




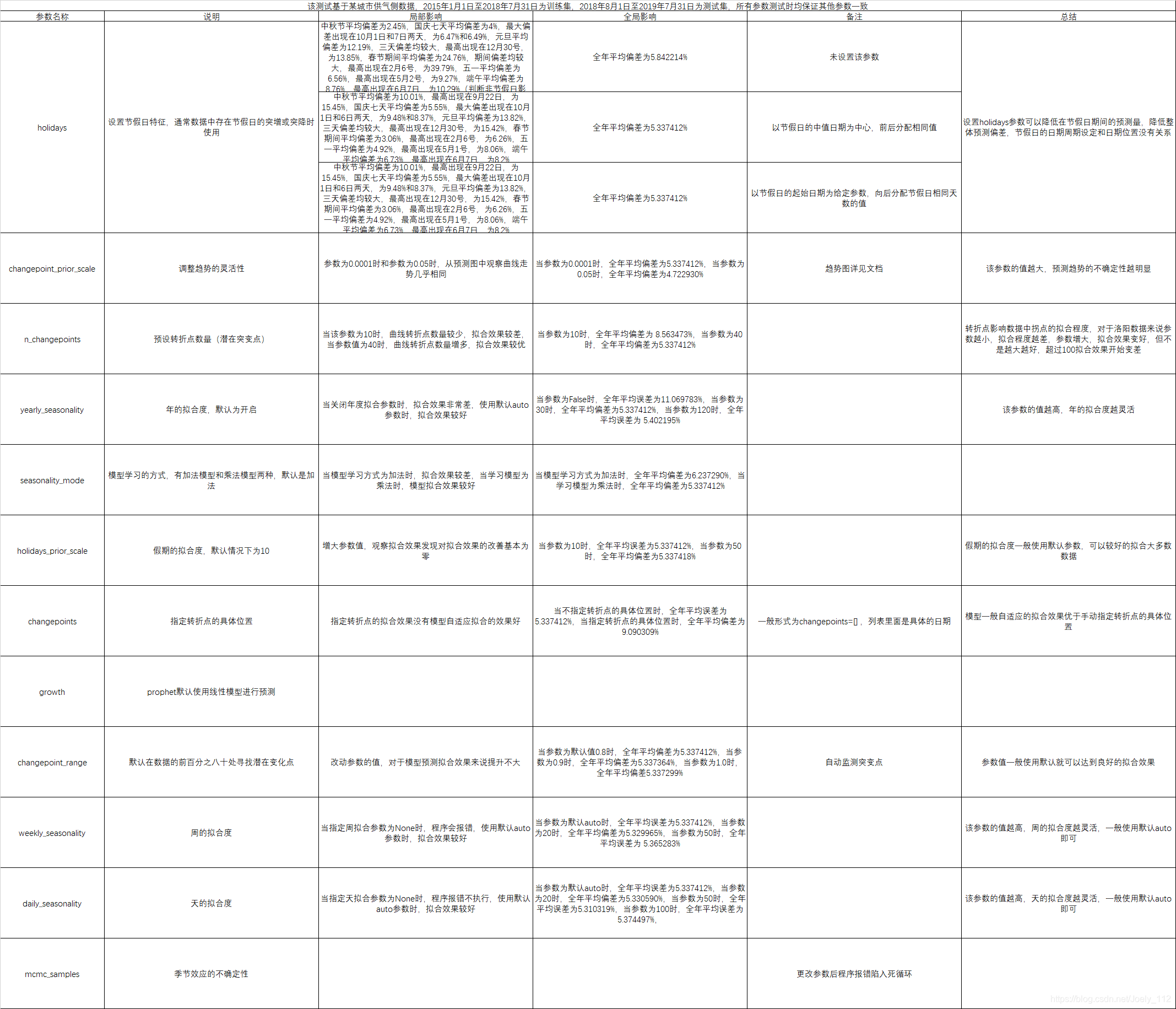
Prophet算法原理及实现详见https://blog.youkuaiyun.com/weixin_38989668/article/details/82845120,本文仅讨论Prophet的调参,如有错误请不吝指正。
Prophet参数调节说明
最新推荐文章于 2025-11-01 16:31:17 发布
 本文专注于探讨Facebook的Prophet预测算法的参数调整技巧,旨在帮助读者深入理解如何优化Prophet模型,以提升时间序列预测的准确性。文章指出,虽然详细的算法原理及实现可参考特定资源,但关于如何有效调参的内容相对较少。因此,本文将填补这一空白,提供宝贵的实践指导。
本文专注于探讨Facebook的Prophet预测算法的参数调整技巧,旨在帮助读者深入理解如何优化Prophet模型,以提升时间序列预测的准确性。文章指出,虽然详细的算法原理及实现可参考特定资源,但关于如何有效调参的内容相对较少。因此,本文将填补这一空白,提供宝贵的实践指导。
部署运行你感兴趣的模型镜像
您可能感兴趣的与本文相关的镜像

ACE-Step
音乐合成
ACE-Step
ACE-Step是由中国团队阶跃星辰(StepFun)与ACE Studio联手打造的开源音乐生成模型。 它拥有3.5B参数量,支持快速高质量生成、强可控性和易于拓展的特点。 最厉害的是,它可以生成多种语言的歌曲,包括但不限于中文、英文、日文等19种语言

















 2646
2646

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









