



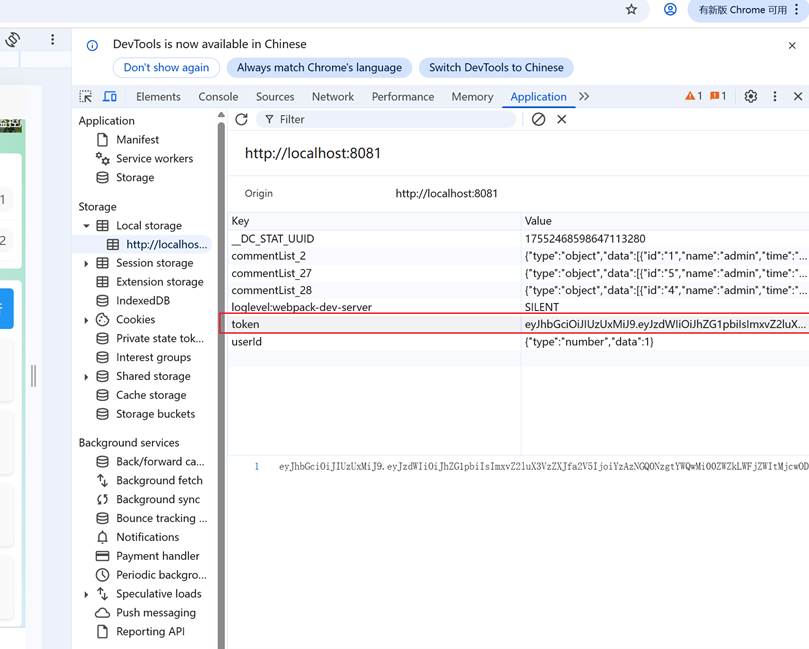
- 把token替换到apifox
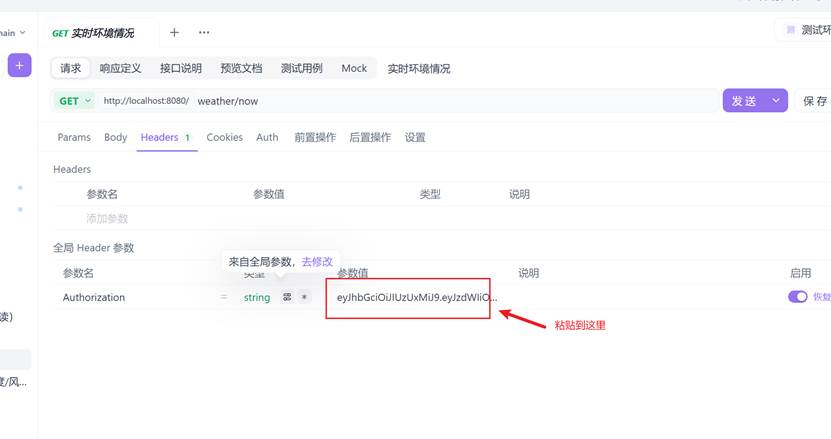
- 发送请求,查看返回的数据结果
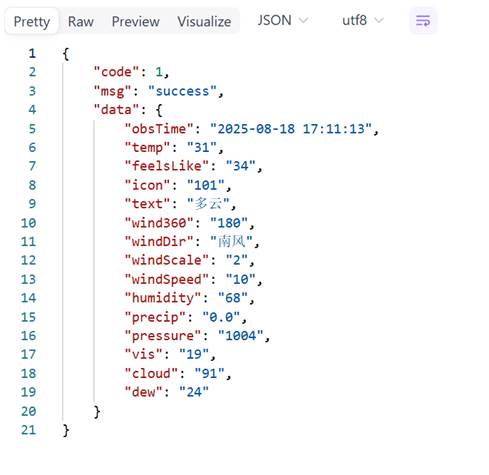
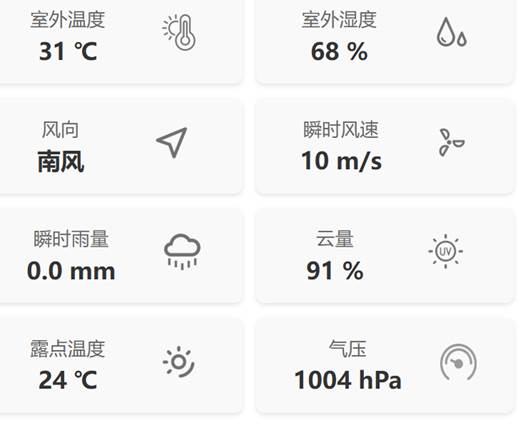
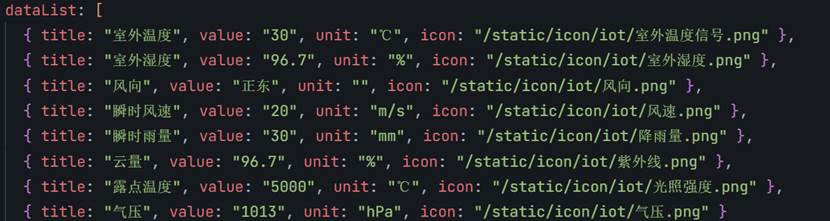
看看返回的英文参数跟页面的参数能不能对应,不能的话就改动一下(我把光强和紫外线替换了)
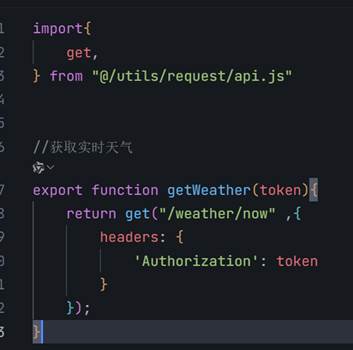
- 问ai,把接口和返回的数据都给他,这里我写好接口了
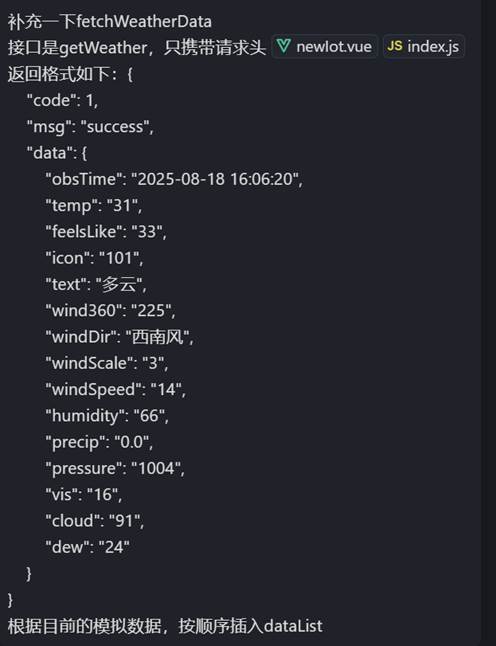
- ai写完了 运行,如果页面正常获取就成功了,如果报错就一点点调试,
我感觉一般就两个问题,一个是接口没通,一个是字段不对
通过在调用接口的下面打印,判断接口有没有通
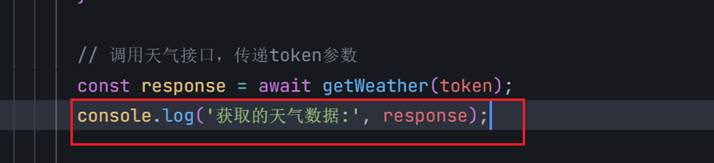
这边不能正常打印就说明页面传递的参数有问题 或者 写接口的index.js有问题,
然后问ai,
如果正常打印,但页面不显示数据,就是字段了,
比如绿色的框是要渲染到页面的,如果不渲染,就说明weatherData数组中可能没有后面的字段,这时候就看一下apifox返回的数据结构,把字段对应。
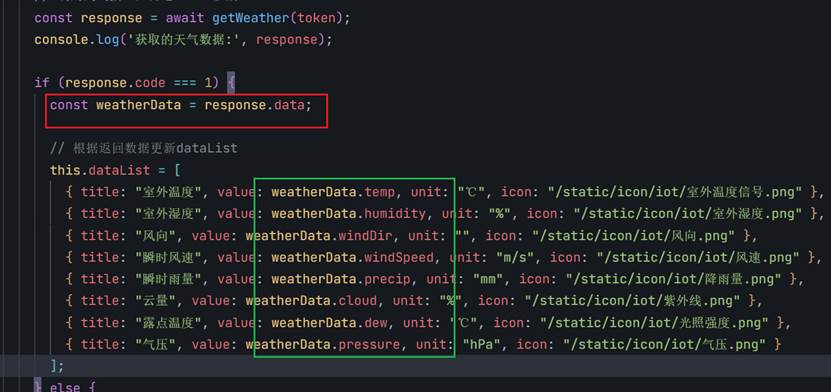
就是如果weatherData.temp不显示,就检查weatherData,如果weatherData不显示,就检查谁给他赋值的。这里就打印一下红框的response.data
如果response.data打印为undefined,那就再找上一层的response,检查它的数据结构

















 4535
4535

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









