



Python入门
• Python是一种简单易记的编程语言。
• Python是开源的,可以自由使用。
• 本书中将使用Python 3.x实现深度学习。
• 本书中将使用NumPy和Matplotlib这两种外部库。
• Python有“解释器”和“脚本文件”两种运行模式。
• Python能够将一系列处理集成为函数或类等模块。
• NumPy中有很多用于操作多维数组的便捷方法。
感知机
• 感知机是具有输入和输出的算法。给定一个输入后,将输出一个既 定的值。
• 感知机将权重和偏置设定为参数。
• 使用感知机可以表示与门和或门等逻辑电路。
• 异或门无法通过单层感知机来表示。
• 使用2层感知机可以表示异或门。
• 单层感知机只能表示线性空间,而多层感知机可以表示非线性空间。
• 多层感知机(在理论上)可以表示计算机。
神经网络
1.先看一下感知机的示意图

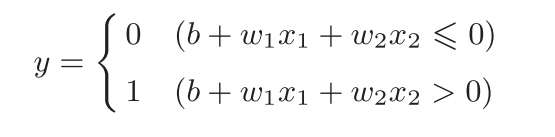
2.现在将上式简化为以下两式:
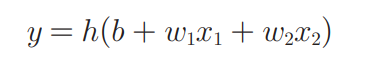
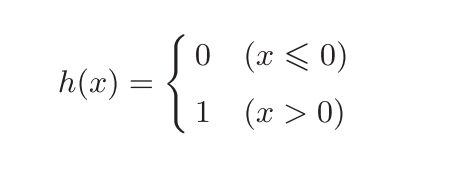
3.激活函数
刚才登场的h(x)函数会将输入信号的总和转换为输出信号,这种函数 一般称为激活函数(activation function)。如“激活”一词所示,激活函数的作用在于决定如何来激活输入信号的总和
4.进一步改写式子
先计算输入信号的加权总和,然后用激活函数转换这一总和。

示意图变为: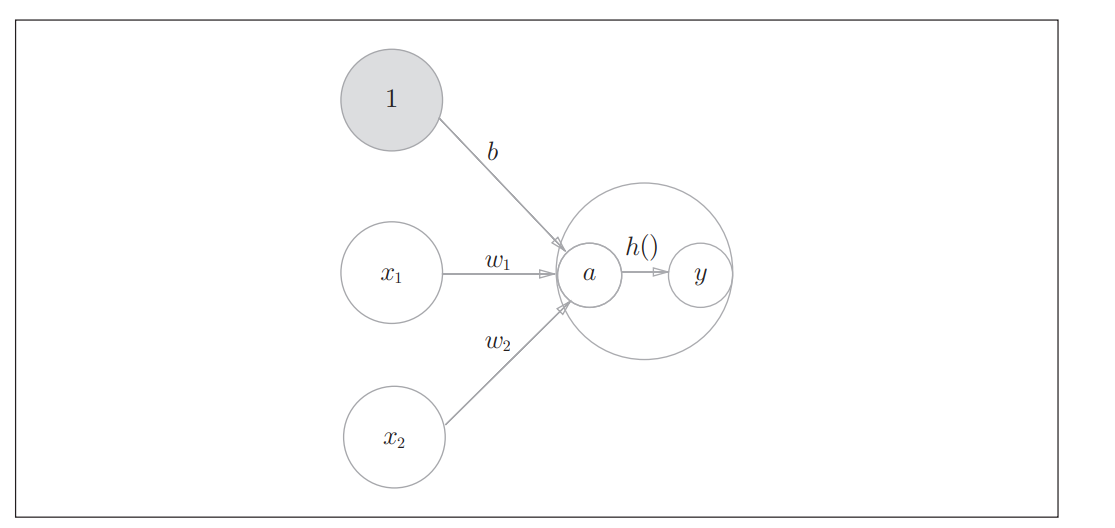
如图所示,表示神经元的○中明确显示了激活函数的计算过程,即信号的加权总和为节点a,然后节点a被激活函数h()转换成节点y。本书中,“神经元”和“节点”两个术语的含义相同。这里,我们称a和y为“节点”,其实它和之前所说的“神经元”含义相同。

下面着重介绍激活函数:
激活函数是连接感知机和神经网络的桥梁。
式(3.3)表示的激活函数以阈值为界,一旦输入超过阈值,就切换输出。 这样的函数称为“阶跃函数”。因此,可以说感知机中使用了阶跃函数作为 激活函数。也就是说,在激活函数的众多候选函数中,感知机使用了阶跃函数。 那么,如果感知机使用其他函数作为激活函数的话会怎么样呢?实际上,如 果将激活函数从阶跃函数换成其他函数,就可以进入神经网络的世界了。下 面我们就来介绍一下神经网络使用的激活函数。
sigmoid函数
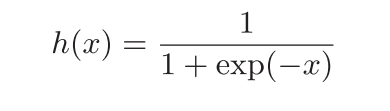
exp(-x)表示e的负x次方
阶跃函数的实现
代码
sigmoid函数的实现
代码
神经网络的激活函数必须使用非线性函数。换句话说,激活函数不能使 用线性函数。为什么不能使用线性函数呢?因为使用线性函数的话,加深神 经网络的层数就没有意义了。
ReLU(Rectified Linear Unit)函数
ReLU函数在输入大于0时,直接输出该值;在输入小于等于0时,输 出0
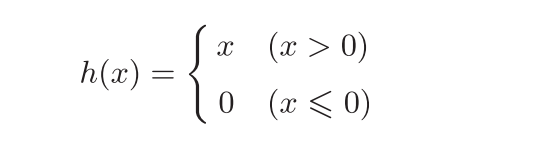
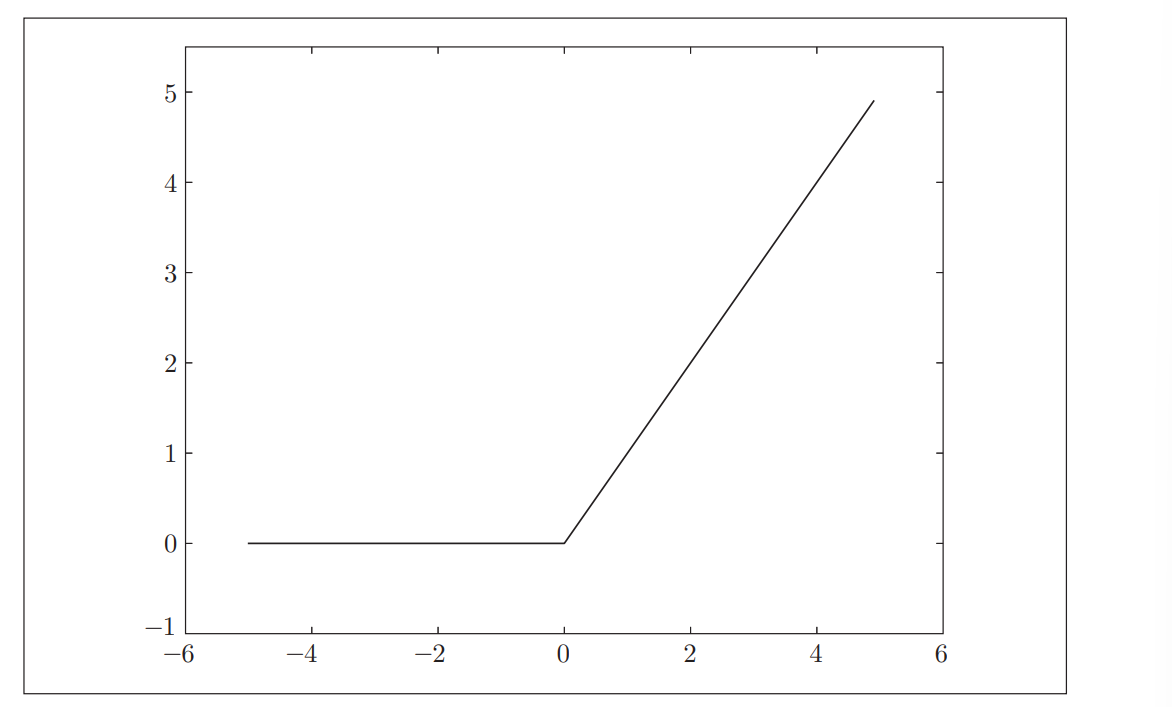
下面画出神经网络图示:

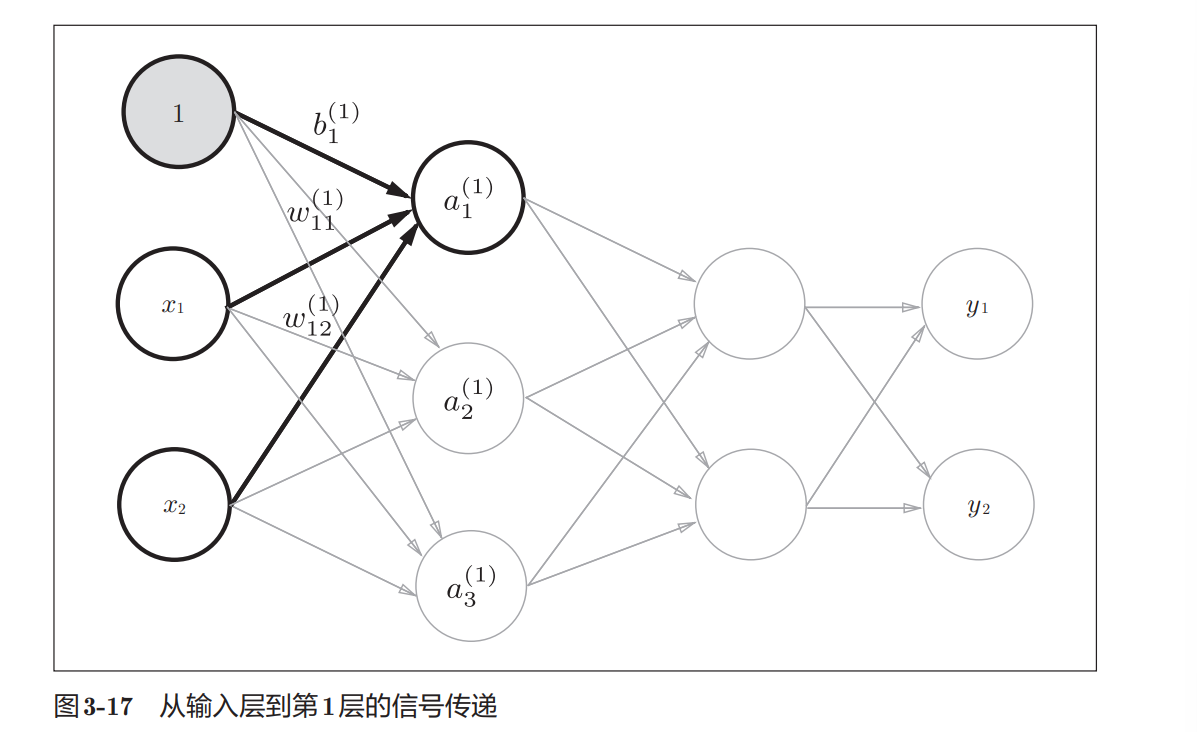
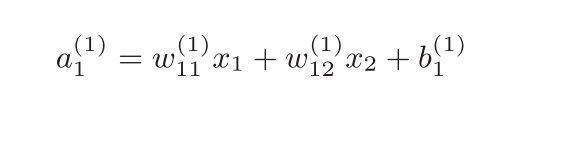

代码:
这里定义了init_network()和forward()函数。init_network()函数会进 行权重和偏置的初始化,并将它们保存在字典变量network中。这个字典变 量network中保存了每一层所需的参数(权重和偏置)。forward()函数中则封 装了将输入信号转换为输出信号的处理过程。
这里出现了forward(前向)一词,它表示的是从输入到输出方向 的传递处理。后面在进行神经网络的训练时,我们将介绍后向(backward, 从输出到输入方向)的处理
机器学习的问题大致可以分为分类问题和回归问题。分类问题是数 据属于哪一个类别的问题。比如,区分图像中的人是男性还是女性 的问题就是分类问题。而回归问题是根据某个输入预测一个(连续的) 数值的问题。比如,根据一个人的图像预测这个人的体重的问题就 是回归问题(类似“57.4kg”这样的预测)。神经网络可以用在分类问题和回归问题上,不过需要根据情况改变输出 层的激活函数。一般而言,回归问题用恒等函数,分类问题用softmax函数。
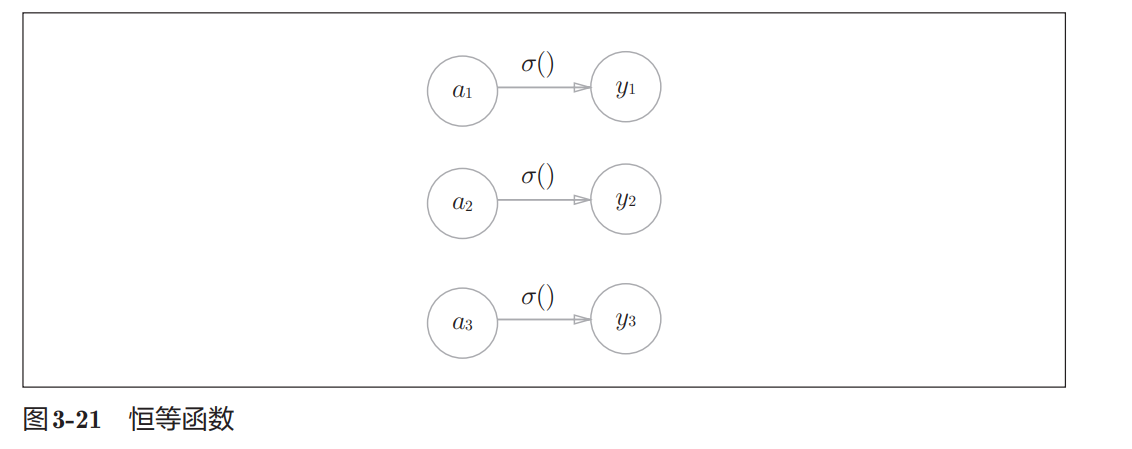
恒等函数会将输入按原样输出,对于输入的信息,不加以任何改动地直 接输出。因此,在输出层使用恒等函数时,输入信号会原封不动地被输出。 另外,将恒等函数的处理过程用之前的神经网络图来表示的话,则如图3-21 所示。和前面介绍的隐藏层的激活函数一样,恒等函数进行的转换处理可以 用一根箭头来表示。
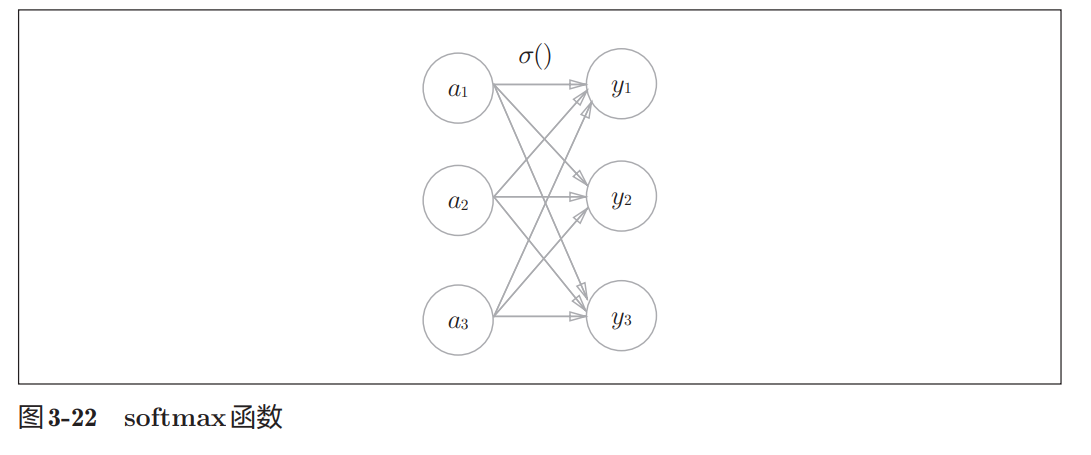
分类问题中使用的softmax函数可以用下面的式(3.10)表示。

式(3.10)表示 假设输出层共有n个神经元,计算第k个神经元的输出yk。如式(3.10)所示, softmax函数的分子是输入信号ak的指数函数,分母是所有输入信号的指数 函数的和
实现 softmax函数时的注意事项
上面的softmax函数的实现虽然正确描述了式(3.10),但在计算机的运算 上有一定的缺陷。这个缺陷就是溢出问题。softmax函数的实现中要进行指 数函数的运算,但是此时指数函数的值很容易变得非常大。比如,e 10的值 会超过20000,e 100会变成一个后面有40多个0的超大值,e 1000的结果会返回 一个表示无穷大的inf。如果在这些超大值之间进行除法运算,结果会出现“不 确定”的情况。
softmax函数的输出是0.0到1.0之间的实数。并且,softmax 函数的输出值的总和是1。输出总和为1是softmax函数的一个重要性质。正 因为有了这个性质,我们才可以把softmax函数的输出解释为“概率”。
一般而言,神经网络只把输出值最大的神经元所对应的类别作为识别结果。 并且,即便使用softmax函数,输出值最大的神经元的位置也不会变。因此, 神经网络在进行分类时,输出层的softmax函数可以省略。在实际的问题中, 由于指数函数的运算需要一定的计算机运算量,因此输出层的softmax函数 一般会被省略。
求解机器学习问题的步骤可以分为“学习”A 和“推理”两个阶段。首 先,在学习阶段进行模型的学习B,然后,在推理阶段,用学到的 模型对未知的数据进行推理(分类)。如前所述,推理阶段一般会省 略输出层的 softmax函数。在输出层使用 softmax函数是因为它和 神经网络的学习有关系(详细内容请参考下一章)。
输出层的神经元数量
输出层的神经元数量需要根据待解决的问题来决定。对于分类问题,输 出层的神经元数量一般设定为类别的数量。比如,对于某个输入图像,预测 是图中的数字0到9中的哪一个的问题(10类别分类问题),可以像图3-23这样, 将输出层的神经元设定为10个。
MNIST数据集:
训练集60000条,测试集10000条
首先把28*28的照片,写成向量,1*784。6万条的训练集为60000*784,测试集10000*784
然后把标签转为独热编码,每个标签是1*10, 6万条就是60000*10
神经网络的学习
这里所说的“学习”是指从训练数据中 自动获取最优权重参数的过程。本章中,为了使神经网络能进行学习,将导 入损失函数这一指标。而学习的目的就是以该损失函数为基准,找出能使它 的值达到最小的权重参数。为了找出尽可能小的损失函数的值,本章我们将 介绍利用了函数斜率的梯度法。
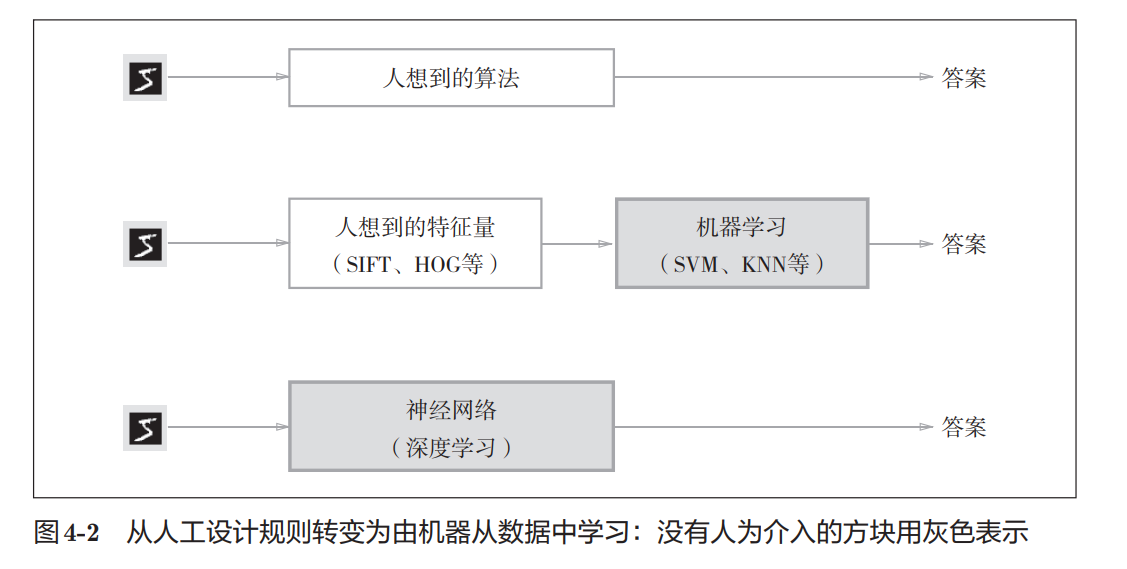
深 度 学 习 有 时 也 称 为 端 到 端 机 器 学 习(end-to-end machine learning)。这里所说的端到端是指从一端到另一端的意思,也就是 从原始数据(输入)中获得目标结果(输出)的意思。
神经网络的优点是对所有的问题都可以用同样的流程来解决。比如,不 管要求解的问题是识别5,还是识别狗,抑或是识别人脸,神经网络都是通 过不断地学习所提供的数据,尝试发现待求解的问题的模式。也就是说,与 待处理的问题无关,神经网络可以将数据直接作为原始数据,进行“端对端” 的学习。
介绍神经网络之前,先介绍一下机器学习中的训练数据和测试数据。首先,使用训练数据进行学习,寻找最优的参数;然后,使用测试 数据评价训练得到的模型的实际能力。为什么需要将数据分为训练数据和测 试数据呢?因为我们追求的是模型的泛化能力。为了正确评价模型的泛化能 力,就必须划分训练数据和测试数据。另外,训练数据也可以称为监督数据。
泛化能力是指处理未被观察过的数据(不包含在训练数据中的数据)的 能力。获得泛化能力是机器学习的最终目标。
损失函数
神经网络的学习中 所用的指标称为损失函数(loss function)。这个损失函数可以使用任意函数, 但一般用均方误差和交叉熵误差等。
损失函数是表示神经网络性能的“恶劣程度”的指标,即当前的 神经网络对监督数据在多大程度上不拟合,在多大程度上不一致
可以用作损失函数的函数有很多,其中最有名的是
均方误差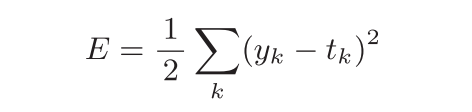
yk是表示神经网络的输出,tk表示监督数据,k表示数据的维数。
交叉熵误差

另外,MNIST数据集的训练数据有60000个,如果以全部数据为对象 求损失函数的和,则计算过程需要花费较长的时间。再者,如果遇到大数据, 数据量会有几百万、几千万之多,这种情况下以全部数据为对象计算损失函 数是不现实的。因此,我们从全部数据中选出一部分,作为全部数据的“近 似”。神经网络的学习也是从训练数据中选出一批数据(称为mini-batch,小 批量),然后对每个mini-batch进行学习。比如,从60000个训练数据中随机 选择100笔,再用这100笔数据进行学习。这种学习方式称为mini-batch学习。
根据目的是寻找最小值还是最大值,梯度法的叫法有所不同。严格地讲, 寻找最小值的梯度法称为梯度下降法(gradient descent method), 寻找最大值的梯度法称为梯度上升法(gradient ascent method)。但 是通过反转损失函数的符号,求最小值的问题和求最大值的问题会 变成相同的问题,因此“下降”还是“上升”的差异本质上并不重要。 一般来说,神经网络(深度学习)中,梯度法主要是指梯度下降法。
像学习率这样的参数称为超参数。这是一种和神经网络的参数(权重 和偏置)性质不同的参数。相对于神经网络的权重参数是通过训练 数据和学习算法自动获得的,学习率这样的超参数则是人工设定的。 一般来说,超参数需要尝试多个值,以便找到一种可以使学习顺利 进行的设定。

















 2043
2043

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









