



 https://leetcode-cn.com/problems/subsets/solution/c-zong-jie-liao-hui-su-wen-ti-lei-xing-dai-ni-gao-/
https://leetcode-cn.com/problems/subsets/solution/c-zong-jie-liao-hui-su-wen-ti-lei-xing-dai-ni-gao-/
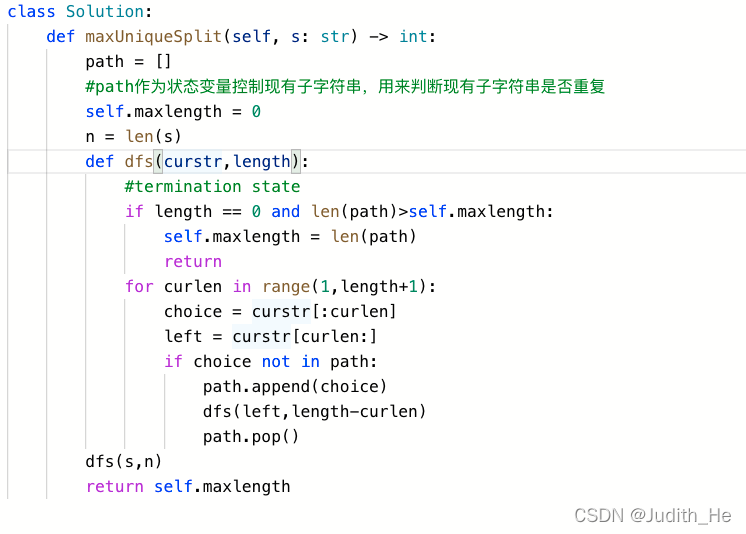 path作为状态变量控制现有子字符串,用来判断现有子字符串是否重复
path作为状态变量控制现有子字符串,用来判断现有子字符串是否重复
画图分析:
当现有string的长度为零时停止(成功分完原字符串)
可选范围为当前字符串的不同长度(从1到n)非空子串,
利用path储存当前已经分离好的子串,后面的子串不可重复
dfs(curstr,length)
curstr:当前node中剩余字符串;length:当前node中字符串长度
若后面的子串与path储存当前已经分离好的子串重复,停止当前道路的搜索,回朔直到找到正确的path。

来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/split-a-string-into-the-max-number-of-unique-substrings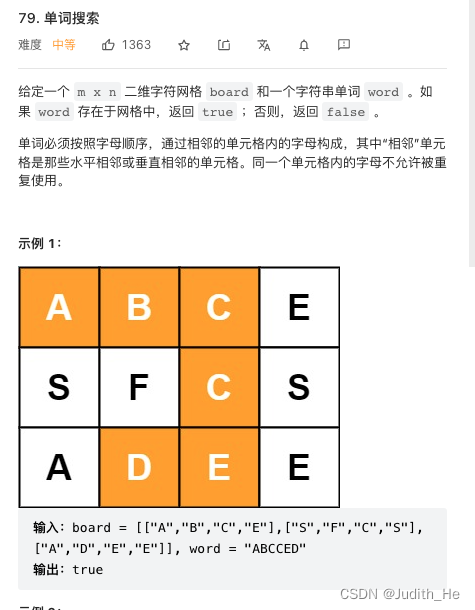
n,m = len(board),len(board[0])
visited = set()
def dfs(i,j,visited,cur_word):
#return whether there exists a path from [i][j] that can form cur_word
#结束条件
if not cur_word:#考虑边界条件,word search 完了再超出边界无所谓,我反正已经搜索完了
return True
if not (0<=i<n and 0<=j<m) or (i,j) in visited: #word search没有搜索完的时候超出边界或者走回老路,这类路线(超出边界或走回头路的路线)不可能完成搜索任务,return False
return False
if board[i][j] != cur_word[0]: #仍在合法区域但是当前路线和word最前面的字符不匹配,此路径不可完成目的
return False
#合法区域但是当前路线和word最前面的字符匹配, 但是为search 完word
# 继续走
visited.add((i,j))
if dfs(i+1,j,visited,cur_word[1:]) or dfs(i-1,j,visited,cur_word[1:]) or dfs(i,j-1,visited,cur_word[1:]) or dfs(i,j+1,visited,cur_word[1:]):
return True
else:
#若不满足条件,退回原来的交叉口: 此路径之后的四个方向均不可走,该路径为死路
visited.remove((i,j))
return False
for i in range(n):
for j in range(m):
if board[i][j] == word[0]:
if dfs(i,j,visited,word):
return True
return False


















 1315
1315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









