







 Hive是一个基于Hadoop的数据仓库工具,提供类SQL查询功能,适用于大数据集的批处理作业。它支持多种计算引擎,具有灵活的ETL、易于编程等特性。Hive架构包括HiveServer、MetaStore等组件,通过HiveQL进行数据操作。分区和分桶是优化查询效率的重要手段,分桶表创建时需指定分桶字段和数量。Hive还支持托管表和外部表,满足不同场景需求。
Hive是一个基于Hadoop的数据仓库工具,提供类SQL查询功能,适用于大数据集的批处理作业。它支持多种计算引擎,具有灵活的ETL、易于编程等特性。Hive架构包括HiveServer、MetaStore等组件,通过HiveQL进行数据操作。分区和分桶是优化查询效率的重要手段,分桶表创建时需指定分桶字段和数量。Hive还支持托管表和外部表,满足不同场景需求。
简介
Hive是基于静态批处理Hadoop的一个数据仓库工具,通过Hive可以实现将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,同时将sql语句转换为MapReduce任务进行运行,所以其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计。Hive具有sql数据库的外表,但应用场景完全不同,Hive 适合高延迟的查询,Hive并不提供实时的查询和基于行级的数据更新操作,所以Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析
Hive特性
·灵活方便的ETL(extract/transform/load)。
·支持Iez,Spark等多种计算引擎。
·可直接访问HDFS文件以及HBase。
·易用易编程。
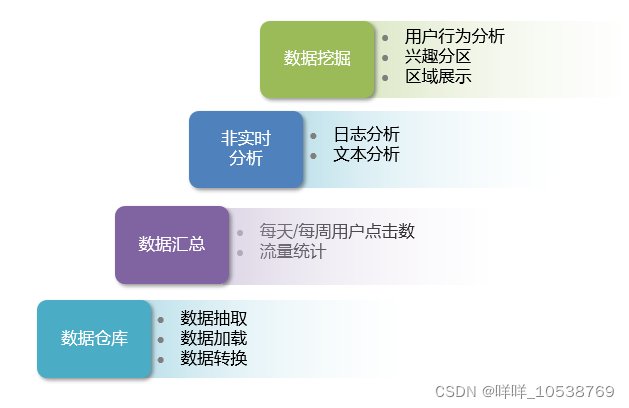
Hive应用场景
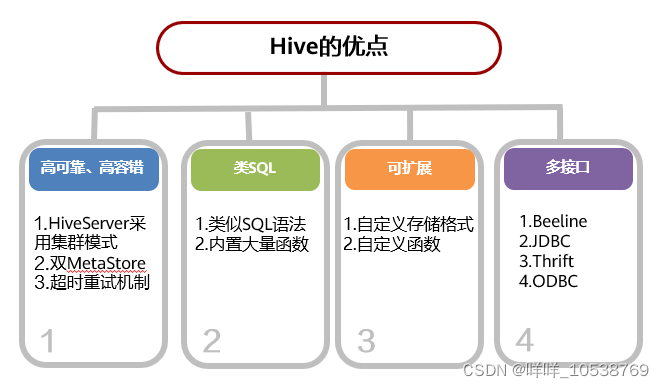
Hive优点
HiveServer Hive对外提供SQL服务的主要进程。
MetaStore Hive提供元数据信息的进程,可供HiveServer,SparkSQL,Oozie等组件调用。
Beeline hive 命令行客户端。
JDBC java统一数据库接口。
Thrift一种序列化、通信协议。
ODBC基于C/C++的数据库标准接口。
HIve架构
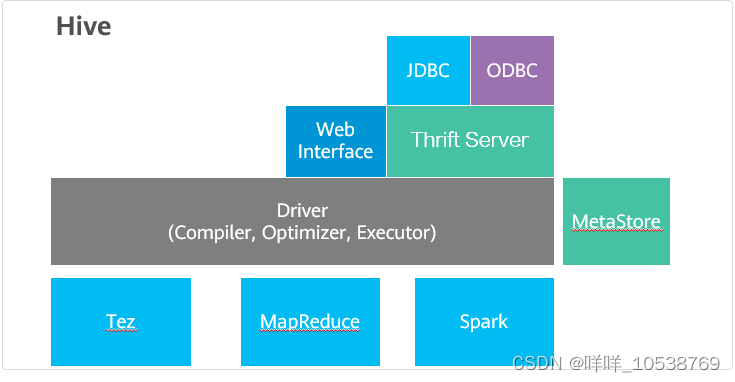
MetaStore:存储表、列和Partition等元数据。
Driv
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









