




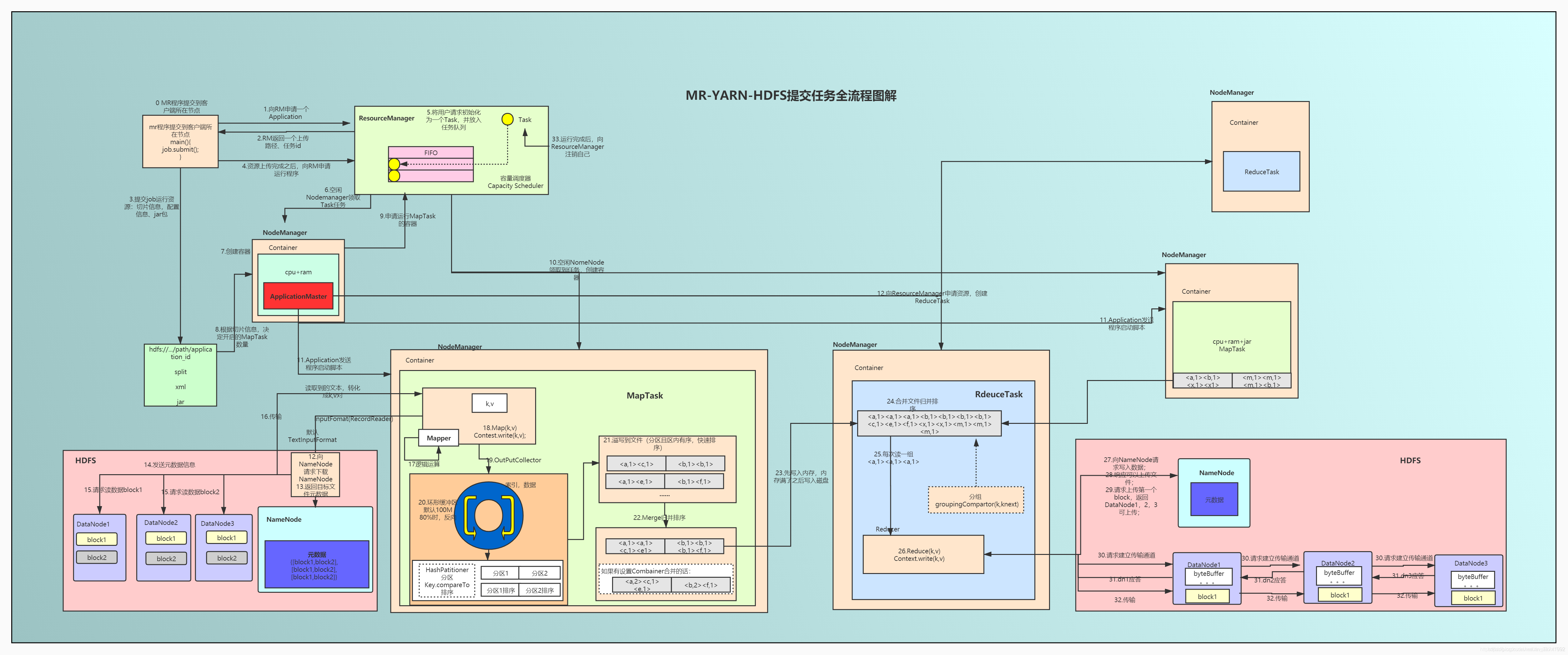
1、提交jar包程序到节点,想RM申请资源.
2、返回一个路径和一个task文件夹,task文件夹再这个路径中
3、转向hdfs文件存储系统找对应的文件,并对文件进行切片操作,然后会在task中创建jar(运行的java代码),job.split(文件的切片信息,默认情况下切片大小等于hdfs文件存储block大小,128M),job.xml(里面包含job运行所需的配置)。
4、向RM(资源老大)申请运行ApplicationMaster(mapTask管理)程序
5、初始化一个task,并放入队列中,等待被领取
6、空闲的Nodemanager领取task任务
7、创建Container容器,并且配置cpu+ram等资源。
8、把上面的资源文件copy到NodeManager节点Container容器中,并根据jar开启ApplicationMaster(mapTask管理),并根据切片(切片有多种方式,可以查看前几篇文档)信息分配需要几个MapTask(一个切片对应一个MapTask)
9、向RM申请需要多加几个MapTask容器
10、空闲的NameNode领取任务并创建容器(一个或多个)
11、ApplicationMaster(mapTask管理)向MapTask所在容器发送启动脚本
12、MapTask容器向HDFS中NameNode请求下载文件。
13、NameNode返回给MapTask容器文件的元数据信息。
14、MapTask容器向HDFS发送元数据信息。
15、对多个DateNode请求数据串行执行的(有的文件很大,可能分割成多个block存在不同的DateNode上),这里设计网络拓扑-节点距离计算会找寻最近的节点数据下载。
16、传输数据,读取文本,并转化为k,v对形式。
17、这里可以继承Mapper接口
18、Map方法中对(k,v)数据做自己的的业务逻辑,然后ConTest.write(k,v)输出。
19、通过OutPutController输出到环形缓冲区。
20、环形缓冲区默认大小100M,阈值是80%,根据分区,快排(详细可以查看大数据第六篇shuffle)
21、溢写到磁盘文件
22、多个溢写文件进行归并排序(分区的话,每个分区归并排序)
如果设置了Combainer合并的话这里也可以合并(减少网络传输)
23、通过网络传输把数据copy拉取到ReduceTask容器中(可能在同一节点,可能不在),先放在内存中(速度快),满了的话再写到磁盘中。
24、因为存在多个MapTask的输出,所以这里要进行归并排序
25、每次读一组(k,v)这里涉及hadoop为什么要默认对key排序,因为26步会获取相同key的values值,如果不排序每次都需要遍历查询,效率低。
26、Reduce方法中对(k,v)数据做自己的的业务逻辑,然后ConTest.write(k,v)输出
27、向HDFS中的NameNode请求写入数据。(涉及网络拓扑-节点距离计算)找最近的。
28、NameNode响应可以上传文件。
29、Reduce容器请求上传第一个Block(0~128M),NameNode返回DateNode节点1,2,3可以上传。
30、Reduce容器与DateNode请求建立传输通道,串联方式请求1到2到3
31、3到2到1分别作出应答。
32、串联方式开始传输数据1到2到3,这样就形成了3个副本。
33、完成后向ResourceManager注销自己的资源。
大数据学习 Yarn--MapReduce--HDFS整体流程详细总结
最新推荐文章于 2024-01-04 11:57:18 发布
 本文详细介绍了Hadoop MapReduce的执行过程,从提交jar包到资源申请,再到MapTask和ReduceTask的执行,包括文件切片、数据传输、排序与合并等关键步骤,深入解析了Hadoop大数据处理的核心机制。
本文详细介绍了Hadoop MapReduce的执行过程,从提交jar包到资源申请,再到MapTask和ReduceTask的执行,包括文件切片、数据传输、排序与合并等关键步骤,深入解析了Hadoop大数据处理的核心机制。

















 3381
3381


 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言








