




 本文介绍了Involution,一种具有空间特异性和通道不变性的新型算子,挑战了CNN的传统特性。作者提出了RedNet,通过Involution在图像分类、检测、分割任务中展现了优势。与传统ResNet相比,它在参数量和计算效率上更具优势。尽管在性能上不如Transformer,但在NLP领域可能有潜在优势。
本文介绍了Involution,一种具有空间特异性和通道不变性的新型算子,挑战了CNN的传统特性。作者提出了RedNet,通过Involution在图像分类、检测、分割任务中展现了优势。与传统ResNet相比,它在参数量和计算效率上更具优势。尽管在性能上不如Transformer,但在NLP领域可能有潜在优势。
该原创内容首发于GaintPandaCV,转载请获得授权并标明出处
【写在前面】
在被Transformer结构刷榜之前,CNN一直都是CV任务的标配。卷积有两个基本性质,分别是空间不变性 (spatial-agnostic)和通道特异性 (channel-specific)。空间不变性使得卷积能够在所有位置共享参数,并充分利用视觉特征的“平移等变性”。通道特异性使得卷积能够充分建模通道之间的关系,提高模型的学习能力。
但是任何事物其实都是有两面性的,这两个性质在具有优点的同时,也同样存在缺点(缺点会在Motivation中进行具体分析)。因此,作者脑洞打开,将卷积的性质进行了反转,提出了一个新的算子——Involution,这个算子具有空间特异性和通道不变性。最终,基于Involution结构,作者提出了实例化网络结构RedNet,并在分类、检测、分割任务上提点明显。
(
这篇工作其实是作者在rethink卷积的性质之后提出的一个新的结构,虽然相比于最近几篇ViT的文章,这篇文章在性能上显得有些无力。但是相比于ResNet结构,这篇文章无论是在参数量,还是计算量、性能上都有非常大的优越性。
另外,这篇文章其实是加强了空间上的建模,减弱了通道上建模关系。个人感觉视觉特征上的通道信息还是比较有用的,而相比之下,文本的通道信息作用就没有那么大,而文本上的空间关系是更加有用的。所以,个人觉得,按照这个思路,Involution在NLP 领域说不定提点效果会更加明显,有兴趣的同学也可是在NLP任务中试试Involution的效果,效果应该会比TextCNN会好一些,说不定能达到跟Transformer差不多的结果。
)
1. 论文和代码地址
Involution: Inverting the Inherence of Convolution for Visual Recognition
论文地址:https://arxiv.org/pdf/2103.06255.pdf
代码地址:https://github.com/d-li14/involution
核心 代码:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/conv/Involution.py
2. Motivation
前面说到了CNN的空间不变性 (spatial-agnostic)和通道特异性 (channel-specific)有一些优点,但这些优点有时候也会变成缺点。
CNN在空间不变性表现在:卷积核在所有的空间位置上都共享参数,那就会导致不同空间位置的局部空间建模能力受限,并无法有效的捕获空间上长距离的关系。
CNN的通道特异性指的是:输出特征的每个通道信息是由输入特征的所有通道信息聚合而来,并且参数不共享,所以就会导致参数和计算量比较大。并且,也有一些工作表明了不同输出通道对应的卷积滤波器之间是存在信息冗余的,因此对每个输出通道都使用不同的卷积核这一方式其实是并不高效的。
因此,基于发现的这两个缺点,作者采用了一种非常“简单粗暴”的方式来解决这两个缺点——把整两个性质颠倒一下,提出一个“空间特异性”和“通道不变性”的算子。
3. 方法
3.1. 卷积的过程
在介绍Involution之前,我们先回顾一下正常卷积的过程:
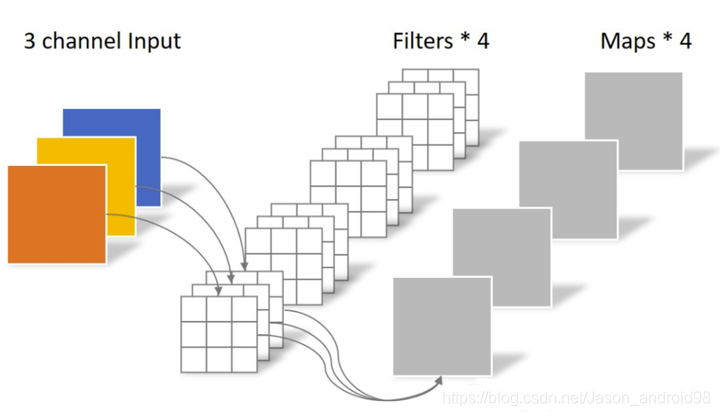
(图来自https://zhuanlan.zhihu.com/p/339835983)
如上图所示,正常卷积的卷积核大小为 C o × C i n × K × K C_o \times C_{in} \times K \times K Co×Cin×K×K,可以看出卷积核矩阵的大小,我们也可以看出,卷积的参数与输入特征的大小H和W是无关的,因此具有空间不变性;与输入和输出通道的数量是呈正比的,因此具有通道特异性。可以表示成下面的公式:
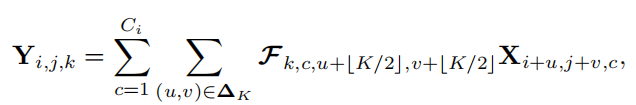
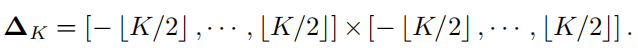
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3069
3069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









