




 本文深入探讨了Kafka如何利用页缓存技术、磁盘顺序写入以及零拷贝技术实现每秒上百万的高并发写入。通过操作系统页缓存进行内存写入,结合磁盘顺序写提高磁盘性能,加上零拷贝技术减少数据传输中的拷贝操作,Kafka达到了极高的数据写入和消费性能。
本文深入探讨了Kafka如何利用页缓存技术、磁盘顺序写入以及零拷贝技术实现每秒上百万的高并发写入。通过操作系统页缓存进行内存写入,结合磁盘顺序写提高磁盘性能,加上零拷贝技术减少数据传输中的拷贝操作,Kafka达到了极高的数据写入和消费性能。
篇文章来聊一下kafka的一些架构设计原理,这也是互联网公司面试时非常高频的技术考点。
Kafka是高吞吐低延迟的高并发、高性能的消息中间件,在大数据领域有极为广泛的运用。配置良好的Kafka集群甚至可以做到每秒几十万、上百万的超高并发写入。
那么Kafka到底是如何做到这么高的吞吐量和性能的呢?这篇文章我们来一点一点说一下。
一、页缓存技术 + 磁盘顺序写
首先Kafka每次接收到数据都会往磁盘上去写,如下图所示:

那么在这里我们不禁有一个疑问了,如果把数据基于磁盘来存储,频繁的往磁盘文件里写数据,这个性能会不会很差?大家肯定都觉得磁盘写性能是极差的。
没错,要是真的跟上面那个图那么简单的话,那确实这个性能是比较差的。
但是实际上Kafka在这里有极为优秀和出色的设计,就是为了保证数据写入性能,首先Kafka是基于操作系统的页缓存来实现文件写入的。
操作系统本身有一层缓存,叫做page cache,是在内存里的缓存,我们也可以称之为os cache,意思就是操作系统自己管理的缓存。
你在写入磁盘文件的时候,可以直接写入这个os cache里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把os cache里的数据真的刷入磁盘文件中。
仅仅这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘,大家看下图:
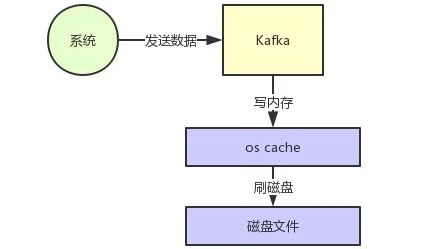
接着另外一个就是kafka
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









