







YOLOv3: An Incremental ImprovementYOLOv3:增量式的改进Joseph Redmon Ali FarhadiUniversity of Washington |
Abstract
We present some updates to YOLO! We made a bunch of little design changes to make it better. We also trained this new network that’s pretty swell. It’s a little bigger than last time but more accurate. It’s still fast though, don’t worry. At 320×320 YOLOv3 runs in 22 ms at 28.2 mAP, as accurate as SSD but three times faster. When we look at the old .5 IOU mAP detection metric YOLOv3 is quite good. It achieves 57:9 AP50 in 51 ms on a Titan X, compared to 57.5 AP50 in 198 ms by RetinaNet, similar performance but 3.8× faster. As always, all the code is online at https://pjreddie.com/yolo/.
摘要
我们对YOLO进行了一系列更新!它包含一堆小设计,可以使系统的性能得到更新。我们也训练了一个新的、比较大的神经网络。虽然比上一版更大一些,但是精度也提高了。不用担心,它的速度依然很快。YOLOv3在320×320输入图像上运行时只需22ms,并能达到28.2mAP,其精度和SSD相当,但速度要快上3倍。使用之前0.5 IOU mAP的检测指标,YOLOv3的效果是相当不错。YOLOv3使用Titan X GPU,其耗时51ms检测精度达到57.9 AP50,与RetinaNet相比,其精度只有57.5 AP50,但却耗时198ms,相同性能的条件下YOLOv3速度比RetinaNet快3.8倍。与之前一样,所有代码在网址:https://pjreddie.com/yolo/。
1. Introduction
Sometimes you just kinda phone it in for a year, you know? I didn’t do a whole lot of research this year. Spent a lot of time on Twitter. Played around with GANs a little. I had a little momentum left over from last year [12] [1]; I managed to make some improvements to YOLO. But, honestly, nothing like super interesting, just a bunch of small changes that make it better. I also helped out with other people’s research a little.
1. 引言
有时候,一年内你主要都在玩手机,你知道吗?今年我没有做很多研究。我在Twitter上花了很多时间。研究了一下GAN。去年我留下了一点点的精力[12] [1];我设法对YOLO进行了一些改进。但是,实话实说,除了仅仅一些小的改变使得它变得更好之外,没有什么超级有趣的事情。我也稍微帮助了其他人的一些研究。
Actually, that’s what brings us here today. We have a camera-ready deadline [4] and we need to cite some of the random updates I made to YOLO but we don’t have a source. So get ready for a TECH REPORT!
其实,这就是今天我要讲的内容。我们有一篇论文快截稿了,并且我们还缺一篇关于YOLO更新内容的文章作为引用,但是我们没有引用来源。因此准备写一篇技术报告!
The great thing about tech reports is that they don’t need intros, y’all know why we’re here. So the end of this introduction will signpost for the rest of the paper. First we’ll tell you what the deal is with YOLOv3. Then we’ll tell you how we do. We’ll also tell you about some things we tried that didn’t work. Finally we’ll contemplate what this all means.
技术报告的好处是他们不需要引言,你们都知道我为什么写这个。所以引言的结尾可以作为阅读本文剩余内容的一个指引。首先我们会告诉你YOLOv3的方案。其次我们会告诉你我们是如何实现的。我们也会告诉你我们尝试过但并不奏效的一些事情。最后我们将探讨这些的意义。
2. The Deal
So here’s the deal with YOLOv3: We mostly took good ideas from other people. We also trained a new classifier network that’s better than the other ones. We’ll just take you through the whole system from scratch so you can understand it all.
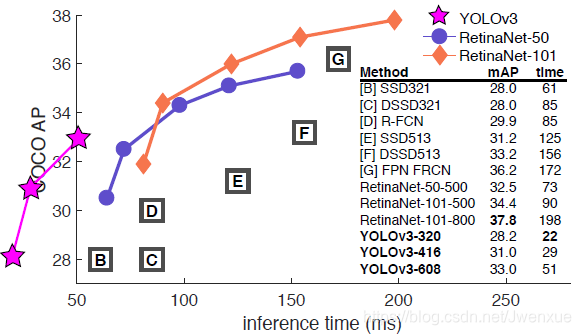
Figure 1. We adapt this figure from the Focal Loss paper [9]. YOLOv3 runs significantly faster than other detection methods with comparable performance. Times from either an M40 or Titan X, they are basically the same GPU.
2. 方案
这节主要介绍YOLOv3的方案:我们主要从其他人的研究工作里获得了一些好思路、好想法。我们还训练了一个新的、比其他网络更好的分类网络。为了方便您理解,我们将带您从头到尾贯穿整个模型系统。
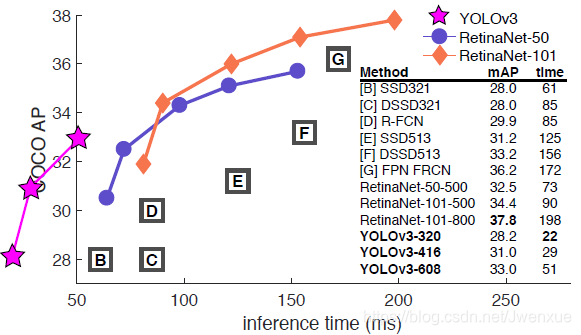
图1.这个图来自Focal Loss论文[9]。YOLOv3的运行速度明显快于其他具有可比性能的检测方法。检测时间基于M40或Titan X(这两个基本上是相同的GPU)。
2.1. Bounding Box Prediction
Following YOLO9000 our system predicts bounding boxes using dimension clusters as anchor boxes [15]. The network predicts 4 coordinates for each bounding box, tx, ty, tw, th. If the cell is offset from the top left corner of the image by (cx; cy) and the bounding box prior has width and height pw, ph, then the predictions correspond to:
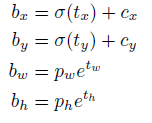
2.1 边界框预测
按照YOLO9000,我们的系统也使用维度聚类得到的anchor框来预测边界框[15]。网络为每个边界框预测的4个坐标:tx、ty、tw、th。假设格子距离图像的左上角偏移量为(cx,cy),先验边界框宽度和高度分别为:pw、ph,则预测结果对应为:
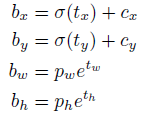
During training we use sum of squared error loss. If the ground truth for some coordinate prediction is ^t* our gradient is the ground truth value (computed from the ground truth box) minus our prediction: ^t* - t*. This ground truth value can be easily computed by inverting the equations above.
训练时我们使用误差平方和损失。如果某个预测坐标的真值是
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









