




 本文详细介绍了HDFS(Hadoop Distributed File System)的优缺点,包括其高容错性和适合大数据处理的特点。内容涵盖了HDFS的架构,其中讨论了根据磁盘传输速度调整数据块大小的策略。还阐述了HDFS的shell操作命令以及API使用。在写流程中,解释了客户端如何通过DistributedFileSystem与NameNode交互,以及数据在DataNode间的传输过程。读流程则涉及客户端如何从NameNode获取数据块位置并从DataNode读取。此外,文章提到了节点距离计算方法,用于选择最近的DataNode进行数据传输。
本文详细介绍了HDFS(Hadoop Distributed File System)的优缺点,包括其高容错性和适合大数据处理的特点。内容涵盖了HDFS的架构,其中讨论了根据磁盘传输速度调整数据块大小的策略。还阐述了HDFS的shell操作命令以及API使用。在写流程中,解释了客户端如何通过DistributedFileSystem与NameNode交互,以及数据在DataNode间的传输过程。读流程则涉及客户端如何从NameNode获取数据块位置并从DataNode读取。此外,文章提到了节点距离计算方法,用于选择最近的DataNode进行数据传输。
HDFS优点

HDFS缺点

HDFS架构

这里注意管理数据的块大小是根据磁盘的传输速度得来的,一盘磁盘传输速率为100M/s 所有块设置为128M
如果使用固态硬盘传输速率达到300M到400M,块可以设置大小为256M。
hdfs之shell操作命令可以参考百度类似linux
hdfs之api操作
1、配置hadoop环境,环境变量配置
org.apache.hadoop
hadoop-client
3.1.3
maven中导入对应maven包版本号与服务器中版本号一致

第一步:获取文件系统,创建FileSystem,这里注意红字部分为设置一些基础配置这里配置了文件的生成总数(包含镜像),这里涉及到优先级
(1)客户端代码中设置的值 >(2)ClassPath 下的用户自定义配置文
件 >(3)然后是服务器的自定义配置(xxx-site.xml)>(4)服务器的默认配置(xxx-default.xml)
第二步:为具体要做的操作具体api可以百度下
第三步:关闭资源
HDFS写流程

(1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检查目标文件是否已存在,父目录是否存在。
(2)NameNode 返回是否可以上传。
(3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4)NameNode 返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3。 (5)客户端通过 FSDataOutputStream 模块请求 dn1 上传数据,dn1 收到请求会继续调用
dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3 逐级应答客户端。
(7)客户端开始往 dn1 上传第一个 Block(先从磁盘读取数据放到一个本地内存缓存),
以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet
会放入一个应答队列等待应答。 (8)当一个 Block 传输完成之后,客户端再次请求 NameNode 上传第二个 Block 的服务
器。(重复执行 3-7 步)。
HDFS读流程

(1)客户端通过 DistributedFileSystem 向 NameNode 请求下载文件,NameNode 通过查
询元数据,找到文件块所在的 DataNode 地址。
(2)挑选一台 DataNode(就近原则,然后随机)服务器,请求读取数据。 (3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位
来做校验)。
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
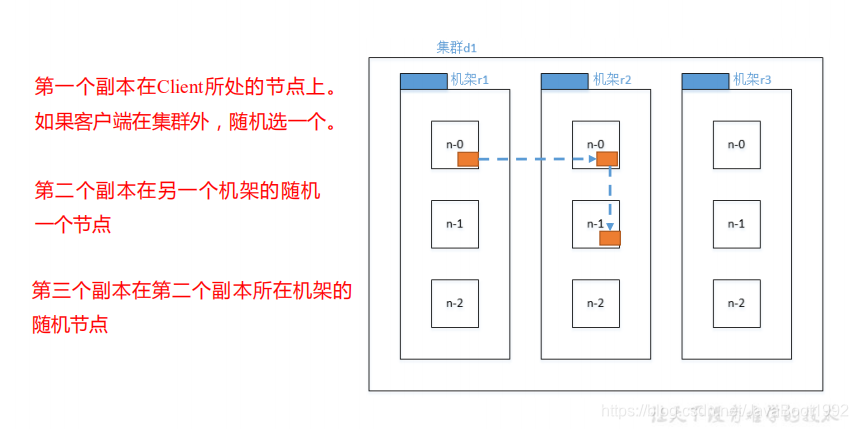
网络拓扑-节点距离计算
在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接
收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。

副本存储节点根据官方选择要求:

















 2021
2021

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









