




 本文详细介绍了Hadoop的三大核心组件HDFS、YARN及MapReduce的功能与工作流程。HDFS用于解决海量数据的存储问题,通过NameNode、DataNode和SecondaryNameNode实现数据的可靠存储;YARN作为资源管理系统,负责调度集群中的计算资源;MapReduce则提供了一种高效的数据处理框架,通过Map和Reduce两个阶段实现并行计算。
本文详细介绍了Hadoop的三大核心组件HDFS、YARN及MapReduce的功能与工作流程。HDFS用于解决海量数据的存储问题,通过NameNode、DataNode和SecondaryNameNode实现数据的可靠存储;YARN作为资源管理系统,负责调度集群中的计算资源;MapReduce则提供了一种高效的数据处理框架,通过Map和Reduce两个阶段实现并行计算。
1、hadoop
主要解决,海量数据的存储和计算。
优势:高可靠性(数据有备份),高扩展性(动态增加节点),高效性(多台服务器并行计算),高容错(失败的任务重新分配到其他服务器)。
2、hadoop组成
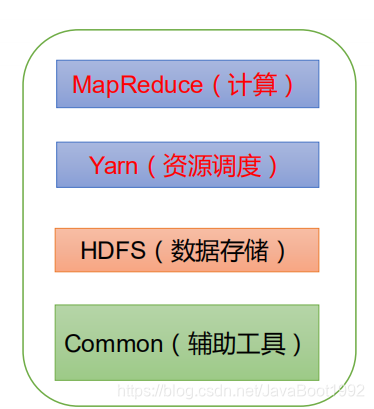
1、HDFS架构
一、NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
二、DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
三、Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
一个nn对应多个dn,2nn是做nn备份的防止nn挂机出现数据的丢失。
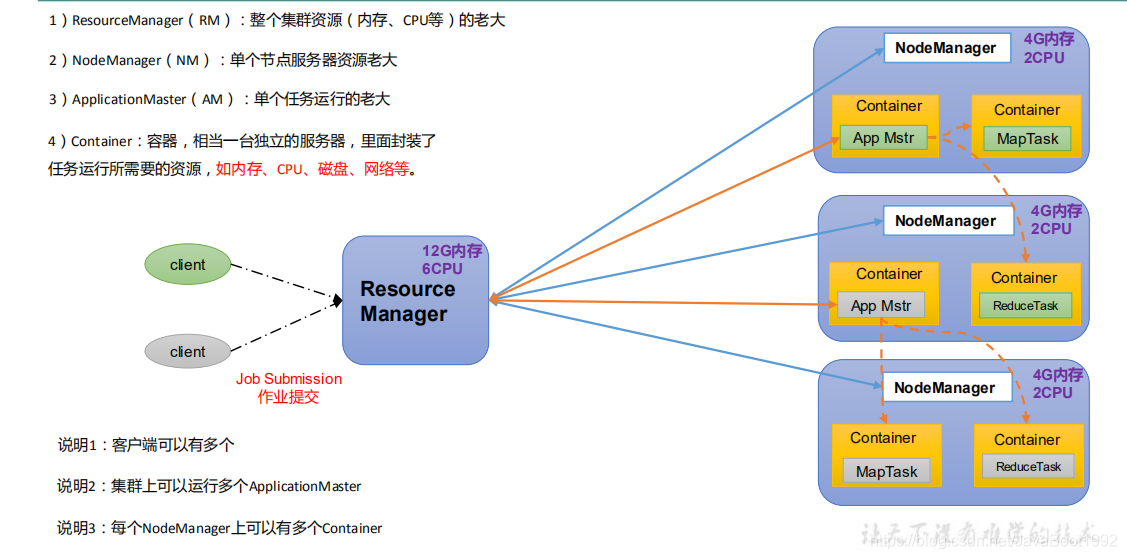
2、YARN架构
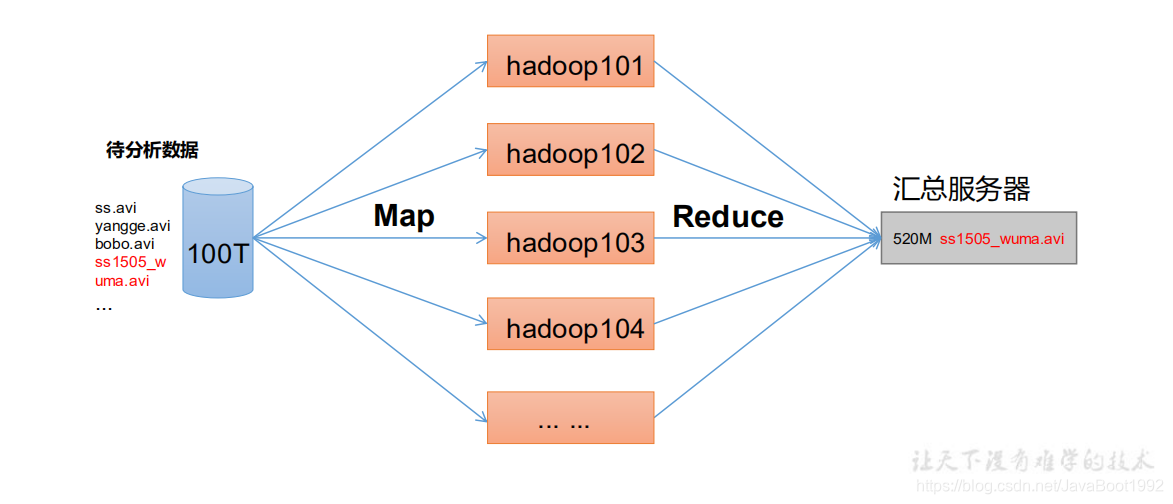
3、MapReduce架构
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
1)Map 阶段并行处理输入数据
2)Reduce 阶段对 Map 结果进行汇总
4、 HDFS、YARN、MapReduce 三者关系
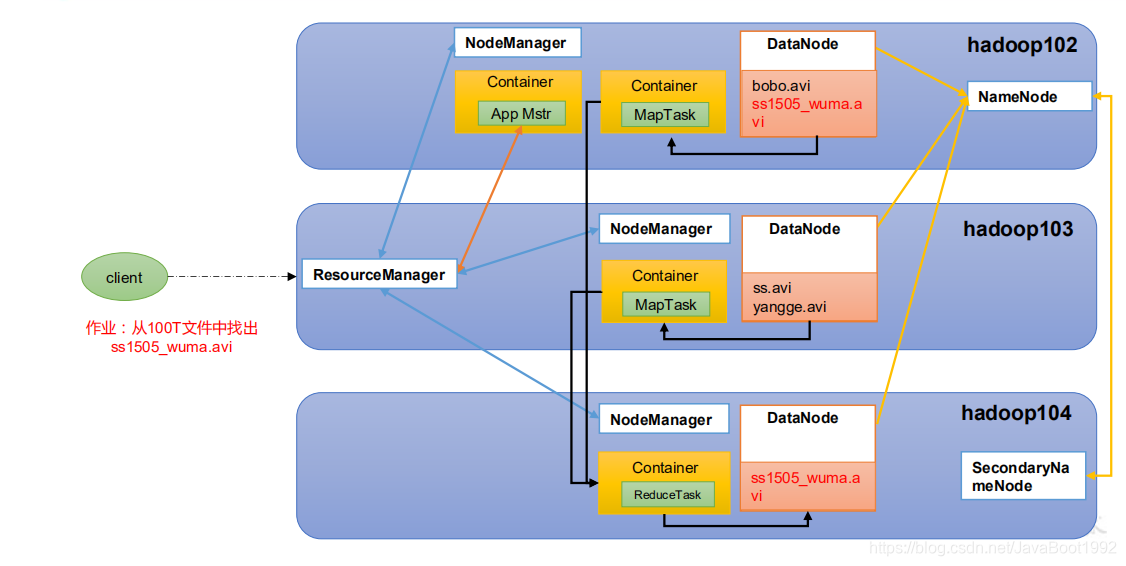
大致流程 首先第一步《HDFS阶段》NameNode配置多个数据存储点DataNode,并且有他的备份文件SecondaryNameNode。
第二步《YARN阶段》client提交查找任务给ResourceManager下的某个NodeManager,然后NodeManager创建一个App Mstr单个任务老大访问ResourceManager分配资源(内存,cpu)。
第三步《MapReduce阶段》App Mstr创建多个Map Task任务查询多个节点数据,查询结果Reduce Task任务返回给App Mstr。
码字不易,给个赞或者关注吧,希望大家一起进步

















 1045
1045

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









