







了解什么是自然语言处理 (NLP) 并发现其实际应用,使用 Google BERT 处理文本数据集。
自然语言处理 (NLP) 通过使用机器学习来指示文本的结构和含义,从而改善了人类和计算机相互交流的方式。借助自然语言处理应用程序,组织可以通过分析文本和提取更有意义的信息来改善客户体验,从而提高工作效率并降低成本。
读研期间如何快速入门NLP?博士花17小时精讲Transformer+Huggingface+自然语言处理12大项目实战—HMM、贝叶斯算法、LSTM
什么是自然语言处理 (NLP)?
我们不能说我们经常思考我们语言的微妙之处。这是一种直观的行为,依靠单词、符号或图像等语义线索来传达信息和含义。有时说,在青春期学习一门语言更容易,因为它是一种可以灌输的可重复行为,就像走路一样。此外,语言不遵循严格的规则,并且有许多例外。
语言习得虽然对人类来说是自然的,但对计算机来说却极其复杂,因为它有很多非结构化数据,缺乏严格的规则,也没有具体的视角或上下文。然而,人类越来越依赖计算机系统来通信和执行任务。这就是机器学习和人工智能 (AI) 获得如此多关注和普及的原因。自然语言处理正在跟随 AI 的发展。尽管这两个术语可能会让人联想到未来机器人,但自然语言处理在日常生活中已经有简单的应用。
NLP 是 AI 的一个组成部分,专注于理解人类语言的书面和/或口语。为此,开发了特定的计算机程序;典型的计算机需要以非常精确、标记明确、结构化和明确的编程语言传达指令。不幸的是,自然的人类语言是不精确的、模棱两可的和令人困惑的。要使程序能够理解单词的含义,有必要使用能够分析含义和结构的算法,使单词易于理解,识别某些参考资料,然后生成语言。
自然语言处理 (NLP) 有哪些不同的技术?
NLP 算法执行各种句法和语义分析,以根据语法规则评估句子的含义。他们通过以下方式做到这一点:
- 分割单词和单词组或分析整个句子的语法。
- 将文本与可用数据库实时比较,以确定含义和上下文。
- 使用机器学习和深度学习技术来识别大量标记数据中的相关相关性。
常见的 NLP 技术包括:
- 命名实体识别 (NER):标识人员、地点、组织等的名称。
- 情绪分析:确定文本是传达积极、消极还是中立的情绪。
- 文本摘要:生成较长文本的简明摘要。
- 方面提取:标识一段文本中的关键方面或意图。
- 主题建模:发现大型文本数据集中隐藏的主题和结构。
自然语言处理可以做什么?
NLP 用于各种应用程序。以下是一些最常见的区域。
消息过滤器
消息过滤器是最早的基本在线自然语言处理应用程序之一。该技术最初用于创建垃圾邮件过滤器,以根据某些单词或短语识别不需要的邮件。随着自然语言处理的发展,过滤器也在发展。
这种技术最常见和最新的应用之一是 Gmail 的电子邮件分类。该系统可以根据其内容将电子邮件分为三类(主要、社交网络或促销)。这使 Gmail 用户可以更好地管理他们的收件箱,以便快速查看和回复重要的电子邮件。
智能助手
Siri (Apple) 和 Alexa (Amazon) 等智能助手使用语音识别来识别语音模式、推断含义并建议有用的响应。今天,向 Siri 提问并让她理解我们并以相关的方式回答似乎很正常。同样,我们逐渐习惯于每天通过恒温器、灯、汽车等与 Siri 或 Alexa 互动。
我们现在希望 Alexa 和 Siri 等助手能够捕捉到上下文线索,帮助我们在日常生活中完成某些任务(例如订购商品)。我们甚至喜欢他们有趣的回答或他们向我们介绍他们自己。随着他们了解我们,我们的互动变得更加个人化。根据《纽约时报》的文章《为什么我们可能很快就会生活在 Alexa 的世界里》,“一个重大转变即将到来。Alexa 很可能会成为这十年的第三大消费者平台。
搜索结果
搜索引擎使用自然语言处理,根据相似的搜索行为或用户意图显示相关结果。这使每个人都可以在没有任何特殊技能的情况下找到他们需要的东西。
例如,当您开始输入查询时,Google 会向您显示热门的相关搜索,但它也可以识别出确切措辞之外的查询的一般含义。如果您在 Google 中输入航班号,您将了解其状态。如果您输入股票代码,您将获得一份股票报告。如果您输入数学方程式,您将获得一个计算器。您的搜索可以提供各种结果,因为它使用的自然语言处理技术将模糊查询与给定实体相关联,以提供有用的结果。
直观的键入
自动更正、自动完成和直观输入等功能在当今的智能手机上非常普遍,以至于我们认为它们是理所当然的。自动键入和直观键入与搜索引擎类似,因为它们依赖于键入的内容来建议单词或短语的结尾。自动更正有时甚至会更改一些单词以提高消息的整体含义。
此外,这些功能会随着您的作而变化。例如,直观的键入会随着时间的推移适应您的特定短语。这有时会导致有趣的信息交流,句子完全基于直觉输入。结果可能令人惊讶地个人化和信息量大,有时甚至会引起一些媒体的关注。
译本
如果你的外语练习充满了语法错误,你的老师很可能会知道你使用自然语言处理技术作弊。不幸的是,许多语言不适合直接翻译,因为它们具有不同的句子结构,有时被翻译服务所忽视。然而,这些系统已经取得了长足的进步。
借助自然语言处理,在线翻译工具可以提供更准确和语法正确的翻译。因此,如果您需要与不会说您的语言的人交流,它们非常有用。如果您需要翻译外文文本,这些工具甚至可以识别输入进行翻译的文本的语言。
数字电话
在给一些公司打电话时,我们大多数人可能都听到了“此电话可能会被录音以用于培训目的”的公告。虽然这些录音可用于培训目的(例如,分析与心怀不满的客户之间的交流),但它们通常存储在允许自然语言处理系统学习和增长的数据库中。自动化系统将客户呼叫重定向到代理或在线聊天机器人,他们将提供相关信息来回答他们的请求。这种自然语言处理技术已被许多公司使用,包括主要的电话运营商。
数字电话呼叫技术还允许计算机模仿人声。因此,可以计划自动电话以在车库或理发店进行预约。
数据分析
自然语言功能现已集成到分析工作流程中。事实上,越来越多的 BI 供应商正在为其数据可视化提供自然语言界面。例如,更智能的可视化编码允许根据数据的语义为特定任务提出最佳的可视化效果。任何人都可以使用自然语言语句或问题片段来探索数据,这些问题的关键词被解释和理解。
使用语言探索数据使数据更易于访问,并为整个企业开放分析,超越通常的 IT 分析师和开发人员圈子。
文本分析
文本分析使用各种语言、统计和机器学习技术将非结构化文本数据转换为可分析的数据。
对于品牌来说,情绪分析似乎是一项艰巨的挑战(尤其是在拥有大量客户群的情况下)。但是,基于自然语言处理的工具通常可以查看客户互动(例如社交媒体上的评论或评论,甚至提及品牌名称)以了解它们是什么。然后,品牌可以分析这些互动,以评估其营销活动的有效性或监控客户问题的演变。然后,他们可以决定如何响应或改进他们的服务以提供更好的体验。
自然语言处理还通过提取关键字和识别非结构化文本数据中的模式或趋势来促进文本分析。主要的 NLP 模型有哪些?
虽然 NLP 已经存在了一段时间,但最近的进步非常显着,特别是随着基于 transformer 的模型和领先科技公司开发的大规模语言模型的兴起。一些最先进的模型包括:
-
基于 Transformer 的模型:
- BERT 和 ALBERT (Google AI)
- RoBERTa (Meta/Facebook), StructBERT (阿里巴巴), DeBERTa (Microsoft), DistilBERT (抱脸)
- XLNet (卡内基梅隆大学), UniLM (Microsoft), Reformer (Google)
-
大型语言模型 (LLM):
- GPT-3、GPT-4 和 GPT-4 Turbo (OpenAI)
- Claude 3 (人类学)
- PaLM 2 和 Gemini 1.5 (Google DeepMind)
- LLaMA 2 (元)
- Mistral 和 Mixtral (Mistral AI)
在本教程中,我们将仔细研究如何将 BERT 用于 NLP。
Google BERT 是如何工作的?
BERT 来自首字母缩写词“Bidirectional Encoder Representations from Transformers”,是 Google AI 发布的一个模型。这项创新技术基于自然语言处理 (NLP)。
该算法本质上使用机器学习和人工智能来理解互联网用户提出的查询。因此,它试图解释他们的搜索意图,即他们使用的自然语言。
从这个意义上说,BERT 与 Google Home 等个人语音助手相关联。该工具不再基于用户输入的每个单词,而是考虑整个表达式及其所在的上下文。这样做是为了优化结果。无论使用何种媒介,它在处理复杂搜索时都更加高效。
更具体地说,BERT 允许搜索引擎:
- 解决表达中的歧义,同时考虑到单词的上下文含义;
- 了解代词对应什么,尤其是在长段落中;
- 解决同音异义问题;
- 理解下面的句子;
- 直接在 SERP(搜索引擎结果页)中给出答案......
对于其他应用,BERT 用于:
- 问答;
- 意见分析;
- 句子匹配和自然语言推理;
- 检测冒犯性推文。
因此,Google BERT 对以自然方式输入的最长查询的影响约为 10%。
自然语言处理侧重于分析用户键入的单词。为了更好地理解查询,将检查关键字、其前身和后继词。这就是 “transformers” 采用的分析原则。
该算法对于介词影响含义的长尾搜索特别有效。另一方面,它对通用查询的影响就不那么重要了,因为 Google 已经很好地理解了它们。因此,其他理解工具仍然有效。
无论查询是以无序还是精确的方式表述,搜索引擎仍然能够处理它。但为了提高效率,最好使用更合适的术语。
上下文在 BERT 执行的分析中起着重要作用。机器翻译和语言建模得到优化。在生成高质量文本方面也取得了重大改进。
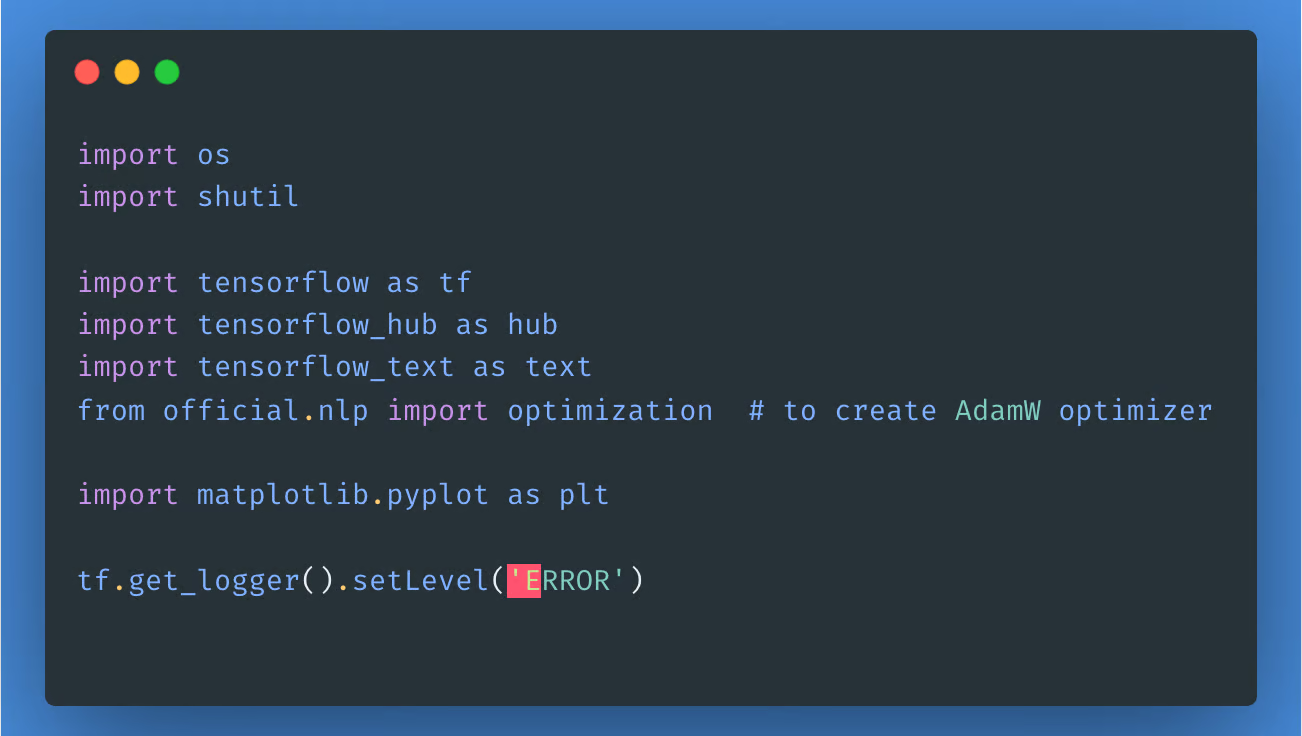
要使用此模型,我们首先导入必要的库和包,如下所示:
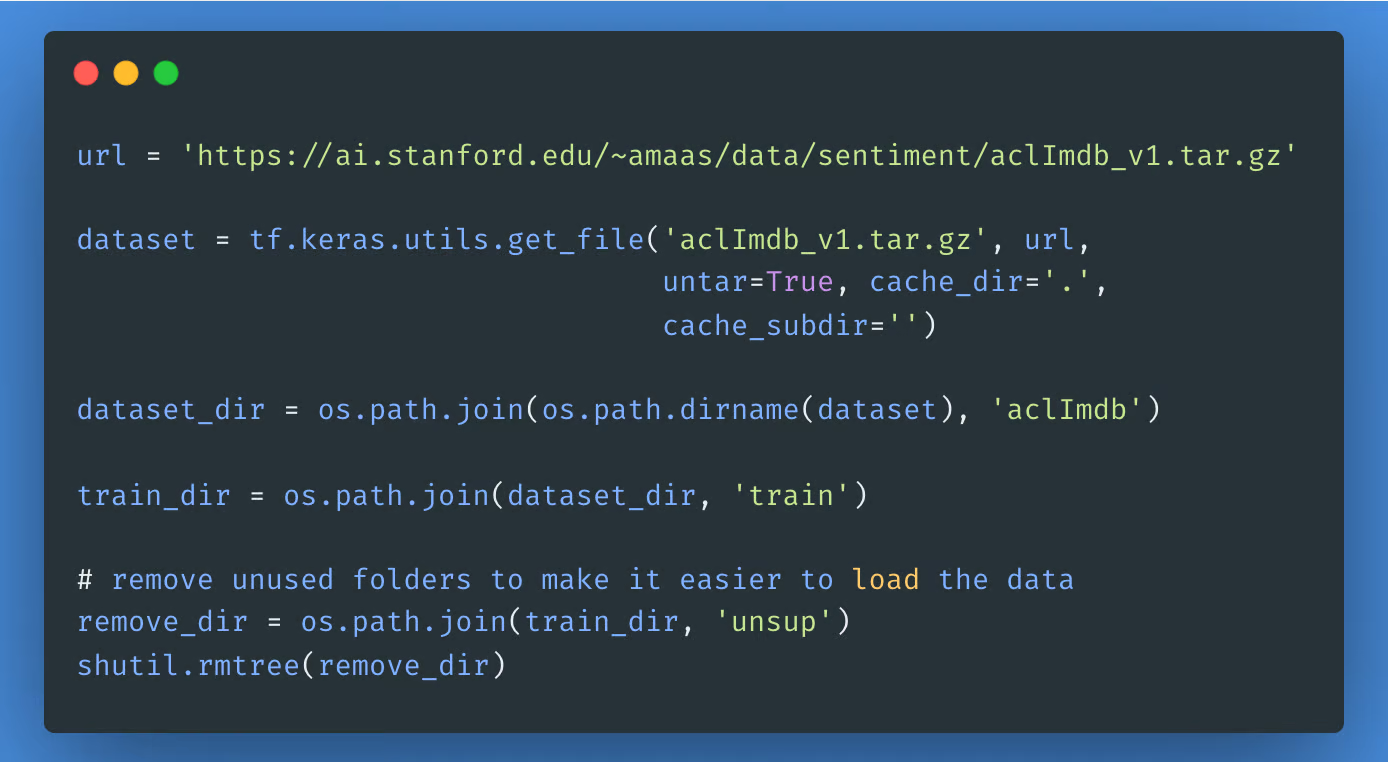
接下来,让我们下载并提取 Large Movie Review Dataset,然后浏览目录的结构。
要创建带标签的 tf.data.Dataset,我们将使用 text_dataset_from_directory,如下所示。接下来,我们将使用 validation_split 参数,使用 80:20 的训练数据分割创建一个验证集。
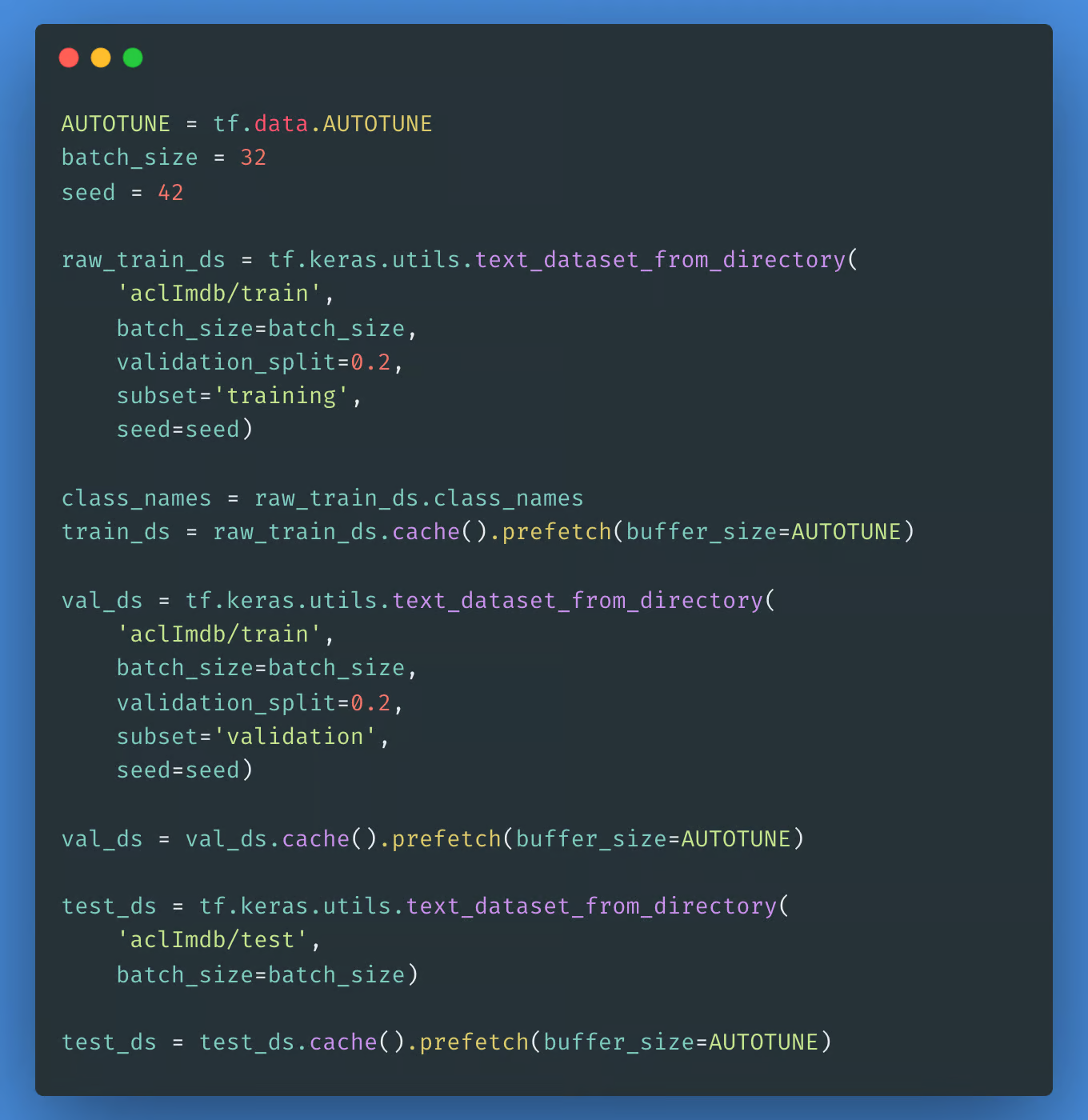
在使用 validation_split 时指定随机种子非常重要,这样验证和训练分割就不会重叠。 下一步将是选择要从 Tensorflow Hub 加载和微调的 BERT 模型,您可以使用该中心。KerasLayer 来组成您的微调模型。然后,我们将对一些文本尝试预处理模型并查看输出。

接下来,您将构建一个简单的模型,该模型由预处理模型、您在前面的步骤中选择的 BERT 模型、密集层和 Dropout 层组成。
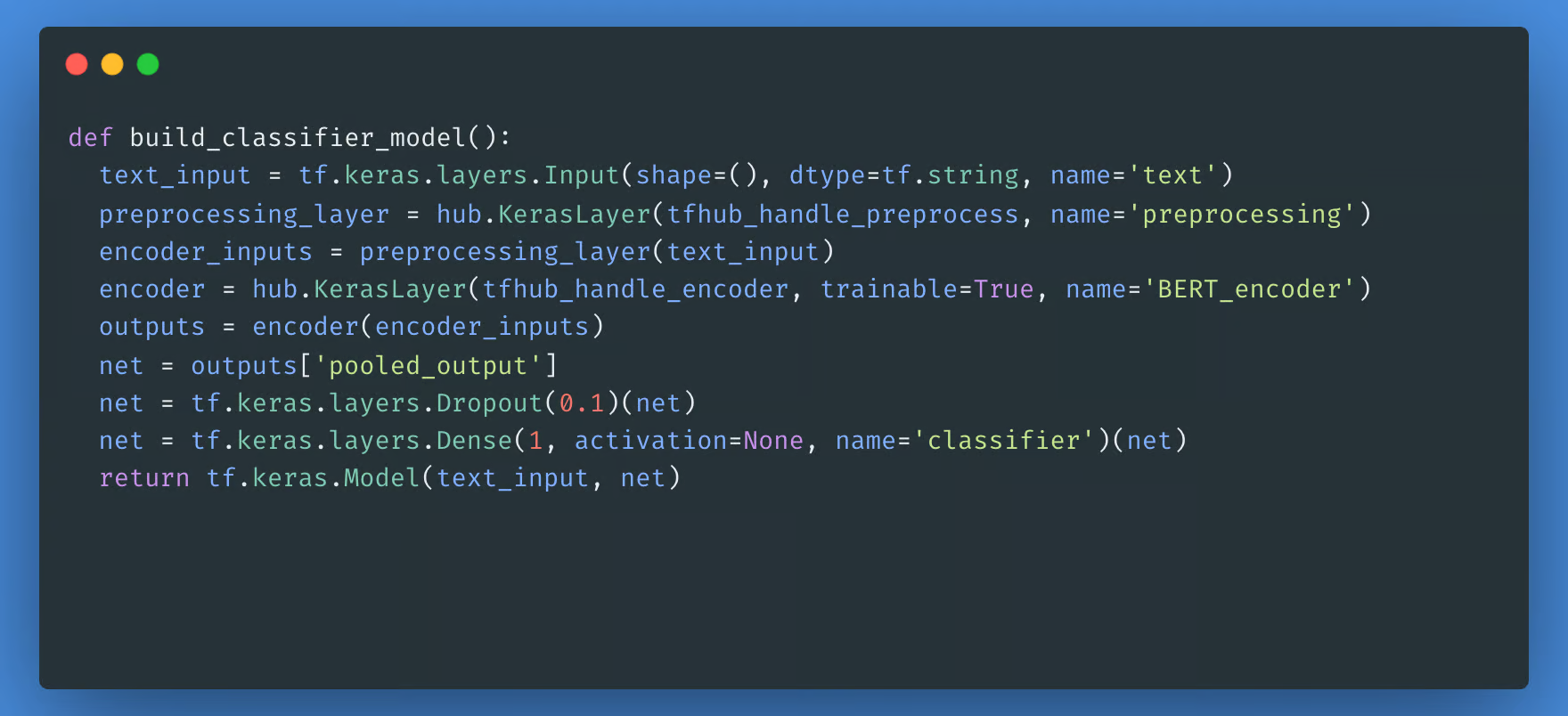
现在,您可以检查您的模型是否使用预处理模型的输出运行。

loss 函数是这里的必要步骤,我们将选择 losses。BinaryCrossentropy 损失函数,因为我们正在处理一个二元分类问题。

为了进行微调,我们使用 BERT 最初训练时使用的相同优化器:“Adaptive Moments” (Adam)。此优化器可最大程度地减少预测损失,并通过权重衰减进行正则化。
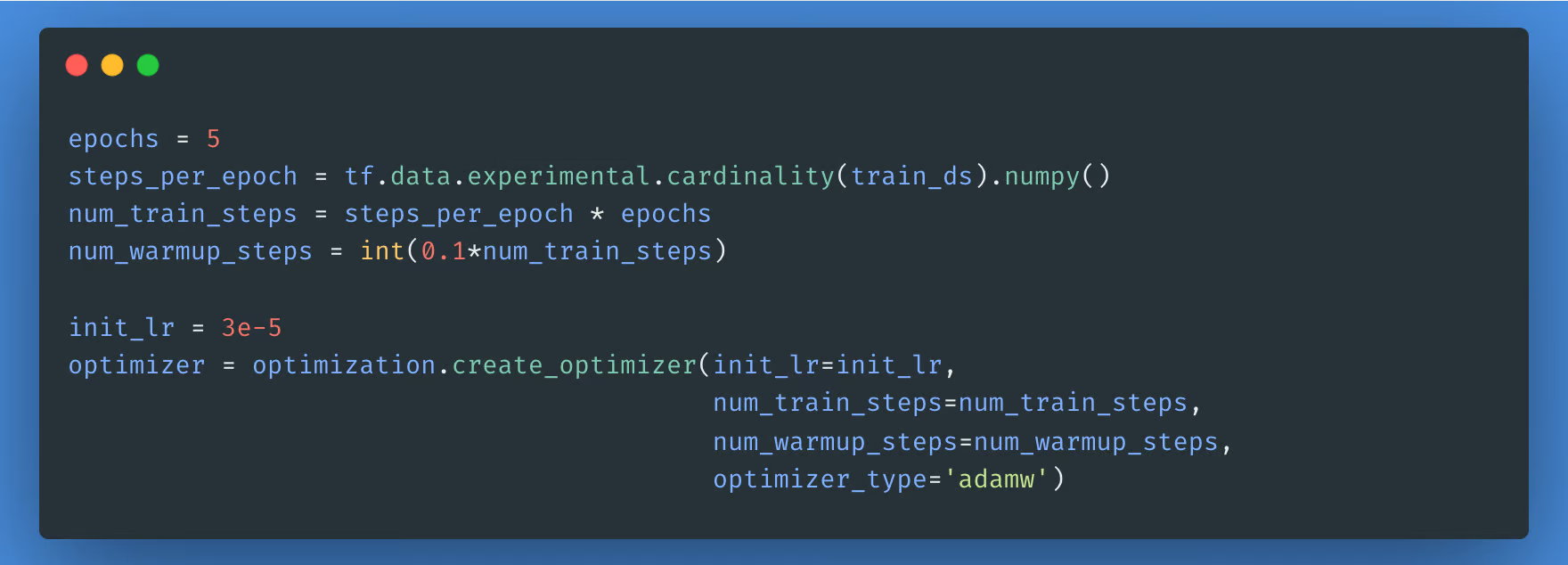
使用您之前创建的classifier_model,您可以使用 loss、metric 和 optimizer 编译模型。

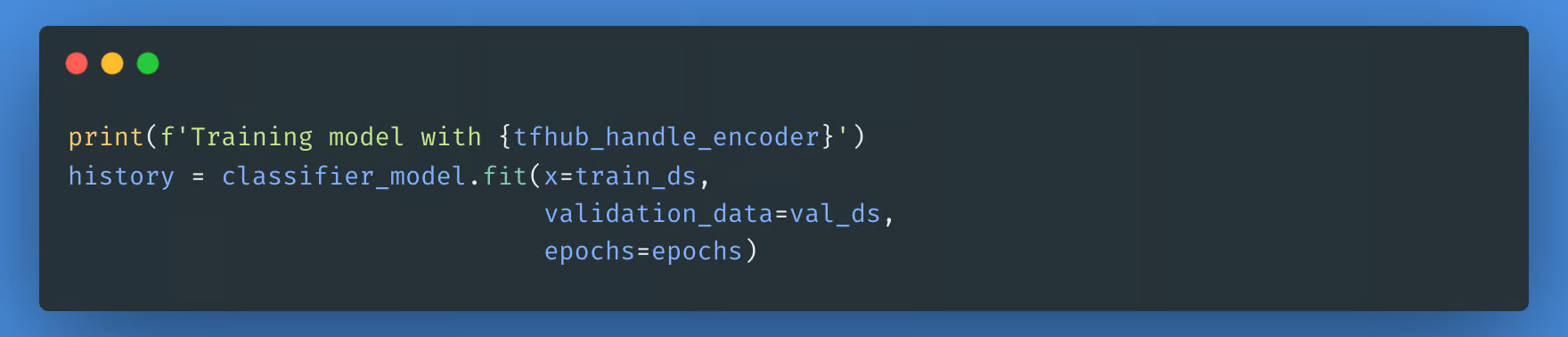
请注意,您的模型可能需要更少或更多的时间来训练,具体取决于您选择的 BERT 模型的复杂程度。
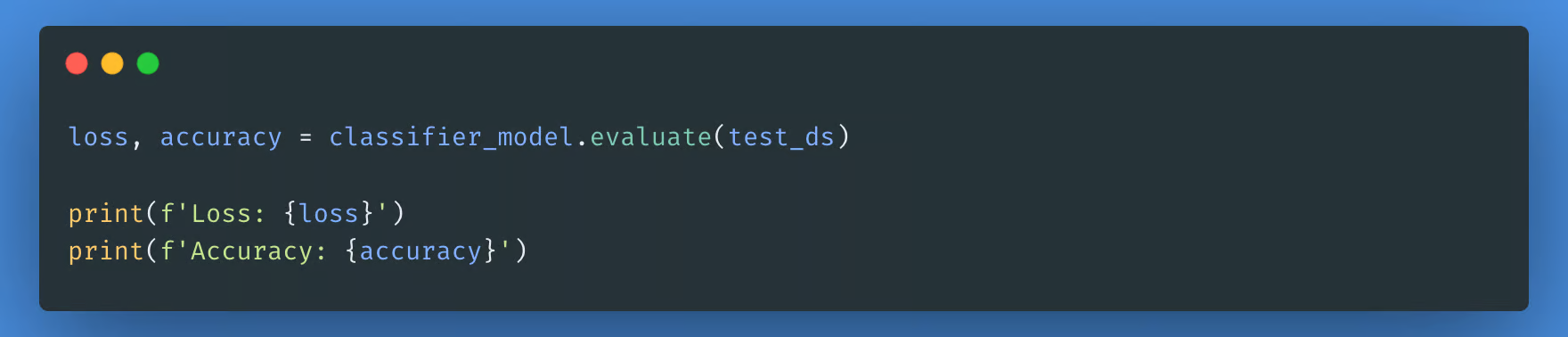
现在,我们将通过检查模型的损失和准确性来评估模型的性能。
如果您想绘制训练集和验证集的损失和准确率,则可以使用 history 对象:
您可以练习上述步骤并运行代码,以查看列表中每个 BERT 模型的输出。
结论
自然语言处理在数字世界中已经很成熟。随着公司和行业发现它的好处并采用它,它的应用将成倍增加。虽然人工干预对于更复杂的通信问题仍然是必不可少的,但自然语言处理将成为我们的日常盟友,首先管理和自动化次要任务,然后随着技术的进步处理越来越复杂的任务。
要了解有关 NLP 的工作原理和使用方法的更多信息,请查看我们的NLP深度学习。


















 923
923

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









