 Stable Diffusion负图像提示全解析
Stable Diffusion负图像提示全解析




前言
大家好,我是小南。
许多AI图像生成器,包括Stable Diffusion,都可以使用图像作为提示来生成相似的图像。另一方面,我们使用正向文本提示词来描述我们想要什么,使用反向文本提示词来描述我们不想要什么。那么负图像提示是什么呢?
在这篇文章中,将描述在Stable Diffusion中负图像提示的实现,并分享一些有趣的用例。
例如,从房屋中减去草坪并获得冬季房屋!

一. Stable Diffusion中的图像提示
在Stable Diffusion中使用图像提示有以下几种方法。
(1)图生图:使用图像提示的最原始方式。图像被转换为潜在的、添加的噪声并用作去噪的初始潜在图像。它可以生成遵循颜色和构图的相似图像。
(2)**ControlNet reference-only:**它通过模型注入参考图像,并将其中间图像部分添加到注意层的潜在图像中。
(3)**IP-adapter:**它是一种神经网络模型,可以在Stable Diffusion中实现图像提示。它简单而有效。它使用模型从参考图像中提取特征。然后,它使用单独的注意力网络来注入特征,而不是重复使用文本提示的特征。
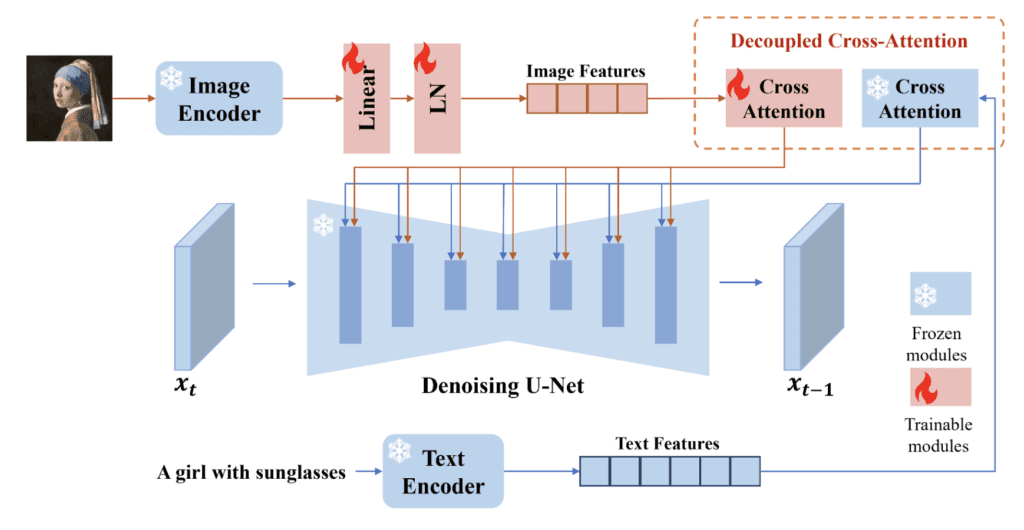
在这3种方法中,IP-adapter产生的效果最好。
二. 否定提示词的发展简史
最初,基于扩散的人工智能图像生成器可以生成随机的高质量图像。但没有办法控制你生成的内容。它只是生成类似于训练数据的图像。
然后,CFG(classifier-free guidance无分类器引导)开始发挥作用。它劫持注意力层,将文本嵌入注入到采样步骤中。然后使用图像和标题对训练模型。生成图像时,模型将图像转向提示文本,远离随机图像。
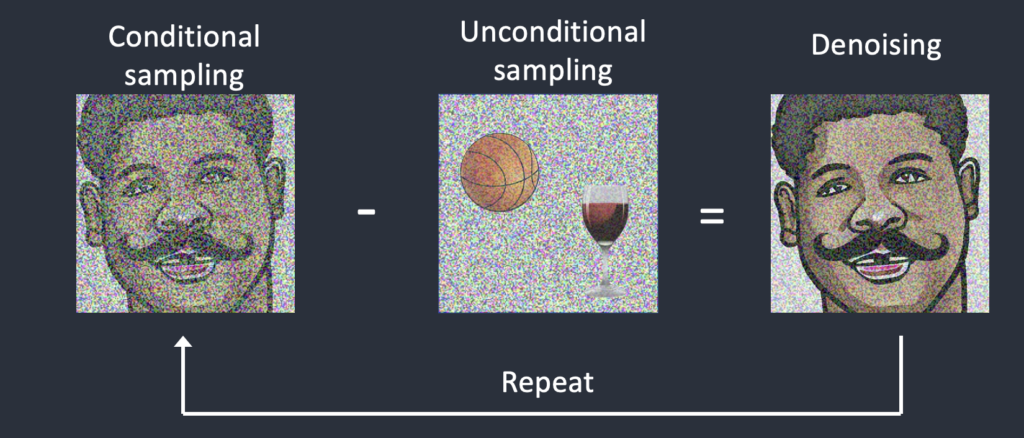
不使用否定提示进行采样
这一切都是学术性的。但随着Stable Diffusion的发布,这种情况发生了变化。它是开源、免费的,并且可以通过低功耗计算机访问。很多人都开始玩了。他们并不是想发表论文,而是想破解软件来做他们想做的事。
代码立即发布。迭代速度很快。然后,AUTOMATIC1111 破解了无分类器引导以启用负面提示。
这个想法很简单:你不是避开随机图像,而是避开负面提示所描述的图像。从技术上讲,您只需要将未调节的潜像替换为经过负提示调节的潜像。

于是,负面提示就诞生了。我们免费使用它,只是采样步骤的变化。我们不需要训练新模型。
三. 负图像提示(Negative image prompt)
否定提示的技术可以应用于图像。我们将负图像编码为嵌入,并将其注入“无条件”潜伏的采样过程中。这与否定提示词实现方式完全相同。IP-adapter提供了执行此操作的所有机制。
基于这个想法,使用IP-adapter实现了负像提示。最好在没有文本提示词的情况下使用,因此条件仅基于正面和负面图像提示。
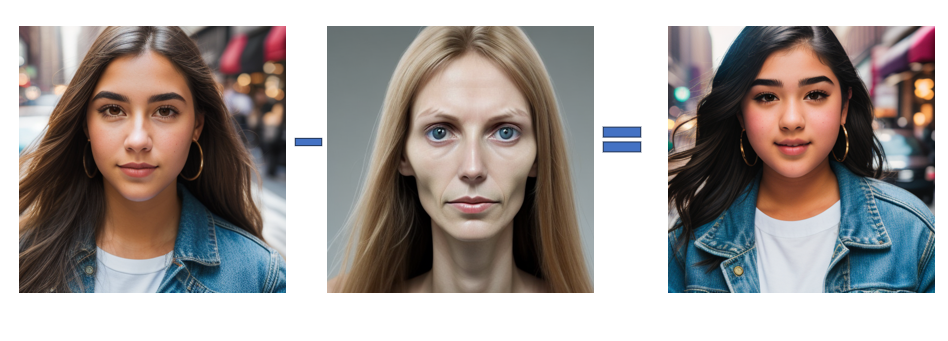
可以从房子里减去绿色草坪。在下雪的冬天,它变成了一座房子。第一个图像是正图像提示。第二个图像是负图像提示。第三张图像是通过稳定扩散生成的。

从街道场景中减去汽车

从一张脸中减去另一张脸
四. 演示环境运行
可以在google Colab上面进行操作。
(1)访问网站:https://github.com/sagiodev/IP-Adapter-Negative
(2)单击“使用”部分下的“在 Colab 中打开”图标。
(3)启动服务,直到控制台出现gradio.live 链接。

(4)访问链接https://9050758bf0998111a3.gradio.live/。
打开的界面效果如下:
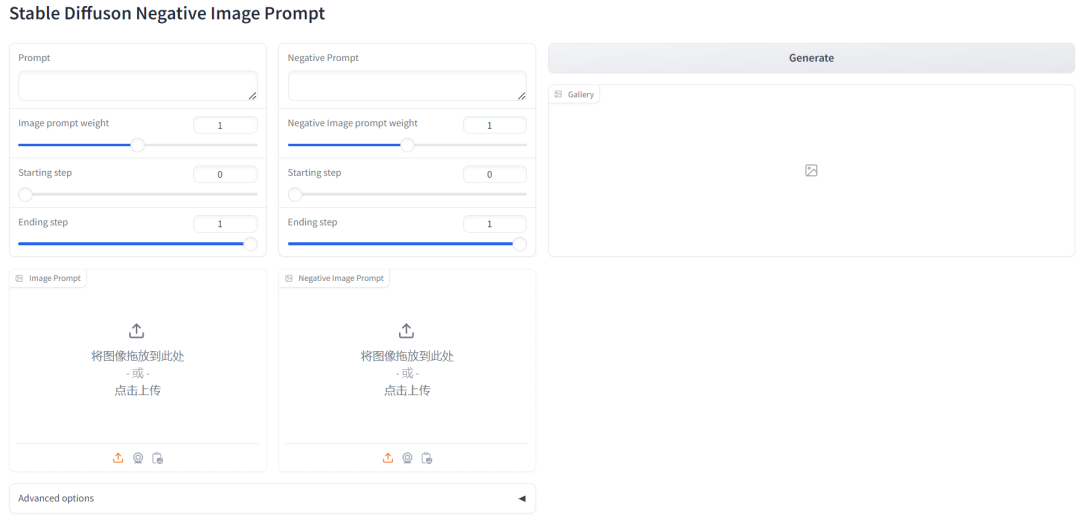
五. 基本用法
负图像提示使用建议:
-
提供正面图像和负面图像提示。将文本提示词留空。
-
提供文本提示词和负图像提示。将正图像提示留空。
将正图像上传到“图像提示”画布,将负图像上传到“负图像提示”画布。将正向提示词和否定提示词留空。点击“生成”生成图像。
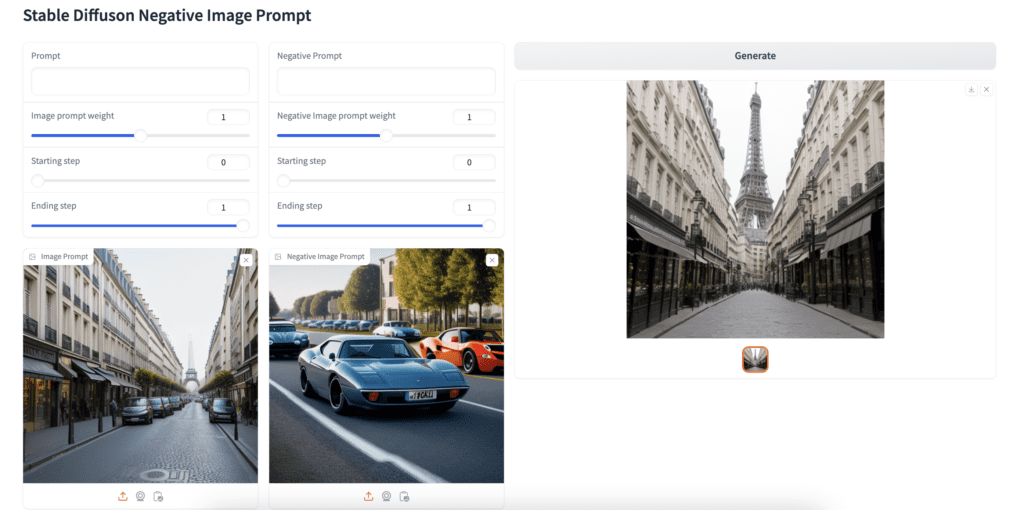
六. 高级用法
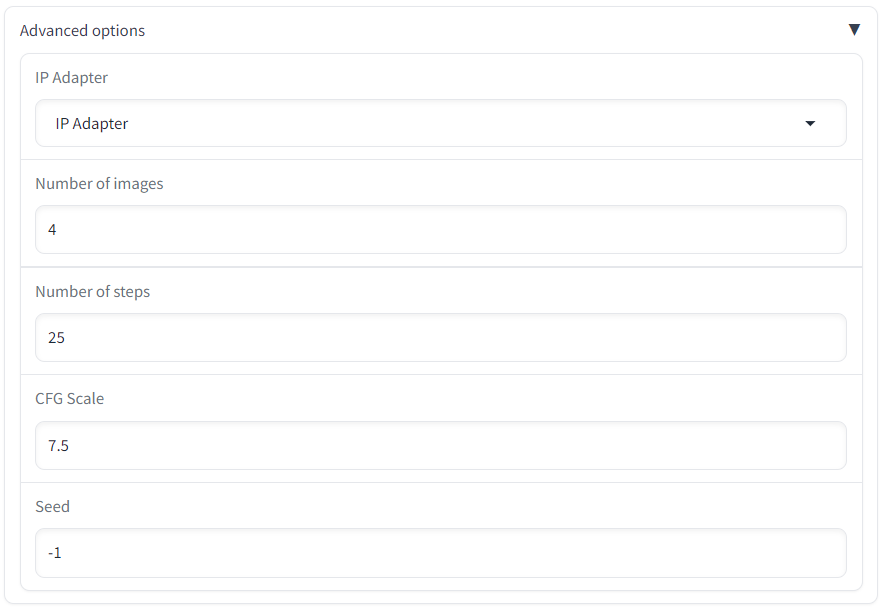
我们可以选择正向提示词和反向提示词与图像提示一起使用。也可以调整图像提示的权重来控制文本和图像提示之间的相对效果。
-
IP Adapter:可以选择 IP-adapter或者IP-adapter Plus。
IP-adapter Plus 使用更先进的模型来提取图像特征。它更紧密地遵循参考图像。
-
Image prompt weight: 图片提示权重,图片提示相对于文本提示的效果。
-
Starting step:应用图像提示的第一步。0 表示第一步。1表示最后一步。
-
Ending step:应用图像提示的最后一步。0 表示第一步。1表示最后一步。
-
CFG Scale:无分类器的引导强度控制文本和图像提示的遵循程度。设置更高值以更紧密地跟随。
六. 技术细节
IP Adapter使用机器学习模型从图像中提取特征。原始IP Adapter使用 CLIP 视觉模型和简单的投影层来提取图像特征。
图像特征与文本提示的嵌入类似。因此,它们可用于调节图像生成中的去噪过程。
IP Adapter方法训练自己的注意力矩阵来调节扩散。相同的矩阵适用于正图像提示和负图像提示。
当使用无分类器指导时,我们需要对每个图像生成的两个潜在特征进行去噪。一种是以文本提示为条件的。另一种是无条件的。潜像向两者之差的方向移动。
否定提示词破坏了“无条件”潜伏。图像变得更像正向提示词而不是否定提示词。
同样我们也可以对IP Adapter执行相同的操作。首先从正负图像提示中提取特征。正向图像特征决定了条件潜伏,负向图像特征决定了“无条件”潜伏。
因此,潜像向图像提示移动,并远离负图像提示。
好了,今天的分享就到这里了,希望今天分享的内容对大家有所帮助。
关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
零基础AI绘画学习资源介绍
👉stable diffusion新手0基础入门PDF👈


👉AI绘画必备工具👈

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉AI绘画基础+速成+进阶使用教程👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
👉12000+AI关键词大合集👈

这份完整版的AI绘画全套学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 3548
3548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









