







原参考资料是一个网站和一个B站UP主讲解的过程,作为详细学习了解 请移步。
https://jonathanbgn.com/2021/10/30/hubert-visually-explained.htmlhttps://www.bilibili.com/video/BV1QLUiYEEAk/?spm_id_from=333.337.search-card.all.click&vd_source=53c9cead2a67816bbbf7bb89cdad073e下面记录个人的学习笔记。

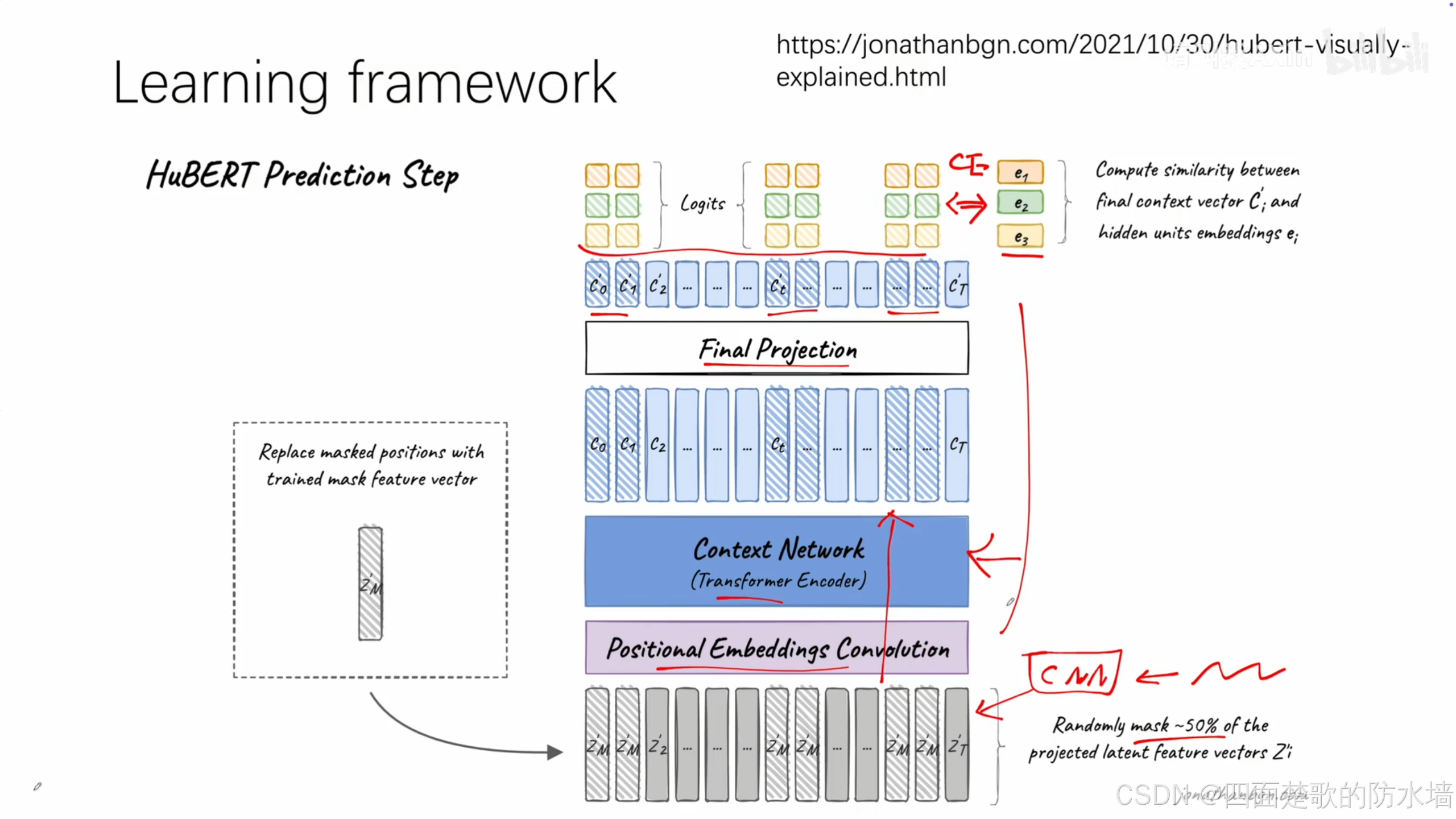
训练第一轮用MFCC,进行K-Means将每个聚类的中心点作为输出得到Hidden units embedding作为后续Back Propagation的Ground Truth;
训练从第二轮开始,从Context Network中间的某一层抽出一些Tokens作为K-Means聚类的输入(不再使用MFCC)
整体训练使用Cross-Entropy Loss来优化Transformer(Context Network),过程如下:
chinese-hubert-large:腾讯GameMate的预训练语音模型

















 765
765

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









