# 导入pandas库,用于数据处理和分析
import pandas as pd
# 读取CSV格式的房价数据集
data = pd.read_csv('house_price.csv')
# 打印数据集的前10条记录,用于初步了解数据结构和内容
print("数据集中的前10条记录:")
print(data.head(10))
print("") # 打印空行,使输出更清晰
# 导入matplotlib库的pyplot模块,用于数据可视化
from matplotlib import pyplot as plt
# 创建一个画布,设置大小为20x5英寸
fig = plt.figure(figsize=(20,5))
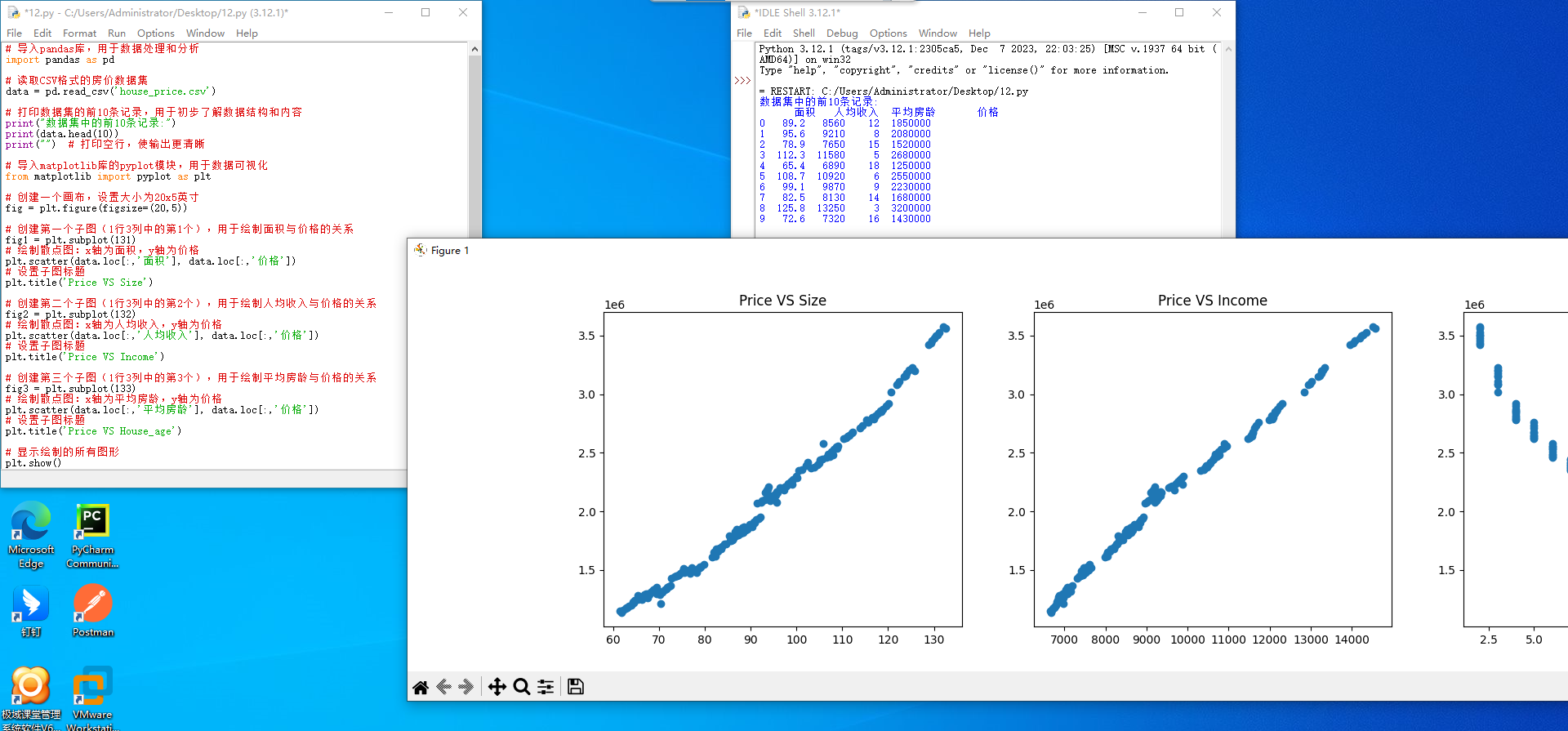
# 创建第一个子图(1行3列中的第1个),用于绘制面积与价格的关系
fig1 = plt.subplot(131)
# 绘制散点图:x轴为面积,y轴为价格
plt.scatter(data.loc[:,'面积'], data.loc[:,'价格'])
# 设置子图标题
plt.title('Price VS Size')
# 创建第二个子图(1行3列中的第2个),用于绘制人均收入与价格的关系
fig2 = plt.subplot(132)
# 绘制散点图:x轴为人均收入,y轴为价格
plt.scatter(data.loc[:,'人均收入'], data.loc[:,'价格'])
# 设置子图标题
plt.title('Price VS Income')
# 创建第三个子图(1行3列中的第3个),用于绘制平均房龄与价格的关系
fig3 = plt.subplot(133)
# 绘制散点图:x轴为平均房龄,y轴为价格
plt.scatter(data.loc[:,'平均房龄'], data.loc[:,'价格'])
# 设置子图标题
plt.title('Price VS House_age')
# 显示绘制的所有图形
plt.show()
# 导入numpy库,用于数值计算
import numpy as np
# 从数据中分离特征变量X(所有列除了价格)
X = data.drop(['价格'], axis=1)
# 目标变量y为价格列
y = data.loc[:, '价格']
# 将pandas数据框转换为numpy数组,以便后续模型处理
X = np.array(X)
y = np.array(y)
# 打印转换后的特征和目标变量的形状,确认数据维度是否正确
print(X.shape, y.shape)
# 将目标变量y重塑为二维数组(n行1列),符合sklearn模型的输入要求
y = y.reshape(-1, 1)
# 再次打印形状,确认重塑是否正确
print(X.shape, y.shape)
# 从sklearn库导入线性回归模型
from sklearn.linear_model import LinearRegression
# 创建多因子线性回归模型实例
model_multi = LinearRegression()
# 使用特征变量X和目标变量y训练模型
model_multi.fit(X, y)
# 定义一个测试样本:面积150,人均收入60000,平均房龄5
X_test = np.array([[150, 60000, 5]])
# 使用训练好的模型对测试样本进行房价预测
y_test_predict = model_multi.predict(X_test)
# 打印预测结果
print(y_test_predict)






















 1841
1841

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









