




 本文探讨了混合搜索的概念,它结合了关键字、文本信息检索和基于 AI 的向量搜索。混合搜索在多模态数据环境中展现出优势,通过将 BM25、SBERT 和 CLIP 模型融合,改善了搜索结果的准确性。实验显示,混合搜索在文本和图像数据上的表现优于单一技术,尤其是经过微调后,性能显著提升。混合搜索的高效性在于其能综合处理不同类型的输入数据,提供更全面的匹配结果。
本文探讨了混合搜索的概念,它结合了关键字、文本信息检索和基于 AI 的向量搜索。混合搜索在多模态数据环境中展现出优势,通过将 BM25、SBERT 和 CLIP 模型融合,改善了搜索结果的准确性。实验显示,混合搜索在文本和图像数据上的表现优于单一技术,尤其是经过微调后,性能显著提升。混合搜索的高效性在于其能综合处理不同类型的输入数据,提供更全面的匹配结果。

二十年前,“混合”一词仅在植物学和化学领域使用。如今,“混合”这个概念在搜索领域一片繁荣,许多搜索系统都在推出基于 AI 技术的混合搜索方案。但是,“混合搜索”是真的具有应用价值,还只是流行的一阵风呢?
许多搜索系统都在推出混合搜索功能,混合搜索将传统搜索中的关键字、文本信息检索技术和基于 AI 的“向量”或“神经”搜索结合在一起。“混合搜索”是否只是一个流行词呢?毕竟基于文本的搜索是一项应用广泛的技术,以至于用户早已习惯了它的特点,甚至是局限性。将文本搜索与新的 AI 技术结合真的能为搜索系统锦上添花吗?
答案显而易见:这取决于实际情况。
现在的数据存储是多媒体和多模态的,文本、图像、视频和音频常常存储在同一数据库和同一计算机上。这意味着,如果你想在五金商店的网站上搜索螺丝刀的图片,你不能只查询“螺丝刀”这个词,就期望它能返回相应的结果。首先你得存储并索引文本或商品的标签。除非你明确地将数据库中所有螺丝刀的图片与“螺丝刀”这个标签或其他文本相关联,表明它是螺丝刀的图片,否则利用传统的搜索技术是无法返回搜索结果的。如果你没有明确的标签和文本,将最先进的 AI 技术添加到文本搜索中将不会有任何帮助。这样的话,那么将 AI 技术与传统搜索结合就没有意义了。
假设有一个拥有网购平台的大型五金商,售卖数十万种不同的商品。但是,他们没有员工制作详细的产品标签和描述或检查它们的准确性;没有商品图片,也没有时间拍摄好的图片。这样的话,对他们来说,最好的文本搜索系统也是一个的有缺陷的解决方案。最新的 AI 技术可以很好地解决这些局限性。深度学习和 神经搜索[1] 让创建强大的通用神经网络模型成为可能,并将搜索模型以一种通用的方式应用于不同类型的数据中——文本、图像、音频和视频。因此,即使没有文本标签,搜索“螺丝刀”也可以找到螺丝刀的图片!
但是这些最新的搜索技术,返回的结果通常缺乏可解释性。客户可能希望输入查询“十字螺丝刀”,实际返回“开槽和十字螺丝刀,4 寸长”的产品。传统的搜索技术可以做到,但 AI 技术却很难达到这样的效果。
搜索模型
我们将基于三个特定的搜索模型搭建混合搜索引擎:BM25, SBERT 和 CLIP。
BM25 是最经典的基于文本的信息检索算法。BM25 最早发展于 1990 年代,现在已经被广泛使用。有关 BM25 的更多信息,请参阅 Robertson & Zaragoza(2009)[2],2000a[3] 和 2000b[4] ,或查看 维基百科上关于 BM25 的演示[5]。我们利用 Python 的 [rank_bm25] 包,实现了 BM25 排名算法。
SBERT[6] 是一个广泛用于文本信息检索的神经网络框架,我们使用的是 msmarco-distilbert-base-v3[7] 模型,因为它是为 MS-MARCO 段落排名任务训练的,与我们所做的排名任务差不多。
CLIP[8] 是一个连接的图像和描述文本的神经网络,它是在图像-文本对上训练的。CLIP 有许多应用,在本文我们中将使用它实现文本查询和图像匹配,并返回排名结果。我们使用的是 OpenAI 的 clip-vit-base-patch32[9] 模型,这也是使用最广泛的 CLIP 模型。
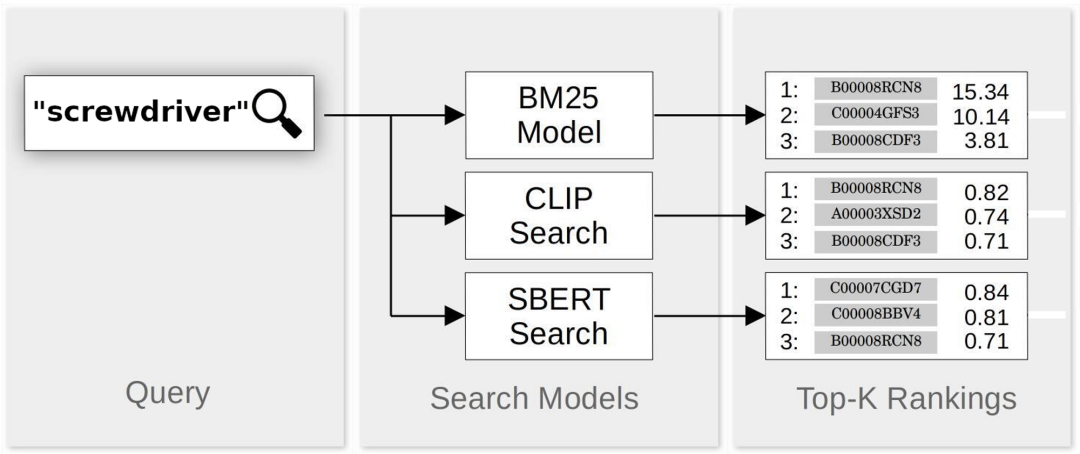
三种模型都是对文本查询的匹配结果进行评分和排名,然后返回一些排名靠前的结果(结果数由用户决定)。这三种模型都很容易集成。SBERT 和 CLIP 返回的分数都在 -1.0(查询最差匹配)到 1.0(查询最佳匹配)之间。BM25 分数最低为 0.0,但没有上限。为了方便比较,我们进行了以下处理:
去除 CLIP 或 SBERT 返回的小于 0.0 的结果,因为这些都是错误的匹配结果。
利用公式将 BM25 分数归一化到 0.0 到 1.0 之间:将 BM25 分数除以本身加上 10。
当匹配结果出现在一个或两个,但不是所有三个搜索方法的顶部结果中时,我们会为错过它的搜索方法分配一个内插分数。如果请求前 N 个匹配项,我们会为缺失的匹配项分配一个较小的非零值,该值是经验值。
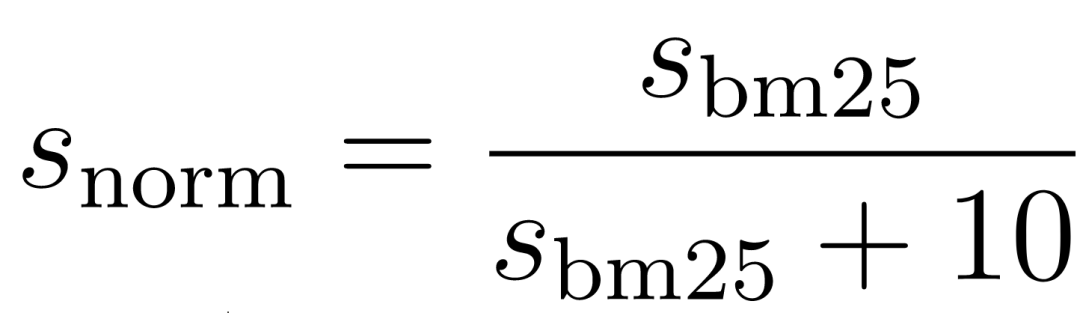
例如,假设我们搜索“螺丝刀”,并从 BM25、SBERT 和 CLIP 中获得了 20 个最佳匹配项。BM25 和 SBERT 搜索都在前 20 个匹配中识别出了产品“磁头螺丝刀 6 件套,3 个十字头和 3 个平头”,但 CLIP 的前 20 个匹配中没有该产品,因为图片是它的包装盒。这时,我们会找到 CLIP 前 20 个匹配结果中的最低分数,并将 这个分数分配给 “磁头螺丝刀 6 件套,3 个十字头和 3 个平头”这个产品。
混合搜索
我们构建了一个混合搜索方案,该方案结合了 BM25、SBERT 和 CLIP 的搜索结果。对于每个查询,我们都使用 3 种系统完成搜索,从每个系统中检索出 20 个最佳匹配,并按照上一节中的描述调整它们的分数。每个匹配项的分数都是 3 个搜索系统(SBERT、CLIP 和归一化的 BM25)的分数的加权和。下面是混合搜索方案工作的示意图:
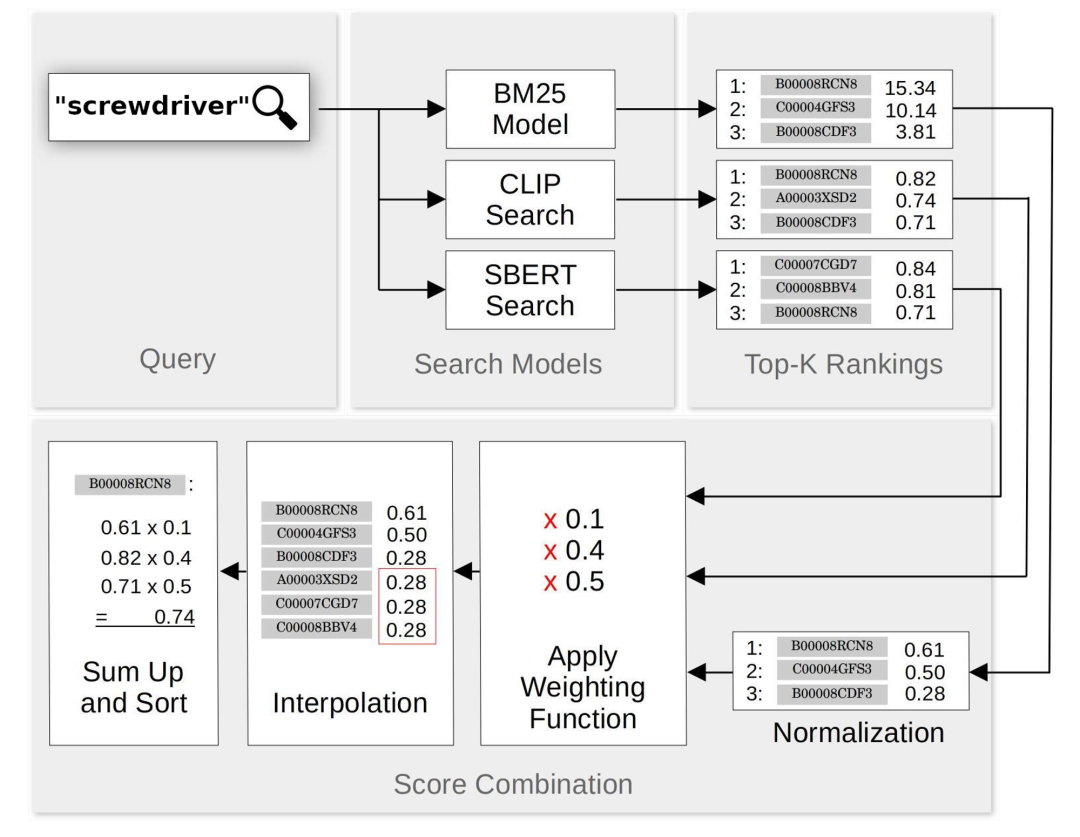
在实际应用中,我们发现以下的权重组合效果很好:
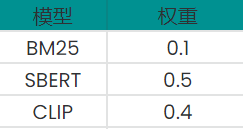 对于这个结果,我们可以直观地理解为,混合搜索系统在文本检索(SBERT 和 BM25)上的权重略大于 0.5 ,在文本到图像检索(CLIP)上的权重略小于 0.5 ,BM25 的 0.1 权重确保了对传统术语匹配的偏好,或者在神经模型无法产生好的匹配结果时作为补充。
对于这个结果,我们可以直观地理解为,混合搜索系统在文本检索(SBERT 和 BM25)上的权重略大于 0.5 ,在文本到图像检索(CLIP)上的权重略小于 0.5 ,BM25 的 0.1 权重确保了对传统术语匹配的偏好,或者在神经模型无法产生好的匹配结果时作为补充。
搜索方案比较
测试数据
理想情况下,我们应该拥有在线商家的产品数据库和查询日志。但是,出于商业和法律原因,公司(特别是虚构的公司)通常不会向研究人员提供产品数据库和查询日志。因此,我们只能使用替代方案。
我们使用了最接近的替代方案:XMarket dataset 数据集[10]。这些数据来自 18 个国家的亚马逊市场,包括亚马逊网站上的产品图像,以及产品名称、产品描述、类别和各种元数据。本文中,我们使用了 XMarket 数据集的一个子集:仅使用来自于美国亚马逊网站的电子产品类别中的条目,涉及 837 个类别,15934
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 291
291

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









