







一、基本原理
停车场车位检测(Parking Space Detection)是一项结合计算机视觉和深度学习的技术,旨在实时检测停车场中的空闲车位。这一技术的核心步骤包括图像获取、图像预处理、车位定位和状态识别。以下是详细的解析:
1、图像获取:
使用摄像头或无人机等设备获取停车场的图像或视频流。这些图像将作为后续处理的输入数据。
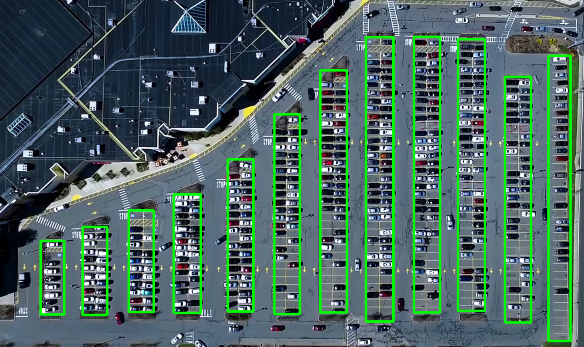
2、图像预处理:
降噪: 使用高斯模糊、中值滤波等方法去除图像中的噪音,提高后续处理的准确性。
imgBlur = cv2.GaussianBlur(imgGray, (3, 3), 1)
灰度化: 将彩色图像转化为灰度图像,减少数据维度,简化计算。
imgGray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
二值化: 应用自适应阈值处理,将灰度图像转换为黑白图像,便于区分前景和背景。
imgThreshold = cv2.adaptiveThreshold(imgBlur, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY_INV, 25, 16)
形态学处理: 使用膨胀、腐蚀等操作进一步优化图像,消除噪点,平滑边缘。
kernel = np.ones((3, 3), np.uint8)
imgDilate = cv2.dilate(imgMedian, kernel, iterations=1)
3、车位定位:
通过霍夫变换、边缘检测等方法确定每个车位的具体位置,并记录这些位置。
list_of_lines = cv2.HoughLinesP(roi_image, rho=0.1, theta=np.pi/10, threshold=15, minLineLength=9, maxLineGap=4)
手动或自动划定每个车位的矩形区域,并保存这些坐标供后续使用。
cv2.rectangle(img, pos, (pos[0] + width, pos[1] + height), (255, 0, 255), 2)
4、状态识别:
计算每个车位内的非零像素数目,以此判断车位是否被占用。
imgCrop = imgPro[y:y+height, x:x+width]
count = cv2.countNonZero(imgCrop)
根据设定的阈值,标记空闲车位并统计空闲车位的数量。
if count < 640:
color = (0, 255, 0)
spaceCount += 1
thickness = 5
else:
color = (0, 0, 255)
thickness = 2
cv2.rectangle(img, pos, (pos[0] + width, pos[1] + height), color, thickness)
二、常用算法
1、传统方法:
支持向量机(SVM):
SVM是一种监督学习模型,适用于小到中等规模的数据集。它通过寻找一个超平面将数据分成两类,最大化决策边界,从而实现分类。
svm = cv2.ml.SVM_create()
svm.train(np.samples, cv2.ml.ROW_SAMPLE, labels)
在车位检测中,SVM常用于提取的颜色、纹理等特征进行分类,具有较高的准确性。
局部二值模式(LBP):
LBP是一种有效的纹理特征描述符,通过对局部区域内像素与中心像素的比较生成二值编码,反映纹理信息。
lbp = cv2.LBPCompute(img)
hist = cv2.calcHist([lbp], [0], None, [256], [0, 256])
结合SVM等分类器,LBP可用于识别车位图像中的纹理特征,判断车位是否被占用。
形态学操作和边缘检测:
形态学操作(如膨胀、腐蚀、开闭运算)通过结构元素改变图像形态,去除噪点,平滑边缘。
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
morph = cv2.morphologyEx(imgThreshold, cv2.MORPH_CLOSE, kernel)
边缘检测(如Canny算子)通过计算图像梯度,检测边缘。
edges = cv2.Canny(imgGray, low_threshold, high_threshold)
2、深度学习方法:
卷积神经网络(CNN):
CNN是一种专为图像处理设计的深度学习模型,包含卷积层、池化层和全连接层。通过多次卷积和池化操作,逐层提取图像的高级特征。
model = keras.models.Sequential([
keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)),
keras.layers.MaxPooling2D((2, 2)),
keras.layers.Flatten(),
keras.layers.Dense(128, activation='relu'),
keras.layers.Dense(1, activation='sigmoid')
])
CNN在端到端的训练过程中,能够自动学习和提取图像特征,应用于车位检测中,具有高准确性和较强的泛化能力。
YOLOv5:
YOLO(You Only Look Once)通过一次前向传播即可完成目标检测,速度极快。
model = torch.hub.load('ultralytics/yolov5', 'yolov5s')
results = model(img)
YOLOv5在实时检测中表现优异,尤其适合大规模停车场的实时监控和检测。
非局部操作网络:
非局部操作借鉴了图像去噪中的NL-mean和时间序列处理中的Self-attention思想,融合长程时间和空间信息。
class NonLocalBlock(nn.Module):
def __init__(self, in_channels):
super(NonLocalBlock, self).__init__()
self.query = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)
self.key = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)
self.value = nn.Conv2d(in_channels, in_channels, kernel_size=1)
def forward(self, x):
batch_size, _, height, width = x.size()
query = self.query(x).view(batch_size, -1, height * width).permute(0, 2, 1)
key = self.key(x).view(batch_size, -1, height * width)
energy = torch.bmm(query, key)
attention = F.softmax(energy, dim=-1)
value = self.value(x).view(batch_size, -1, height * width)
out = torch.bmm(value, attention.permute(0, 2, 1))
return out.view(batch_size, -1, height, width)
非局部操作能够直接获取图像边缘高频特征,提升模型对远距离特征的敏感性,特别适合检测车位图像中的细节特征。
三、性能评估
评估指标:
准确率(Accuracy):
表示正确识别的车位占总识别数量的比例。
accuracy = tp / (tp + fp)
召回率(Recall):
表示正确识别的空闲车位占所有实际空闲车位的比例。
recall = tp / (tp + fn)
实时性(Real-time Performance):
量化系统处理每帧图像所需的时间,通常用FPS(Frames Per Second)衡量。
fps = 1 / processing_time_per_frame
鲁棒性(Robustness):
测试系统在不同环境条件下的稳定性,如光照变化、行人干扰、天气状况等。
robustness = 1 - (fp + fn) / total_samples
常见挑战:
光照变化:
- 强光、阴影等光照条件的变化会影响图像的质量,进而影响识别的准确性。
行人干扰:
- 行人和其他移动物体可能导致误检,干扰车位的状态识别。
恶劣天气:
- 雨雪等天气条件会使图像模糊,降低分辨率,增加检测难度。
小目标检测:
- 特别是在室外停车场,远处的小型车辆难以清晰辨识,模型需加强对此类目标的敏感度。
四、总结
综合以上讨论,基于OpenCV的停车场车位检测技术通过一系列图像处理和机器学习算法,实现了高效的车位识别。传统方法如SVM和LBP在特定环境下表现良好,但在复杂场景中存在局限。深度学习特别是CNN和YOLOv5的应用,大大提高了系统的实时性和鲁棒性,能够应对各种复杂环境。未来的研究方向将继续围绕如何提升低质量图像的识别率、增强模型的泛化能力和优化计算效率展开。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









