







目录
0.题目重述与整体分析
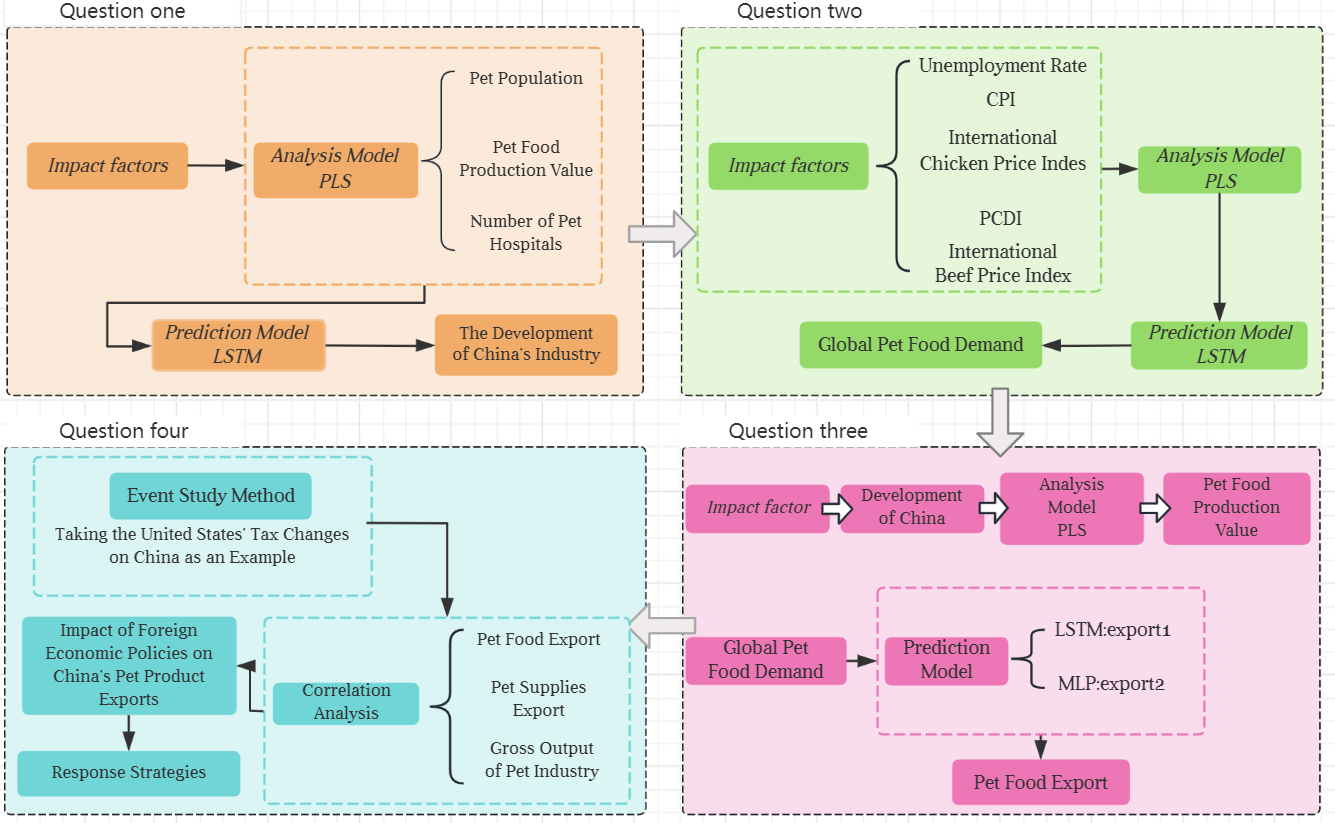
1.Question One
2.Question Two
3.Question Three
4.Question Four
5.总结与提醒
0.题目重述与整体分析
0.1题目要求
原题见APMCM官网
此处仅复述关键信息
- 正式问题之前:
基于附件中的数据以及你的团队收集的额外数据,请分析宠物行业的发展趋势和市场需求。根据你的分析和当前的经济环境,请为中国宠物行业的发展提出相应的战略建议。
- 第一问:
基于附件1中的数据以及你的团队收集的额外数据,分析过去五年中国宠物行业按宠物类型的发展情况。分析中国宠物行业发展的因素,以便构建一个适当的数学模型来预测未来三年中国宠物行业的发展。
- 第二问
基于附件2中的数据以及你的团队收集的额外数据,分析全球宠物行业按宠物类型的发展情况,并构建一个适当的数学模型来预测未来三年全球对宠物食品的需求。
- 第三问
鉴于附件3中中国宠物食品的生产和出口价值,请分析中国宠物食品行业的发展,并基于全球宠物食品市场需求的趋势和中国的发展,预测未来三年中国宠物食品的生产和出口。
- 第四问
考虑附件中的数据、你收集的额外数据以及上述问题的计算结果,定量分析其他国家的外贸政策,对中国宠物食品产业的影响,基于你的计算,请为中国宠物食品行业的可持续发展制定可行的战略。
- 给了哪些数据
此处仅展示附件1,其他给的都是一些年度数据,总之给的数据非常少
| 宠物/年 | 2023 | 2022 | 2021 | 2020 | 2019 |
|---|---|---|---|---|---|
| 猫/万 | 6980 | 6536 | 5806 | 4862 | 4412 |
| 狗/万 | 5175 | 5119 | 5429 | 5222 | 5503 |
0.2整体分析
当我们认真观察第一二三问,会发现题目不断地重复要求我们做两件事:
- 分析XXX的影响
- 预测XXX的未来趋势
观察出这一特点之后,我们就可以在头脑中开始检索模型了:什么模型适合做相关性分析?什么模型适合做回归?
且慢!
抛开具体的情形谈模型都是耍流氓。回到问题一,要求我们分析中国宠物行业发展的因素,那么问题来了,所谓的发展又如何定义?
所以,首先我们应该定义什么是宠物行业的发展的大指标,其次再去寻找可能与之相关的小指标,例如宠物产业的总产值作为大指标,中国人的失业率作为小指标。至于具体的操作,带相关系数的回归分析一抓一大把。
而至于预测未来的趋势,若在刚才已经建立了小指标与大指标的回归方程,则可通过小指标的时间序列预测出小指标的未来数值,接着再利用回归方程获得大指标的未来数值,也就是能够衡量中国宠物产业未来发展的态势。
至于第二问的国际对宠物食品需求,不妨将模型简化为: 某国宠物食品需求 = 该国宠物数量 ∗ 该国养宠物的成本 某国宠物食品需求 = 该国宠物数量 *该国养宠物的成本 某国宠物食品需求=该国宠物数量∗该国养宠物的成本
其他操作,则与第一问如出一辙。同样的道理,第三问同样是要我们分析并预测,只不过指标发生了改变,以及要求我们用上第二问的结果。
稍微有些不同的是第四问,要求我们定量分析其他国家的外贸政策对中国宠物食品产业的影响。政策可不像出口额什么的,每个月变一下;以及例如是关税制裁,可能同时有数个欧美国家拉帮结派地制裁中国,又怎么好定量地分析某一项政策对中国宠物食品产业的影响。
所以第四问就比较考验大家看问题的角度,以及如何简化模型。本文的思路是采用事件研究法(Event Study Method),精确到但对某一个国家的某一项政策在一个事件窗口内,预测正常值与实际值的差异。
1.Question One
1.1发展指标确立
| 衡量发展的大指标 | 作为自变量的小指标 |
|---|---|
| 宠物猫数量 | 文娱方面CPI |
| 宠物狗数量 | 整体CPI |
| 猫总消费 | 城镇失业率 |
| 狗总消费 | 人均GDP |
| 猫狗食品占比 | MRS CG |
| 猫狗食品消费 | TIVPF |
| 宠物医疗占比 | 性别比例 |
| 其他宠物数量 | 无 |
至于为什么选取这些指标,则需要查阅资料,简要论证自己选取这些指标的合理性。比如上述的大指标涵盖了不同的宠物类别、考虑了多种因素,全面地衡量了中国宠物产业的发展状况。
找到的小指标的数据都是从2019年到2023年末的月度数据。
1.2 年度数据插值
考虑到本文获取数据的难度(实际上,因为要找的数据太多太多且难找,找数据花了最长时间),对于大部分的大指标,只能找到年度数据。然而题目又要求了,仅能使用五年内的数据,五个点不可能做出什么好结果的,所以我们最终还是要落实到月度数据上。所以,在假设数据不存在过于奇异的突变的情况下,我们可以考虑使用插值的方法,将年度数据填补为月度数据。
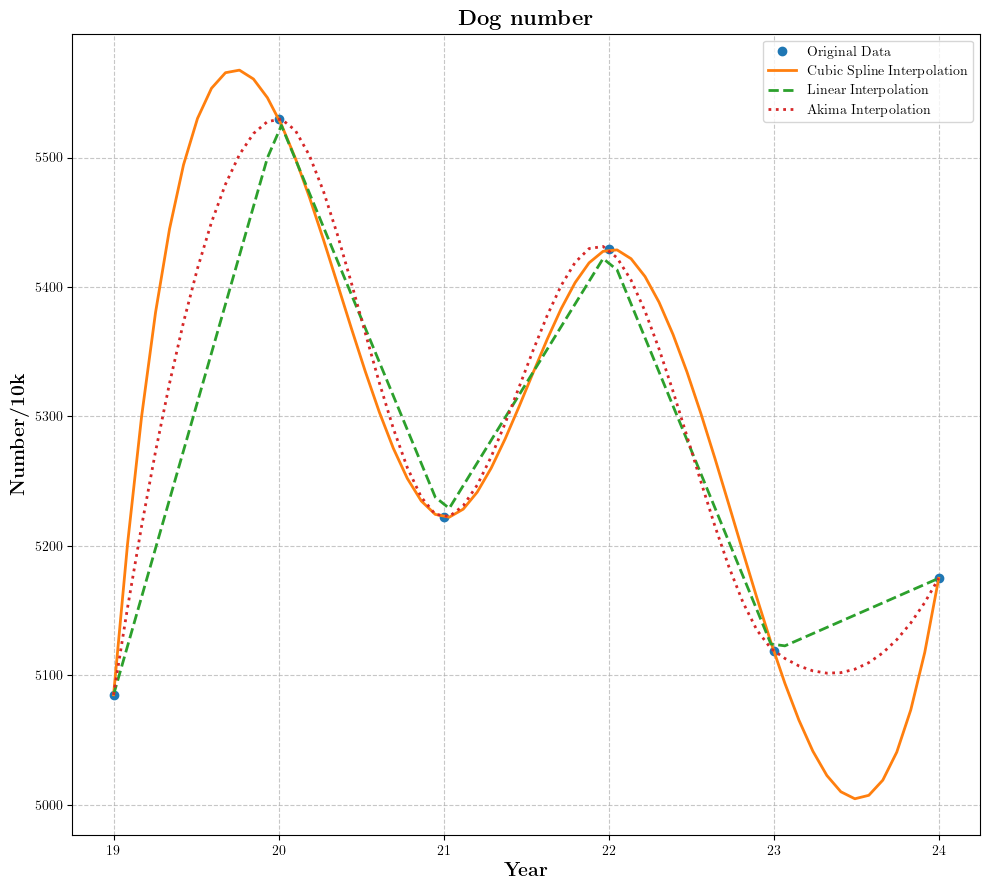
由上图可以观察到,Akima插值相对于三次样条插值更贴合原数据点,我们选择了Akima插值。
(PS:当然,能找到月度数据就不要插值,小指标切忌插值,对模型精度损失很显然)
1.3相关性分析
计算自变量之间皮尔森相关系数,并绘制热力图
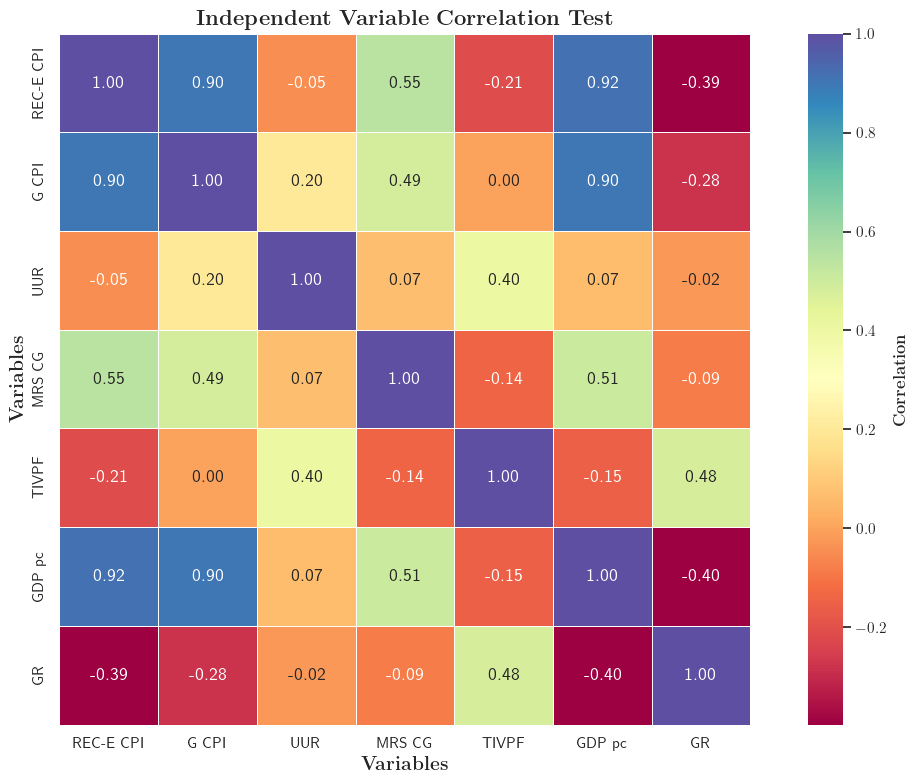
可以发现多重共线性是显然的,我们需要考虑能够排除多重共线性的回归分析模型:
PLS(Partial Least Squares Regression)
1.4 偏最小二乘回归(PLSR)
此处不再赘述偏最小二乘回归原理,大致可以理解为主成分分析法(PCA)与最小二乘法的结合,可以消除自变量的多重共线性进行回归,标准化后回归方程系数即使相关系数。保留了可解释性的情况又能够消除多重共线性,是数模界的一大杀手。具体原理感兴趣可阅读PLSR原理
公众号读者可复制链接至浏览器:
https://www.cnblogs.com/jerrylead/archive/2011/08/21/2148625.html
1.4.1 PLSR主成分计算
但是PLSR存在一个问题,类似于PCA,主成分数需要自己确定。但是好在我们可以通过迭代计算CV-Scores(交叉验证),让程序自动取确定最佳主成分数:
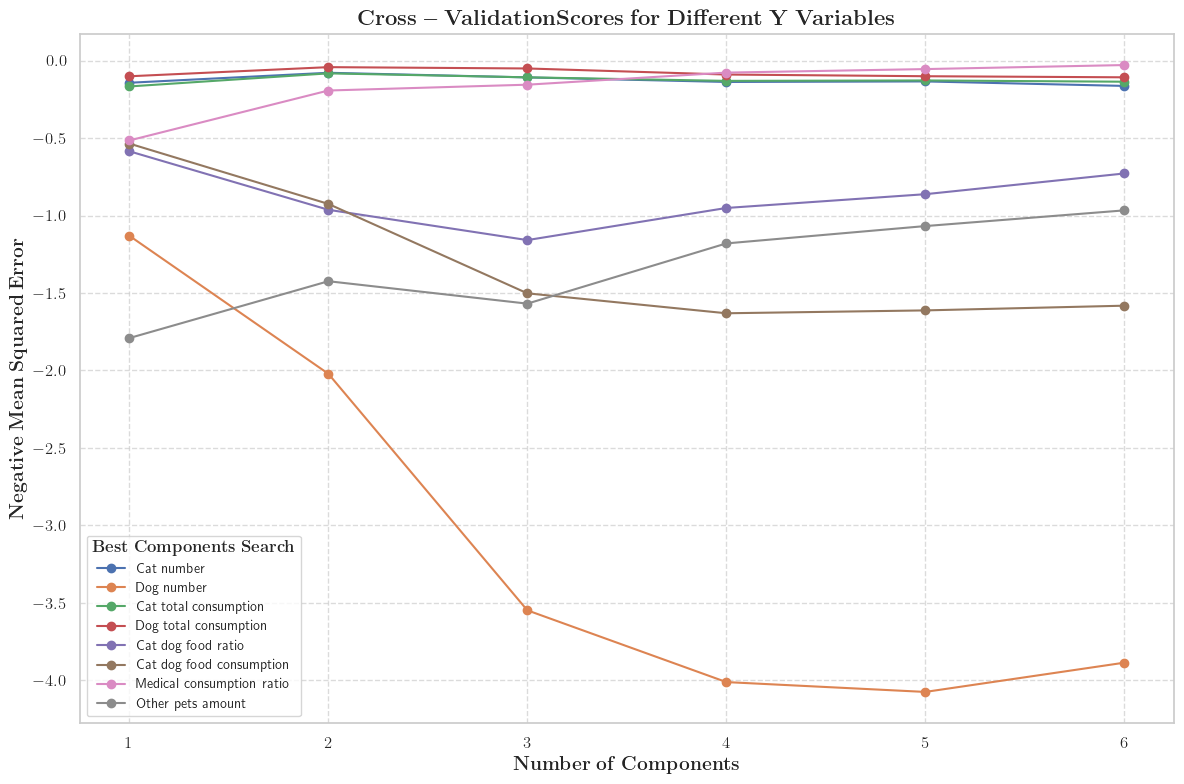
代码示例(可以复制给大模型,这样你自己也能实现了):
# 遍历每个Y指标
for i in range(df_y.shape[1]):
y = df_y.iloc[:, i].values.reshape(-1, 1) # 第i个Y指标
# 标准化Y
scaler_y = StandardScaler()
y_scaled = scaler_y.fit_transform(y)
# 使用交叉验证确定最佳主成分数
cv_scores = []
for n in n_components_range:
pls = PLSRegression(n_components=n)
scores = cross_val_score(pls, x_scaled, y_scaled, cv=5, scoring='neg_mean_squared_error')
cv_scores.append(scores.mean())
best_n_components = n_components_range[np.argmax(cv_scores)]
print(f"Best number of components for Y{i+1}: {best_n_components}")
# 存储结果
cv_scores_all.append(cv_scores)
best_n_components_all.append(best_n_components)
1.4.2 回归方程系数计算
建立模型PLS模型后,找到最佳主成分,传参后即可开算。下列为结果可视化(部分):
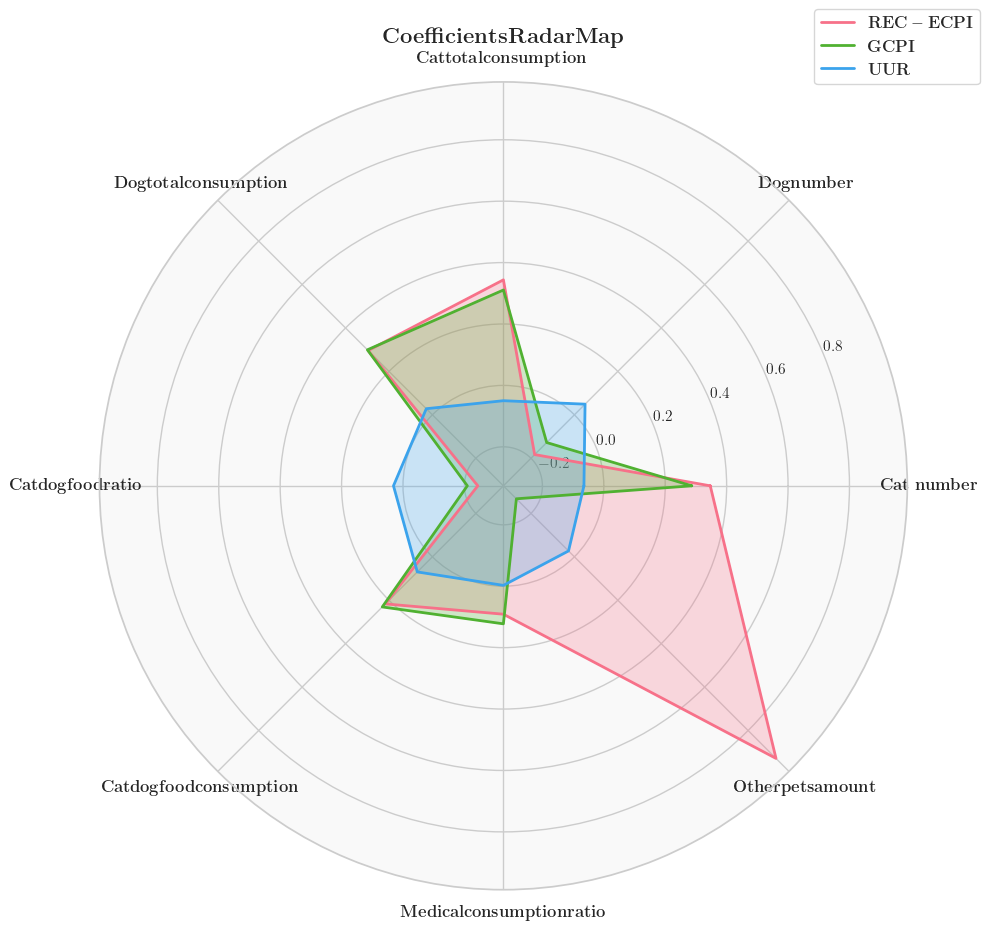
对于标准化后的数据,PLSR方程的系数越大,则说明相关性越强。此处应该论文中对结果进行解释。例如,上图中我们可以发现,文娱方面CPI与其他宠物数量存在强相关性,可能是因为XXXX。
1.5 小指标LSTM回归与超参数调优
毫无疑问,针对单变量时间序列预测,基于LSTM的XXXXX改进肯定是一个相当不错的选择。毕竟在机器学习炼丹流行之前,大家都还在死命地用ARIMA预测来预测去。
简述一下LSTM,则是RNN的改进版,不同于RNN的全盘接受,LSTM能够“选择性”地记住或者忘记重要或不重要的。
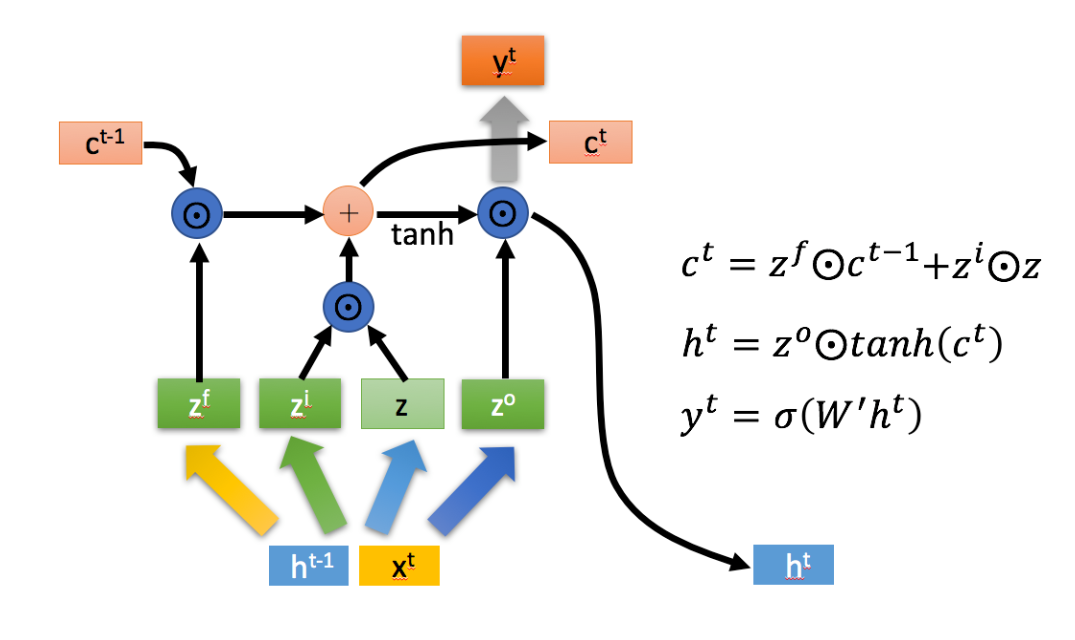
但是使用机器学习方法存在一个最大的问题就是超参数过多,例如:学习率、优化方法、网络层数、每层神经元个数…
所以在此处,我们采用遗传算法进行超参数调优,目标函数可以设置为最小化RMSE,以获得最佳的超参数配置。
1.6 结果
在获得最佳超参数配置后,我们预测得到未来三年的小指标数据,代入原PLRS方程,得到预测结果:
剩下又是文字建模的工作了
2.Question Two
2.1模型简化与指标选取
要求分析全球宠物食品市场的需求,我们肯定不可能找到全球一百多个国家的宠物食品产业情况,然后劈里啪啦一通算。毛主席教导过我们,先抓主要矛盾。
首先,根据《中国宠物行业白皮书》,我们可以说明,宠物食品市场中猫和狗的食品占比远超过其他宠物的食品,故我们仅考虑猫和狗的食品;其次,我们找到了在全球宠物产业占比较大的地区/国家(除中国外):
美国、欧盟、俄罗斯、巴西、日本
当然,其实不同的年份可能是不同的地区/国家,我们无非多选或者少选几个全球市场的代表而已。
第二点则是我们应该考虑需求的含义。我们是不可能从哪个国家的统计局找到“食品需求”这一条目,只能由我们自己定义。不失一般性,我们不妨按照如下方式简化:
某国宠物食品需求
=
该国宠物数量
∗
该国养宠物的成本
某国宠物食品需求 = 该国宠物数量 *该国养宠物的成本
某国宠物食品需求=该国宠物数量∗该国养宠物的成本
这样,我们回归模型的Y指标就出现了:各国的宠物数量变化!
和第一问相同,我们应该继续去找小指标。在此处,考虑到找数据的难度,我们保持各个的大部分小指标相同,个别小指标可以不同。指标展示如下
| 地区/国家 | 指标1 | 指标2 | 指标3 | 指标4 | 指标5 |
|---|---|---|---|---|---|
| 美国 | 失业率 | 杂项商品CPI | 结婚率 | 鸡肉价格指数 | 人均可支配收入 |
| 巴西 | 失业率 | 总体CPI | 结婚率 | 国际牛肉价格 | 人均可支配收入 |
| 俄罗斯 | 失业率 | 总体CPI | 结婚率 | 国际牛肉价格 | 人均可支配收入 |
| 欧盟 | 失业率 | 杂项商品CPI | 结婚率 | 国际牛肉价格 | 人均可支配收入 |
| 日本 | 失业率 | 总体CPI | 结婚率 | 国际牛肉价格 | 人均可支配收入 |
2.2年度数据插值及其他准备工作
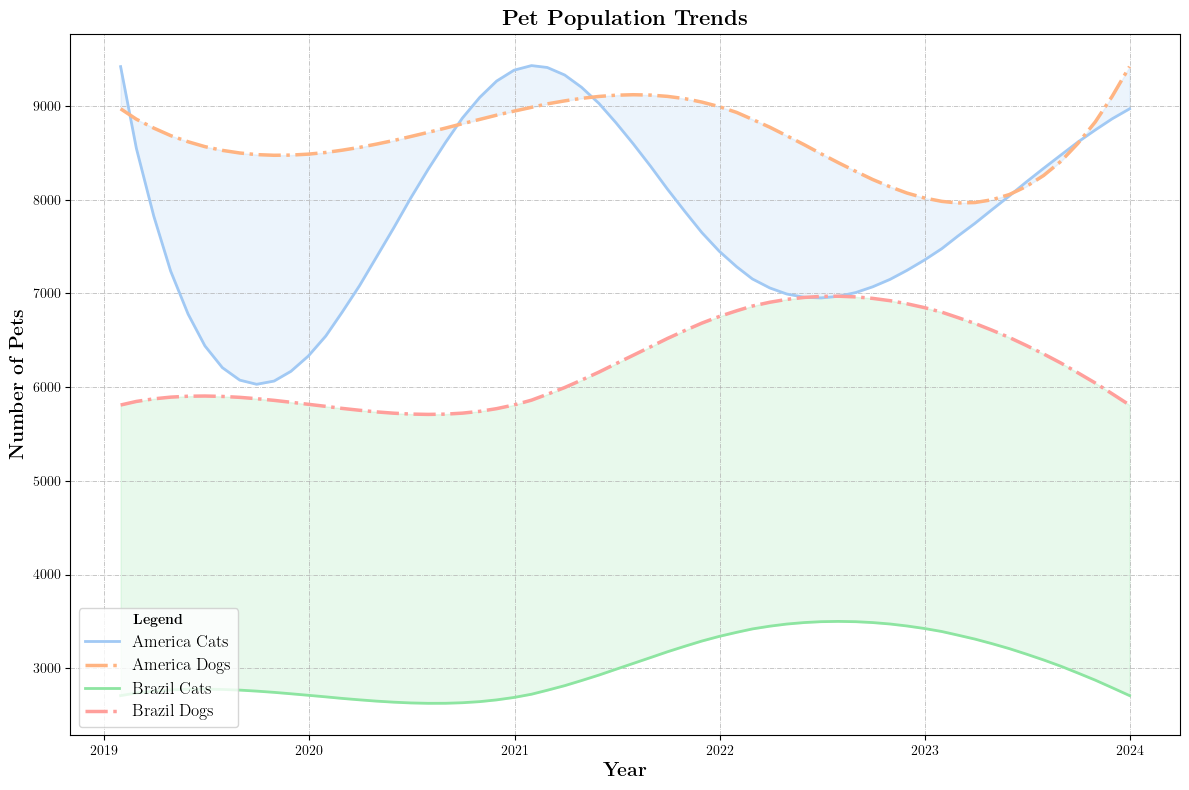
类似于第一问,我们需要进行:
- 年度数据插值
- 多重共线性验证
- 相关系数的计算
- 得到最终的回归方程
- ‘找到各国养猫和狗在食物上花费的成本’
最后一点的难度实际较大,因为不同的机构统计出来的数据差异极大。最终我们决定,将收集到的不同年份的各国养猫和狗在食物上花费的成本进行最小二乘回归,一是取了一个相对平均的结果,二是还可以用之预测未来年份的养猫和狗在食物上花费的成本,用以计算未来的需求。
2.3LSTM自变量回归与最终预测
该部分的流程如下:
- LSTM超参数寻优
- LSTM预测自变量
- 代入原回归方程,得到宠物数量预测值
- 将各国各时间段预测值乘以成本并加和,得到全球市场总需求
因为套路一模一样,故不再水字数了。
3.Question Three
3.1 题目分析与指标选取
题目要求我们做两件事:
- Part1:分析中国宠物食品行业的发展
- Part2:基于全球宠物食品市场需求的趋势和中国的发展,预测未来三年中国宠物食品的生产和出口
第一件事与第一问无异,并且还更贴心地将Y给我们缩减到了仅有一个“中国宠物食品行业”,我们完全可以直接找中国宠物食品行业的产值数据。
而针对第二个问题,我们则可以考虑一个非常简单粗暴的方式:将中国宠物食品市场产值,与全球宠物食品市场需求,作为X;将中国的食品出口总额,作为Y,然后直接使用多层感知机(MLP)回归。
3.2 Part1 分析 & 发展
3.2.1 PLS常规操作
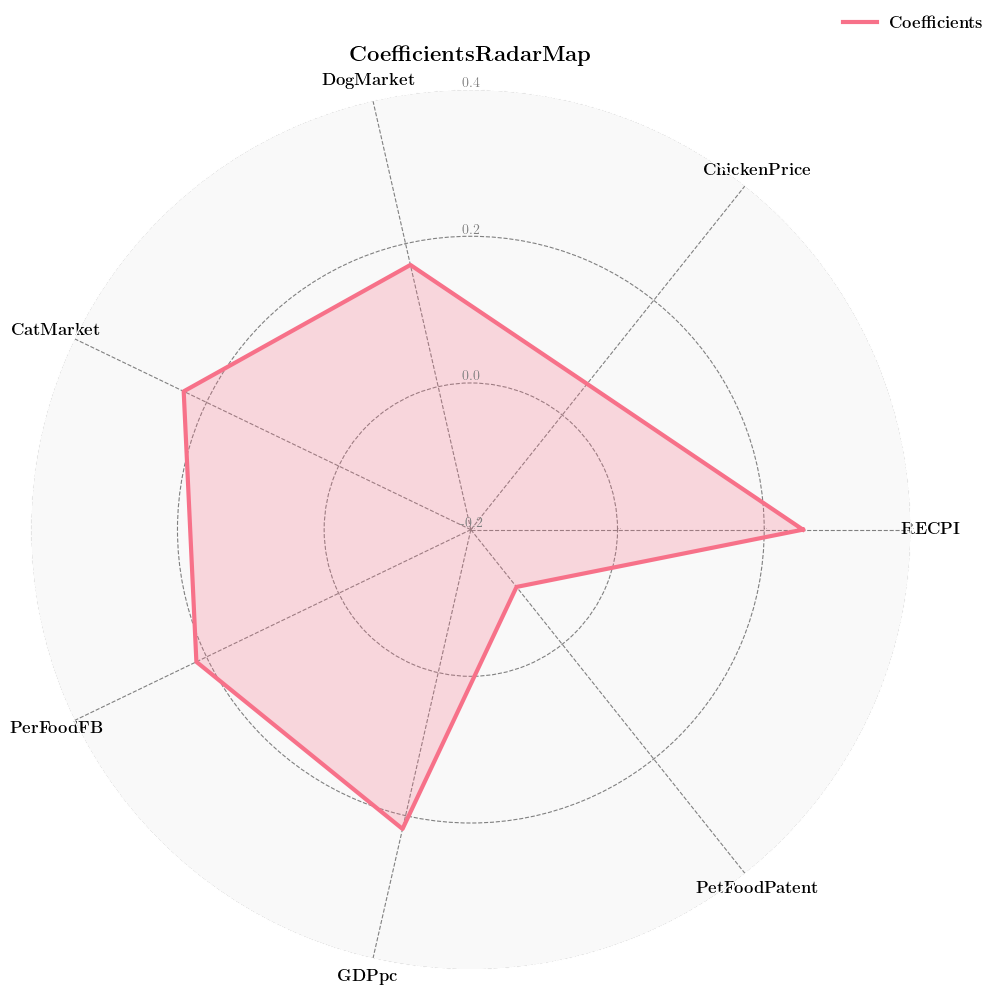
下表格列出了我们选取的小指标:
| 小指标 |
|---|
| 文娱方面CPI |
| 鸡肉价格 |
| 宠物狗市场额 |
| 宠物猫市场额 |
| 人均GDP |
| 宠物食品相关专利 |
| Per Food FB |
还是与第一问套路相同,我们需要进行:
- 多重共线性验证
- 相关系数的计算
- 得到最终的回归方程
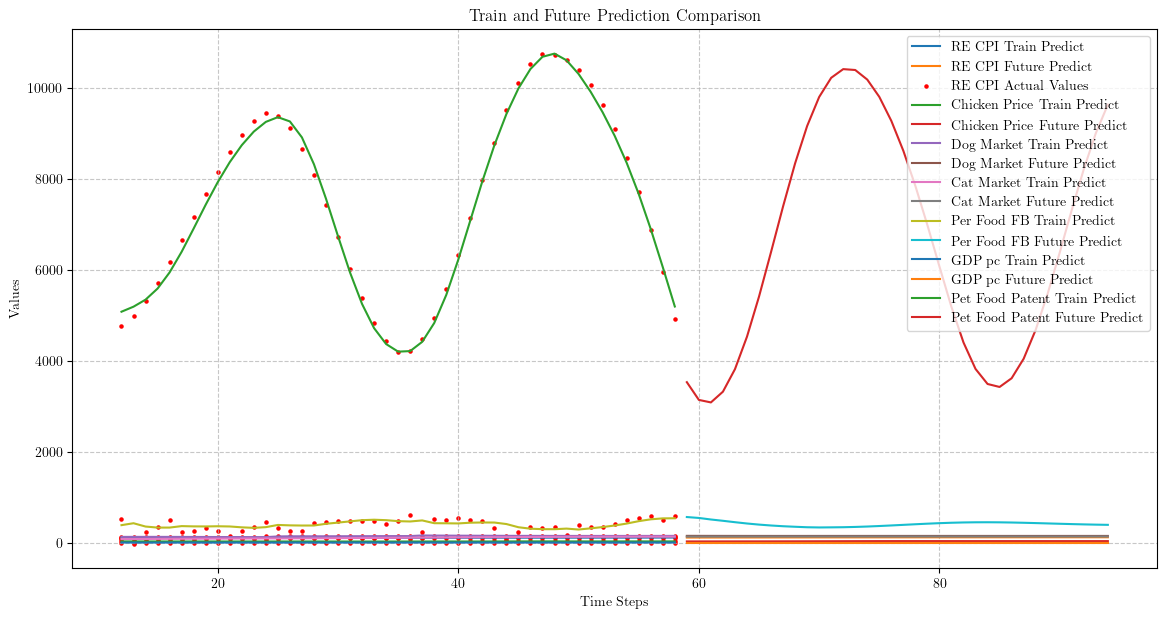
3.2.2 LSTM常规操作
该部分的流程如下:
- LSTM超参数寻优
- LSTM预测自变量
- 代入原回归方程,得到宠物产业产值预测值
3.3 Part2 基于双指标预测
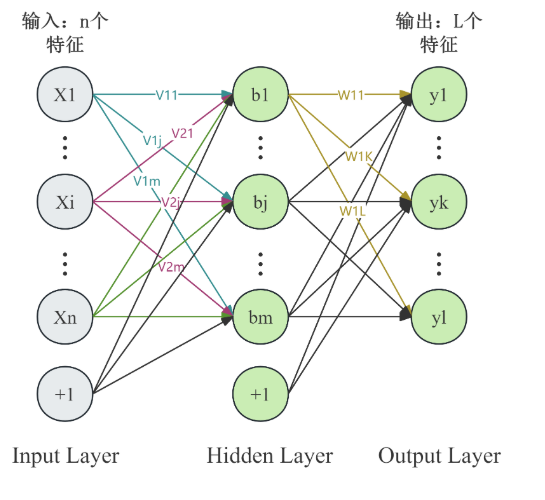
多层感知机,即MLP(Multilayer Perceptron),是其他更高级的人工神经网络的基础。对人工神经网络没有了解的读者可参考小白笔记:对MLP多层感知机概念、结构、超参数的理解
公众号读者(还没在数模领域接触到机器学习的玩家)可复制链接打开:
https://blog.youkuaiyun.com/m0_73798143/article/details/136636647
此处首先简要阐释为何本小组选择MLP:
- 数据的X有两个输入维度,使用LSTM效果不一定更好。
- 数据的X只有两个输入维度,不适用BNN或者SVR等适用于高维度小样本的机器学习方法。
- 数据样本量较小,使用复杂一点的网络及其容易过拟合,不如使用到最简单的MLP,超参数调整还更方便。
当然,以上仅仅是本小组的思路,仅作为参考。也肯定存在不足之处。
MLP的操作流程类似LSTM:
- MLP超参数寻优
- 使用MLP进行回归,得到结果。
4.Question Four
4.1问题分析与模型简化
第四问,要求我们定量分析其他国家的外贸政策对中国宠物食品产业的影响。这个要求似乎看着有点让人头大,因为其他国家外贸政策那么多,这世上发生的事情也那麽多,我又怎么敢说中国宠物食品产业迎来复兴是因为关税下降而不是某项专利大放异彩?
当然,这毕竟是数学建模,我们应该对模型进行合理的简化。外贸政策无论再怎么变动,最终都会直接或者间接地影响到关税,所以我们将外贸政策简化为关税调整。中国宠物食品产业涉及许多方面,和关税最相关的则是出口额,更具体一点,是对调整关税国的出口额。
顺着上述思路,又结合着查阅资料,我们最终能够选择一个具体的目标:美国对中国的关税调整,与中国对美国的宠物食品出口额。
解决了模型简化的问题,我们就应该开始考虑具体的定量分析。该问题的难点在于,常规的回归分析和相关性分析不再适用:中国对美国的宠物食品出口额可以获得月度数据,但是美国对中国的关税从2018年到2023年就只变动过两次。
为此,我们应该关注的是,在关税政策调整的时间前后,出口额的变化。更具体而言,有一种更专业的方法:
事件研究法(Event Study)
4.2 事件研究法
事件研究法是一种定量分析技术,用于评估特定事件对股票价格或其他经济指标的影响。它在金融领域广泛应用,特别是在评估重大企业事件(如合并与收购、盈利公告、政策变化等)对股票价格的影响。
- 事件窗口:
这指的是围绕事件发生的时期,在这段时间内,研究人员观察关税调整对中国宠物食品出口额的影响。事件窗口的设定通常包括事件发生当月及其前后几月。
- 估计窗口:
这是在事件窗口之前选择的一个较长的时期,用于估计正常回报率。这个窗口用于建立中国宠物食品出口额正常行为的模型,作为我们的基准模型。简单的可以采用线性回归模型,在本题中我们采用ARIMA模型。
- 异常回报(AR):
这指的是在事件窗口期间,中国宠物食品出口实际值与模型预测的正常值之间的差异。异常回报是事件研究法的核心,用于量化事件的影响。
- 累积异常回报(CAR):
这是在事件窗口期间异常回报的累积值,用于评估事件对股票价格的整体影响。
4.3 基准模型–ARIMA
ARIMA模型,全称为自回归差分移动平均模型(Autoregressive Integrated Moving Average Model),是一种广泛应用于时间序列分析和预测的统计方法。它最初由乔治·博克斯(George Box)和格温·詹金斯(Gwilym Jenkins)在20世纪70年代初期提出,因此也被称作Box-Jenkins模型。ARIMA模型的核心在于它能够处理非平稳的时间序列数据,通过差分使得数据序列变得平稳,进而使用自回归(AR)和移动平均(MA)模型来描述数据的动态特性。也是数学建模中非常常用的一种处理时间序列的模型
此处简要介绍ARIMA模型。该模型由三个主要部分组成:自回归(AR)、差分(I)、移动平均(MA)。每个部分都由一个参数来描述,分别是 p p p、 d d d、 q q q,因此ARIMA模型通常被表示为 ARIMA( p , d , q p, d, q p,d,q)。
-
自回归部分(AR)
表示当前值与过去值之间的关系。如果一个时间序列的当前值 Y t Y_t Yt 与前 p p p 个时间点的值 Y t − 1 , Y t − 2 , … , Y t − p Y_{t-1}, Y_{t-2}, \ldots, Y_{t-p} Yt−1,Yt−2,…,Yt−p 线性相关,那么我们说这个序列有一个 p p p 阶的自回归结构。自回归模型的公式可以表示为:
Y t = c + ϕ 1 Y t − 1 + ϕ 2 Y t − 2 + … + ϕ p Y t − p + ϵ t Y_t = c + \phi_1 Y_{t-1} + \phi_2 Y_{t-2} + \ldots + \phi_p Y_{t-p} + \epsilon_t Yt=c+ϕ1Yt−1+ϕ2Yt−2+…+ϕpYt−p+ϵt
其中, c c c 是一个常数项, ϕ i \phi_i ϕi 是自回归系数, ϵ t \epsilon_t ϵt 是误差项,代表当前值与过去值之间的差异。 -
差分部分(I)
表示对时间序列进行差分操作的次数,目的是将非平稳的时间序列转换为平稳的时间序列。如果原始序列是非平稳的,通过一次或多次差分处理后,可以消除时间序列中的趋势和季节性成分,使之成为平稳序列。差分次数用 d d d 表示。 -
移动平均部分(MA)
表示当前值与过去预测误差之间的关系。如果一个时间序列的当前值 Y t Y_t Yt 受到过去 q q q 个时间点预测误差 ϵ t − 1 , ϵ t − 2 , … , ϵ t − q \epsilon_{t-1}, \epsilon_{t-2}, \ldots, \epsilon_{t-q} ϵt−1,ϵt−2,…,ϵt−q 的影响,那么我们说这个序列有一个 q q q 阶的移动平均结构。移动平均模型的公式可以表示为:
Y t = μ + ϵ t + θ 1 ϵ t − 1 + θ 2 ϵ t − 2 + … + θ q ϵ t − q Y_t = \mu + \epsilon_t + \theta_1 \epsilon_{t-1} + \theta_2 \epsilon_{t-2} + \ldots + \theta_q \epsilon_{t-q} Yt=μ+ϵt+θ1ϵt−1+θ2ϵt−2+…+θqϵt−q
其中, μ \mu μ 是序列的平均值, θ i \theta_i θi 是移动平均系数。
ARIMA模型的实际使用,还需要通过绘制时间序列图、自相关图(ACF)、偏自相关图(PACF)以及进行ADF单位根检验等方法,判断时间序列是否平稳以及给模型定阶等,具体可见ARIMA模型建模教程
公众号读者可复制到浏览器打开:
https://blog.youkuaiyun.com/abc200941410128/article/details/109360494
在本文中不再赘述这些过程。
4.4 结果分析及战略意见
我们最终选择研究事件以及模型参数:
- 2018年九月美国对中国宠物食品出口加征10%关税
- 2019年五月美国对中国宠物食品出口加征25%关税
- 事件窗口选为七个月
- ARIMA模型选择 p , d , q = 3 , 1 , 3 p,d,q = 3,1,3 p,d,q=3,1,3
结果展示:
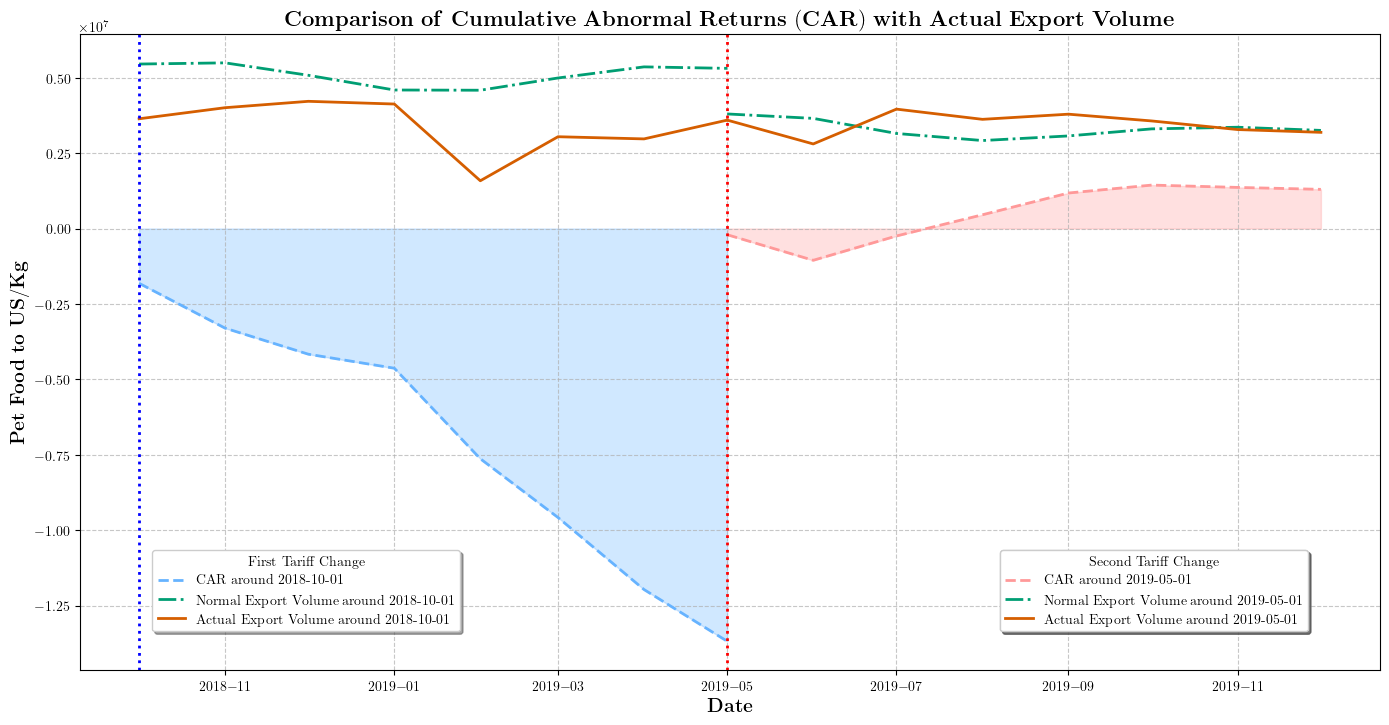
如上图,我们可以发现对于美国第一次加征关税,给中国宠物食品产业造成了很大的影响;但第二加征到25%的关税,反而还没那么大的影响了。
我们可以从许多的角度去分析,例如中国宠物食品产业扔向增强呀,中国宠物食品产业对美国依赖度较高等等,并借此给出我们的战略意见。
5.总结与提醒
本题的难度不大,但是找数据相当折磨人。公众号后台回复**(2024APMCM)** 可找我获取源码和数据。
严格意义上,这道题找数据存在相当多的技巧,以下为一段对话实录:
队友:月度数据?我觉得你这个想法是不现实的,根本没有机构会闲着没事每个月统计一次中国出口到美国的宠物食品数量,尤其是早起中国宠物食品市场尚未成熟。毕竟,你要知道,我已经全身心找了两天了,只能找到年度数据。
我:’三分钟之后打开了海关总署数据库‘。
但此处不详细讲解找数据以及其他技巧。主要是提醒各位,耐心与技巧同等重要。
此外,一定要有时间意识。事实上,本文写作的动机,正是因为在准备提交论文的时刻,发现自己记错了交论文的时间。上一秒还在感慨一等奖有手就行,下一秒

同时也欢迎优快云读者关注本人公众号 “HORSE RUNNING WILD”, 后台回复**(2024APMCM)** ,可找我获取源码和数据!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









