






0. 概要
该研究针对哈萨克语低资源的特点,通过自建多样化连续语音数据库,结合传统模型与深度学习模型的优势,构建了首个(或早期)哈萨克语连续语音识别系统,取得 30.01% 的 WER 基线结果,为该语言的语音识别技术发展奠定了数据和模型基础。
-
研究背景:哈萨克语的低资源属性
- 低资源语言定义:指标注数据稀缺、相关技术工具不完善的语言,这类语言的语音识别系统构建核心难点在于缺乏足量的高质量语音 - 文本对齐数据。
-
核心基础:哈萨克语语音数据库构建
- 对于低资源语言,自建数据库是解决 “数据匮乏” 问题的关键前提,直接决定模型训练的有效性。
-
模型选择:传统模型 + 深度神经网络
1. 引言
主流语言的 ASR 技术成熟依赖充足的标准化资源,但哈萨克语作为低资源黏着语,既面临 “数据短缺” 的共性问题,又要应对 “形态学复杂” 的个性挑战;当前的资源建设工作虽有突破,但距离支撑高性能 ASR 系统仍有较大差距。
语音识别技术的普适价值与区域发展失衡
- 技术价值:语音识别重构信息获取方式、提升任务效率、减轻人力成本,近年应用增长迅猛。
- 应用现状:在英语、汉语等资源丰富的主流语言中已广泛落地,核心依托是充足的语言资源(标注数据、工具链等)。
- 区域短板:中亚地区因语言资源短缺 / 不可得,该技术普及率远低于主流语言区域。
现代 ASR 系统的核心基础:声学语料库
- 统计建模(如 GMM-HMM、DNN-HMM)是现代 ASR 的核心方法,而声学语料库(带文本转录的语音数据)是训练声学模型的 “原材料”,数据规模和质量直接决定模型性能。
哈萨克语语音识别的核心难点(低资源黏着语的典型困境)
哈萨克语作为低资源语言,面临的问题远超单纯的数据短缺,而是语言特性 + 资源短板的复合型挑战:
-
黏着语的形态学结构难题
- 黏着语定义:通过添加后缀 / 词尾构成新词的语言类型(所有突厥语族语言均属此类)。比如一个核心词可叠加多个后缀,衍生出不同语义的词汇(如名词变格、动词变位)。
- 对 ASR 的影响:黏着语的词汇派生能力极强,会导致词汇表规模爆炸—— 同样的语义表达,在英语中可能是一个短语,在哈萨克语中可能是一个长复合词,大幅增加语言模型的训练难度。
-
声学资源的三重短缺
- 缺乏公开可用的大规模声学数据:训练高性能 ASR 系统通常需要数百甚至数千小时的标注语音,而哈萨克语相关资源严重不足;
- 缺乏统一的发音标准:没有公认的音素、双音素、三音素标注规范,导致不同研究团队的数据集无法互通,重复造轮子;
- 缺乏语音学丰富的数据库:无法像 TIMIT 那样支撑精细化的声学特征研究,模型优化缺乏基础数据支撑。
正在推进大型哈萨克语语料库建设项目
2. 语音识别系统
Kaldi
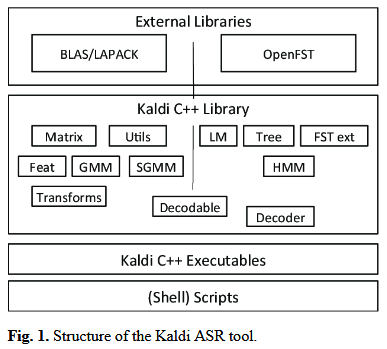
- Kaldi 是 C++ 编写的开源语音识别工具,兼具高性能(速度快)和全功能(覆盖特征、模型、自适应全流程);
- 核心依赖库:
- OpenFst:提供有限状态变换器(FST)基础设施,是语音识别解码环节的核心(用于构建词典、语言模型的状态转移图);
- BLAS/LAPACK:线性代数库,支撑声学模型训练中的矩阵运算(如 DNN/GMM 的参数优化)。
- 核心依赖库:
- 其高度定制化的 HMM 拓扑和决策树设计,适配哈萨克语这类低资源语言的连续语音识别开发;
- 完善的文档和成熟的依赖库(OpenFst/BLAS/LAPACK)是其成为选型最优解的关键。
3. 语音及语言处理
DNN-HMM 混合系统的本质是 用 DNN 替代 GMM 来计算 HMM 的状态发射概率,而基于 Kaldi 的训练流程遵循 “从简单到复杂、从基础到优化” 的原则:先通过 GMM-HMM 完成状态对齐,再用 DNN 学习更精准的状态后验概率,最终实现比传统 GMM-HMM 更优的识别性能。
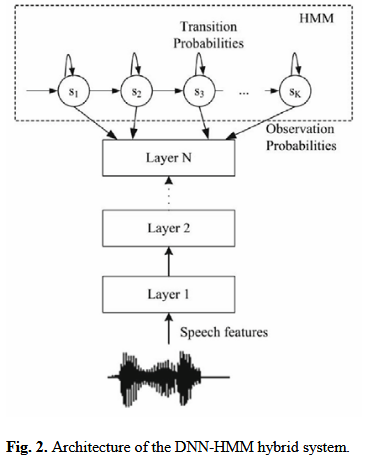
语言模型(Language Model, LM)的核心作用与跨语言设计差异
- 语言模型的核心任务是计算单词序列的出现概率,公式可表示为 P(w1,w2,...,wn)P(w_1,w_2,...,w_n)P(w1,w2,...,wn),作用是在语音识别解码阶段,从多个可能的候选词序列中挑选出 “最符合语言习惯” 的结果。
- 语言特性决定模型复杂度
- 孤立语(如英语):单词形态变化少,直接使用统计模型(如 N-gram) 即可取得不错效果。N-gram 基于大量文本语料统计相邻 n 个单词的共现概率,实现简单且高效。
- 屈折语(如俄语):单词存在丰富的词形变化(如名词变格、动词变位),同一个词根会衍生出数十种不同形式。仅用统计模型的问题在于:
- 语料中难以覆盖所有词形,导致低频词形的概率估计不准;
- 忽略了 “词根 - 词缀” 的语法规则,模型泛化能力差。
- 屈折语的解决方案:混合语言模型
- 纯统计模型的痛点:需要海量标注语料才能准确统计词序列概率,这对很多屈折语来说成本极高。
- 混合模型的优势:融合 统计信息(N-gram) 和 语言规则信息(如形态学、句法规则),既利用语料的统计规律,又通过语法规则补全低频词形的概率,大幅提升模型在屈折语上的性能。
- 语言模型的作用层级是单词层面,负责约束 “哪些词序列是合理的”,与负责 “音素 - 单词” 映射的声学模型(AM)配合,共同完成语音识别。
词典的音素划分规则与哈萨克语音素体系
词典的音素编码功能
- 核心是:词典需要将语言模型中的每一个单词,拆解为最小的语音单元(音素)序列。例如哈萨克语单词
ұстаушы被拆解为音素序列u s t a u sh y,这是语音识别中 “声学特征→音素→单词” 映射的关键桥梁。
音素的定义
- 最小语音单元:不能再拆分为更小的、有区别意义的语音片段;
- 辨义功能:本身无词汇 / 语法含义,但替换音素会改变单词意义。例如英语中 /p/ 和 /b/ 替换,会让 park 变成 bark。
哈萨克语的音素分类
- 元音音素:
а, ә, о, ө, е, ы, і, ү, ұ(共 9 个,包含独特的前后元音区分,是阿尔泰语系的典型特征); - 辅音音素:
б, г, ғ, д, ж, з, й, к, қ, л, м, н, ң, п, р, с, т, х, ш, у(共 20 个,包含浊辅音、清辅音和独特的腭化辅音)。
音素变体的处理规则
- 音素变体:同一音素在不同语境下的发音差异,例如单词
kitap中的/a/实际读作/ә/,hatshy中的/h/读作/ch/; - 处理原则:这些变体不具备辨义功能,因此在语音识别的音素标注和建模中,统一归为同一个音素,无需单独建模(避免模型复杂度不必要的增加)。
数据
声学模型(Acoustic Model, AM)的核心设计
声学模型的本质功能功能
声学模型是实现连续语音识别的核心组件,其核心任务是:
- 定义声学建模单元(文中选择音素作为基本单元);
- 将输入的语音特征向量序列(如 MFCC、fbank)映射为音素序列,完成 “声音→语音单元” 的转换。
音素的三状态建模方案
语音识别中经典的音素状态建模方法(与 HMM 结合):
- 每个音素被拆分为 3 个状态:起始态(音素发音的起始阶段)、中间态(音素发音的稳定阶段)、结束态(音素发音的收尾阶段);
- 状态转移约束:只能从 “起始态→中间态→结束态” 单向转移,禁止逆向转移(符合语音发音的时序性);
- 状态时长灵活性:允许单个状态持续多帧特征(对应发音的延长,比如长元音的稳定阶段),保证模型对不同语速的适应性。
大词汇量系统的建模策略
大词汇量语音识别系统不直接对单词建模(单词数量太多,数据稀疏性问题严重),而是对音素建模—— 因为音素数量有限(如哈萨克语只有 29 个音素),能通过音素的组合覆盖所有单词,大幅降低模型训练难度。
语音数据采集与数据集划分
采集细节
划分数据集
词典数据库的构建流程
词典是连接声学模型(音素) 和语言模型(单词) 的关键桥梁,构建步骤如下:
- 文本预处理:将所有录制的句子文本合并为一个文件,删除重复单词,并按字母顺序排序;
- 音素转写:将每个单词音译为对应的音素序列(音译规则见表 1);
- 词典生成:最终词典由 “单词 - 音素序列” 的一一对应关系构成(示例见图 3),无重复词条。

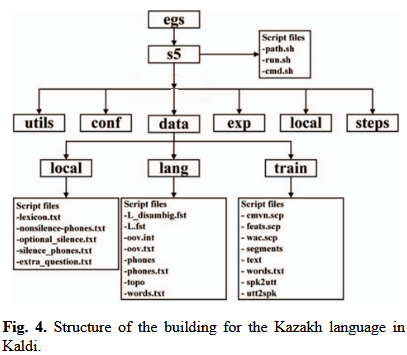
Kaldi 搭建哈萨克语语音识别系统的数据层 + 语言层核心配置
- data文件夹通过结构化文件管理语音数据的元信息(音频 - 文本、音频 - 发音人映射),辅助文件自动生成降低手动成本;
- data/lang文件夹基于语言模型构建,核心是lexicon.txt词典(2 万单词 + 音素转写)和音素分类文件;
- 语言模型采用 trigram+Kneser-Ney 平滑,适配哈萨克语的语料特点,保证单词序列概率估计的准确性。
5. 实验
词识别率(WRR)和词错误率(WER)
- 词识别率(WRR, Word Recognition Rate):正确识别的单词数量占总单词数的百分比,公式为
WRR(%)=正确识别单词数总单词数×100%WRR(\%)=\frac{\text{正确识别单词数}}{\text{总单词数}}\times100\%WRR(%)=总单词数正确识别单词数×100%
- 词错误率(WER, Word Error Rate):错误识别的单词数量占总单词数的百分比,是目前衡量 ASR 系统性能的主流指标
WER 成为主流指标的原因
随着语音技术的发展,ASR 系统的识别精度越来越高,WRR 会无限趋近于 100%,此时 WRR 的微小提升很难体现模型的优化效果;而 WER 趋近于 0,其数值的下降(如从 5% 降到 3%)能更直观、更显著地反映模型性能的进步。同时,WER 支持绝对数值对比(单系统性能)和相对数值对比(多系统性能横向比较),适用性更强。
WER 的核心原理和计算公式
计算的核心步骤:动态规划 + 莱文斯坦距离(Levenshtein Distance)
- 对比对象:识别结果文本(模型输出)和参考文本(真实发音内容);
- 核心算法:动态规划—— 用于高效计算两个文本序列的最优对齐;
- 距离定义:莱文斯坦距离—— 将识别文本转换为参考文本所需的最少编辑操作次数,编辑操作仅包含 3 种:
- 替换(S, Substitution):识别文本中的单词被错误替换为另一个单词(如把 “apple” 识别成 “apply”);
- 删除(D, Deletion):参考文本中的单词在识别结果中缺失(如漏识别 “the”);
- 插入(I, Insertion):识别结果中出现了参考文本没有的单词(如多识别出 “a”)。
WER 计算公式为:
WER(%)=S+D+IN×100%WER(\%)=\frac{S+D+I}{N}\times100\%WER(%)=NS+D+I×100%
-
符号说明:
- S:替换操作的次数;
- D:删除操作的次数;
- I:插入操作的次数;
- N:参考文本的总单词数(注意不是识别文本的单词数,这是计算的关键前提)。
-
示例:参考文本为 “
this is a test”(4 个单词),识别文本为 “this is test”,则 D=1D=1D=1,S=0S=0S=0,I=0I=0I=0,WER=14×100%=25%WER=\frac{1}{4}\times100\%=25\%WER=41×100%=25%。
哈萨克语语音识别系统的实验流程与核心结果
实验整体流程:从基础模型到优化模型的 WER 迭代
实验遵循 “单音子模型→三音子模型→DNN 混合模型” 的递进优化思路
DNN 的训练细节(基于 CUDA GPU 加速)
DNN 训练分为预训练(RBM)+ 微调(Backpropagation) 两阶段,符合深度神经网络的经典训练策略(避免随机初始化导致的梯度消失):
第一阶段:RBM 预训练(无监督初始化)
- 核心算法:对比散度(Contrastive Divergence, CD),结合马尔可夫链的蒙特卡洛 1 步采样(简化计算,提升训练效率);
- 输入特征:与 GMM-HMM 一致(MFCC + 能量 + 一阶 / 二阶差分特征),保证特征体系统一;
- RBM 单元类型:
- 第一层 RBM:高斯 - 伯努利单元(Gauss-Bernoulli),适配连续值的声学特征;
- 其他 RBM:伯努利 - 伯努利单元(Bernoulli-Bernoulli),适配离散化的隐藏层输出;
- 训练参数:
- 初始学习率:第一层 0.01,其他层 0.4(分层调整学习率,适配不同单元特性);
- 迭代次数:3 次;
- 隐藏层数量:最多 6 层;
- 每层单元数:最多 2048 个;
- 训练方式:无监控训练(纯无监督,仅学习特征分布)。
2. 第二阶段:DNN 微调(有监督优化)
- 数据划分:90% 训练数据用于参数更新,10% 用于验证(避免过拟合);
- 初始化方式:将预训练的 RBM 折叠为 DNN 的初始权重(比随机初始化收敛更快、效果更好);
- 损失函数:交叉熵(Cross-Entropy),目标是将单帧特征分类到三音子状态;
- 优化器:小批量随机梯度下降(Mini-batch SGD)+ 误差反向传播(Backpropagation);
- 防过拟合策略:
- 交叉验证集监控目标函数;
- 早停准则(Early Stop):当验证集性能不再提升时停止训练,避免模型过拟合。
关键结果与核心结论
- 模型优化效果:从单音子模型(WER≈62%)到最优 DNN 模型(WER=31.78%),WER 下降约 49%,优化效果显著;
- 关键优化手段:
- GMM-HMM 阶段:SAT(说话人自适应)是降 WER 最明显的手段(测试集降 4.14%);
- DNN 阶段:RBM 预训练 + 早停策略保证了模型的泛化能力,6 层隐藏层是最优结构;
- 实验细节:所有 DNN 训练基于单块 CUDA GPU 完成,Modified Karel 配置是 Kaldi 中针对 DNN-HMM 的经典配置,保证了实验的可复现性。


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









