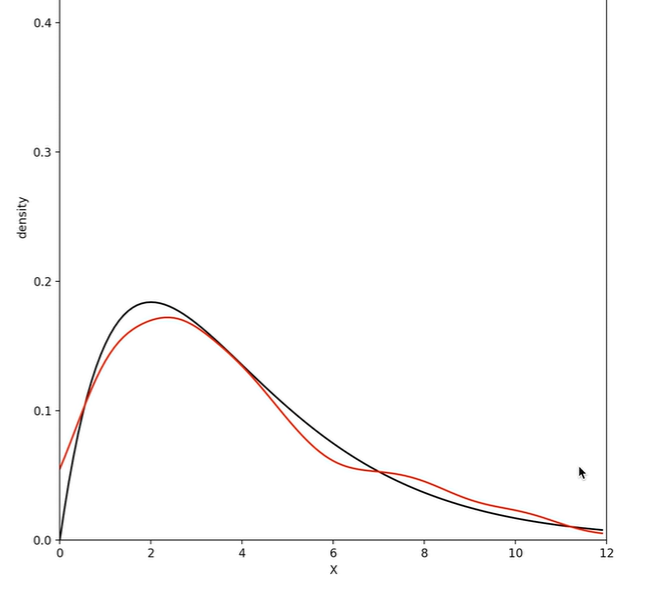
2.1.2 Metropolis-Hastings
了解了基本概念后,如何构建能够收敛到我们目标分布的马尔可夫链就成了最核心的目的。一般而言,常用的MCMC有三种:
- Metropolis-Hastings 算法
- Gibbs 取样算法
- Hamiltonian Monte Carlo 算法
效率最高的第三种,但用的稍微少一些。三者的基本原理是相对类似的,后面两者算是对前者的改进。在此处,我们就主要相对简单地介绍一下Metropolis-Hastings算法。如果希望看到更数学的表达,还是请参考,马尔可夫链蒙特卡罗算法(MCMC)
- Metropolis 算法
假设随机变量 X X X 服从一个概率密度函数 P P P。
-
初始化 X X X,即给定随机变量一个起始点 X 当前 X_{\text{当前}} X当前
-
生成随机的跳跃 Δ X ∼ N ( 0 , σ ) \Delta X \sim N(0, \sigma) ΔX∼N(0,σ), X 提议 = X 当前 + Δ X X_{\text{提议}} = X_{\text{当前}} + \Delta X X提议=X当前+ΔX
-
计算随机变量移动到提议的点的概率
P 移动 = min ( 1 , P ( X 提议 ) P ( X 当前 ) ) P_{\text{移动}} = \min(1, \frac{P(X_{\text{提议}})}{P(X_{\text{当前}})}) P移动=min(1,P(X当前)P(X提议)) -
生成一个随机数 C ∼ U ( 0 , 1 ) C \sim U(0, 1) C∼U(0,1),如果 C < P 移动 C < P_{\text{移动}} C<P移动 则接受跳跃,随机变量取提议的值;反之则仍取原来的值
-
重复步骤 2~4,并记录下随机变量所有的取值,直到蒙特卡洛模拟生成的随机游走足以代表目标分布
就是这麽简单直接的办法,我们就能最终求得我们梦寐以求的网络参数后验分布。
2.2 变分推断
虽然MCMC易懂可行,但是计算其方法的**“链”**式特性,即一步一步迭代的方式,在数据量较大时速度太慢。。于是BNN中另一种常见算法应运而生:变分推断。(PS:也有叫变分估计的)
变分推断的基本思想也较为简单:即,用一个参数化的分步(变分分布),去逼近我们希望得到的分布,如 p ( θ ∣ D ) p(\theta \mid D) p(θ∣D)。而我们应该如何衡量变分分布的优劣呢?——答案则是KL散度。
目标函数如下:
min θ K L ( q ( z ; θ ) ∥ p ( z ∣ ϕ ) ) \min_{\theta} KL(q(z;\theta) \parallel p(z \mid \phi)) minθKL(q(z;θ)∥p(z∣ϕ))
- q ( z ; θ ) q(z; \theta) q(z;θ) 代表一个叫做q的概率分布, p ( z ∣ x ; ϕ ) p(z \mid x; \phi) p(z∣x;ϕ) 代表一个叫做p的概率分布
- x x x 是一个给定的数据
- 我们要找到一个参数 θ \theta θ,使得 q ( z ; θ ) q(z; \theta) q(z;θ) 和 p ( z ∣ x ; ϕ ) p(z \mid x; \phi) p(z∣x;ϕ) 之间的 KL 散度最小
- KL 散度用于,衡量两个分布之间的距离
上式只是给出了一个目标函数,并非最终用于计算的表达式。因为此处涉及到的推导技巧较多且作者本人也不甚了解,以及本文最后实战部分选择采用的是MCMC方法,故建议感兴趣的读者可参考【史上最易懂】变分推断,本文在此处不再赘述。
3.BNN实战(附源代码)
3.1 背景简介
请大家回忆一下高中化学:
目前,因为人们对于原子核结构的了解并不够充分,所以对于原子核质量以及原子核结合能的预言精度还有待提高。原子核结合能是描述原子的一个非常重要的属性,每个原子都有自己的结合能。在过去,人们提高原子核结合能的预测精度的方式主要是靠加修正项(比如在液滴模型上添加修正项)或者是开发新的模型取解释原子核。
此处准备复现的一篇论文是Nuclear mass predictions based on Bayesian neural network approach with pairing and shell effects。
简要概述一下本文的最大特点,就是不再尝试修改物理模型了,而是尝试将物理模型预测的原子核结合能与真实值之间的残差作为 y y y,原子自身的性质(如质子数 Z Z Z 和中子数 N N N)作为 x x x,输入贝叶斯神经网络。则最终得到的是对于残差的预测,在物理模型预测值上加上BNN预测的残差,最终能将误差降到0.2Mev的水平。
如果读者一点物理也不懂,这无所谓,只需要知道,我们的目的是使用BNN完成一个回归任务。论文中网络的具体设置如下:
- 输入的 x x x 有两种,质子数 Z Z Z 和中子数 N N N或者再加两个配对项。即输入的 x x x 维度为2或者4。在本文中仅展示输入的 x x x维度为2。
- 真实值与物理模型预测的原子核结合能之间的残差作为 y y y,即 y y y 的维度为1.
- 先验分布( γ \gamma γ 分布)
- 似然函数(高斯分布)
- 激活函数:tanh
- MCMC采样(没有具体交代,本文中采用基于Hamiltonian Monte Carlo 算法改进的NUTs)
- 单隐藏层(根据参数数量反推),42个神经元
- 数据集划分4:1(太经典了)。
- 采用的物理模型为WS4模型,实验值与之做差得到残差
- 本文使用的数据有2457个(基于AME2020),原文使用的数据有2272个(基于AME2016)
- 论文选取的衡量标准为预测值与真实值的均方误差RMSE,也是业界常用的标准。本文沿用。
- 本文使用的是核结合能,而原文采用的是Mass Excess(质量过剩),两者都是衡量原子核结合能的标准,但是前者天然大于后者。也就意味着本文计算出的RMSE会比原文大一些。
3.2 BNN代码实现
目前,Pytorch和Tensorflow都有支持BNN的框架供我们实现。在此处我们选用基于torch的pyro,MCMC算法部分选择NUTS(No-U-turn Sampler),这是一种基于基于Hamiltonian Monte Carlo 算法改进的算法,有兴趣的读者可参考:
推荐一款革命性的Python采样器——No-U-Turn Sampler (NUTS)
具体实现代码如下:
import torch
import pyro
import pyro.distributions as dist
from pyro.infer import MCMC, NUTS
from pyro.nn import PyroModule, PyroSample
import torch.nn.functional as F
import torch.nn as nn
from sklearn.model_selection import train_test_split
import numpy as np
class BNNModel(PyroModule):
def __init__(self, hidden_layer_size):
super(BNNModel, self).__init__()
# 定义隐藏层和输出层的权重和偏置
self.hidden_weight = nn.Parameter(torch.randn(hidden_layer_size, 2))
self.hidden_bias = nn.Parameter(torch.randn(hidden_layer_size))
self.output_weight = nn.Parameter(torch.randn(1, hidden_layer_size))
self.output_bias = nn.Parameter(torch.randn(1))
def forward(self, x, y=None):
# 定义权重和偏置的超参数(方差的倒数),使用Gamma分布作为其先验
weight_precision_hidden = pyro.sample("weight_precision_hidden", dist.Gamma(1., 0.1))
bias_precision_hidden = pyro.sample("bias_precision_hidden", dist.Gamma(1., 0.1))
weight_precision_output = pyro.sample("weight_precision_output", dist.Gamma(1., 0.1))
bias_precision_output = pyro.sample("bias_precision_output", dist.Gamma(1., 0.1))
# 使用超参数来定义权重和偏置的先验分布
hidden_weight_prior = dist.Normal(0., 1. / torch.sqrt(weight_precision_hidden)).expand([self.hidden_weight.shape[0], self.hidden_weight.shape[1]]).to_event(2)
hidden_bias_prior = dist.Normal(0., 1. / torch.sqrt(bias_precision_hidden)).expand([self.hidden_bias.shape[0]]).to_event(1)
output_weight_prior = dist.Normal(0., 1. / torch.sqrt(weight_precision_output)).expand([self.output_weight.shape[0], self.output_weight.shape[1]]).to_event(2)
output_bias_prior = dist.Normal(0., 1. / torch.sqrt(bias_precision_output)).expand([self.output_bias.shape[0]]).to_event(1)
# 采样权重和偏置
hidden_weight = pyro.sample("hidden.weight", hidden_weight_prior)
hidden_bias = pyro.sample("hidden.bias", hidden_bias_prior)
output_weight = pyro.sample("output.weight", output_weight_prior)
output_bias = pyro.sample("output.bias", output_bias_prior)
# 前向传播
x = torch.tanh(x @ hidden_weight.T + hidden_bias)
mu = (x @ output_weight.T + output_bias).squeeze(-1)
# mu就是最终的输出值了
#.squeeze(-1)是为了去掉不必要的维度
# 定义噪声项的先验
sigma = pyro.sample("sigma", dist.Uniform(0., 1.))
with pyro.plate("data", x.shape[0]):
obs = pyro.sample("obs", dist.Normal(mu, sigma), obs=y)
# pyro会根据这段代码,通过贝叶斯估计更新模型参数后验分布
# 这一段和MCMC方法并不是冲突的,而是相辅相成的。因为MCMC方法并不是直接得到模型新的参数后验分布
# 而是通过采样得到模型参数后验分布的近似,然而通过这一段代码更新更新模型参数后验分布
return mu
# 设置隐藏层的大小
hidden_layer_size = 42
model = BNNModel(hidden_layer_size)
# 准备数据集
X = res_df[['A', 'Z']].values # 特征 A 和 Z
y = res_df['Res'].values # 目标变量 Res
# 划分训练集和验证集(4:1)
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_val, y_train, y_val = map(lambda x: torch.tensor(x, dtype=torch.float32), (X_train, X_val, y_train, y_val))
# 定义MCMC采样器
nuts_kernel = NUTS(model)
mcmc = MCMC(nuts_kernel, num_samples=500, warmup_steps=100)
# 运行MCMC采样
mcmc.run(X_train, y_train)
# 获取后验样本
posterior_samples = mcmc.get_samples()
def predict_with_posterior_samples(model, posterior_samples, X_test):
predictions = []
for i in range(len(posterior_samples['hidden.weight'])):
# 获取每次采样的权重和偏置
sampled_weights = {
"hidden.weight": posterior_samples['hidden.weight'][i], # (hidden_layer_size, input_features)
"hidden.bias": posterior_samples['hidden.bias'][i], # (hidden_layer_size,)
"output.weight": posterior_samples['output.weight'][i], # (1, hidden_layer_size)
"output.bias": posterior_samples['output.bias'][i] # (1,)
}
# 清空 Pyro 的参数存储区,避免影响后续的采样
param_store = pyro.get_param_store()
param_store.clear()
# 将样本权重和偏置添加到 Pyro 的参数存储中
for name, value in sampled_weights.items():
param_store[name] = value # 修改此行
# 运行模型预测
pred = model(X_test) # 模型会自动使用采样的权重和偏置
predictions.append(pred.detach().numpy()) # 获取预测结果并保存
return np.array(predictions)
# 这一段函数可谓是BNN的精髓。在此处,我们通过采集的num_samples个后验样本进行预测
# 自然也就得到了num_samples个预测得到的y值,当我们绘制其概率密度直方图时,自然就明白了
# "BNN的输出是一个分布"的特点
# 在下一部分会有展示
# 预测结果
predictions = predict_with_posterior_samples(model, posterior_samples, X_val)
此处关于NUTS的参数特意解释一下:
- num_samples
最终所需的后验样本数。也就是说,MCMC 会生成 num_samples 个样本,表示模型参数的不同取值,这些样本用于进行预测或推断。越多的样本能提高结果的精度,但也会增加计算开销。
- warmup_steps
这表示采样前的“预热”步骤数。MCMC 算法在开始采样之前,会进行一定的迭代来使链条达到平稳状态(如果大家还记得马尔可夫链的细致平稳条件和稳态分布的化就能理解此处了)。通过这些预热步骤,参数的初始值可以调整得更接近真实的后验分布,从而减少不准确的采样。warmup_steps=100 指的是进行 100 次迭代,通常之后的采样才被用来计算最终的后验样本。
3.3 最终结果与效果可视化
为了帮助读者理解BNN的输出为一个分布这一特性,我从验证集中随机挑选了一个 Z = 41 Z =41 Z=41 的核子,也就是 N b Nb Nb 元素,并绘制了其概率密度直方图。
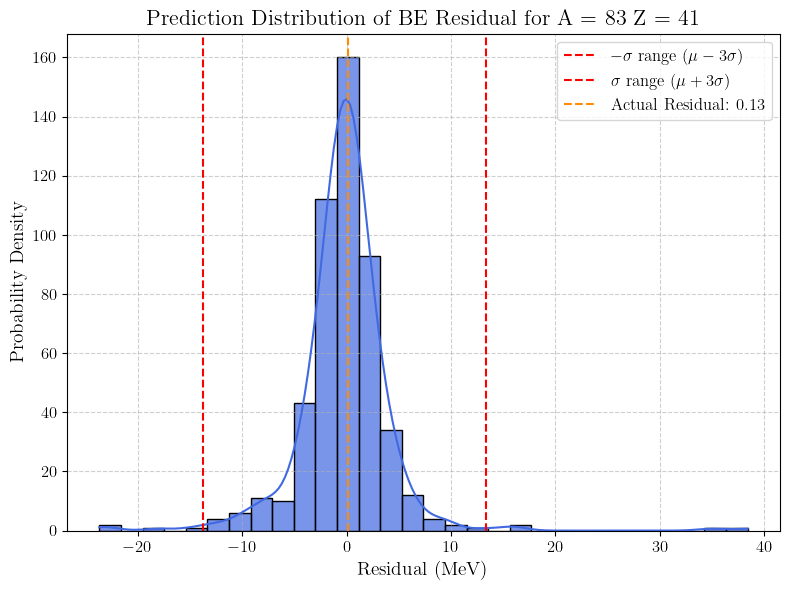
当然,不止是 Z = 41 Z =41 Z=41 ,每一个核子预测出的残差都是一个分布。我们最终取的一个预测值,其实是分布内所有样本点的平均值。
接着我们来看看我们的计算精度与论文的差距:
from sklearn.metrics import mean_squared_error
import numpy as np
def calculate_average_rmse(model, posterior_samples, X_train, y_train, X_val, y_val, num_iterations=50):
train_rmse_sum = 0
val_rmse_sum = 0
for _ in range(num_iterations):
# 训练集预测
train_predictions = predict_with_posterior_samples(model, posterior_samples, X_train)
train_rmse = np.sqrt(mean_squared_error(y_train.numpy(), train_predictions.mean(axis=0)))
train_rmse_sum += train_rmse
# train_predictions.mean(axis=0)这一步其实就是在取平均值
# 验证集预测
val_predictions = predict_with_posterior_samples(model, posterior_samples, X_val)
val_rmse = np.sqrt(mean_squared_error(y_val.numpy(), val_predictions.mean(axis=0)))
val_rmse_sum += val_rmse
average_train_rmse = train_rmse_sum / num_iterations
average_val_rmse = val_rmse_sum / num_iterations
print(f"Average Training RMSE: {average_train_rmse} MeV")
print(f"Average Validation RMSE: {average_val_rmse} MeV")
# 调用函数计算平均RMSE
calculate_average_rmse(model, posterior_samples, X_train, y_train, X_val, y_val)
在给出结果之前,先解释一下为何我要对多次RMSE做平均:
- 因为BNN网络权重和偏置的不确定性,输入相同的 X X X ,得到的 y y y 并不相同,计算得到的RMSE也不相同。可以理解为,RMSE也是一个分布。
- 为了保证最终得到的RMSE是相对可靠的,遂对多次RMSE做一个平均值。
- 理论上,num_samples取得越大,就越容易收敛到同一个RMSE上。这一点我有验证过。当num_samples取为50,不同的num_iterations得到的平均RMSE差异较大。但当其取为500时,和num_iterations的关系就不太大了。
最终,得到的精度约为:
| Accuracy | Value |
|---|---|
| Average Training RMSE | 0.3357 MeV |
| Average Validation RMSE | 0.3842 MeV |
而论文精度为:
| Accuracy | Value |
|---|---|
| Average Training RMSE | 0.178 MeV |
| Average Validation RMSE | 0.222 MeV |
考虑到我采用的原子核结合能的数值原本就大于Mass Excess,所以实际上应该和论文的精度水平差异不大。
此外,如果算力资源足够,再暴力地提高NUTS的两个参数,num_samples和warmup_steps,应该能够再把精度提高一些。
最后在结尾附上使用BNN作为神经网络残差修正项
后的效果可视化:
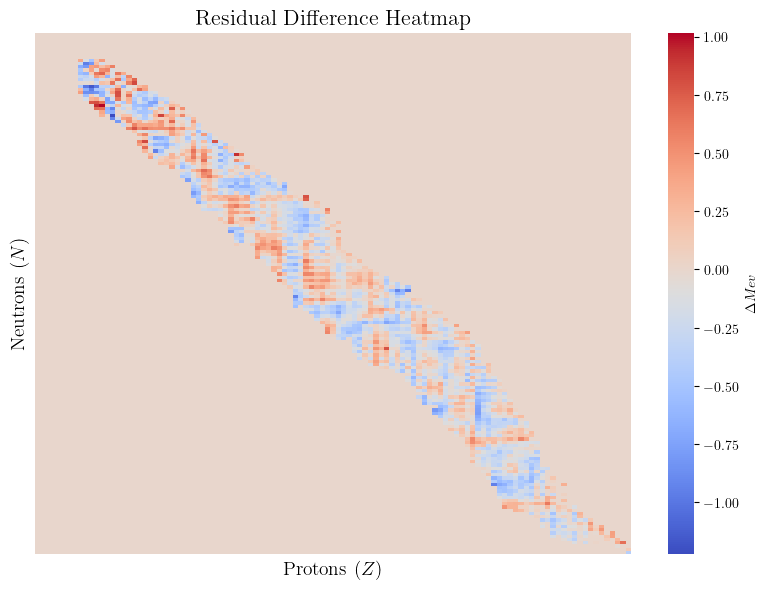
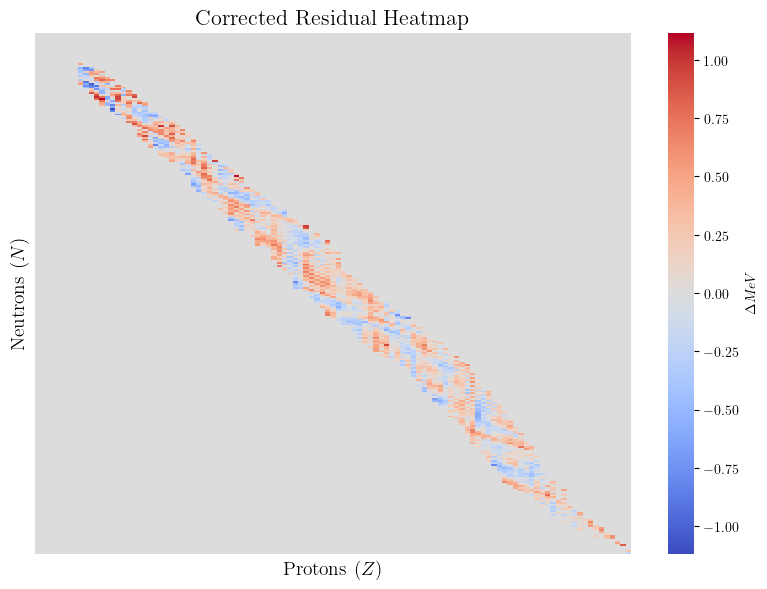
显然,残差明显变小了许多,条带宽度也大大变小。
4.总结及本人写作动机
- 总结
本问主要从BNN与一般MLP的差异入手,帮助读者对BNN有一个宏观认知;接着再切入具体的原理推导,以及常见的优化算法选用。最后附上了使用BNN完成论文复现的实战代码,也做了一定数量的可视化,帮助读者理解。
如果有希望获取完整源码和数据以实战的读者,可以在公众号HORSE RUNNING WILD的后台回复BNN复现。
- 本人写作动机
被大部分BNN教程折磨得头脑发晕,遂觉得势必应该有人出现来教教有一定基础但又本质是小白的科研新手。

















 1804
1804

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









