






1 Logistic 回归原理
Logistic 回归模型是一种典型的线性回归分类机。
从数据集角度分析,假定一种有 mmm 个样本的数据集为:
T={(x(1),y(1)),⋯ ,(x(m),y(m))}
T=\{(x^{(1)},y^{(1)}),\cdots,(x^{(m)},y^{(m)})\}
T={(x(1),y(1)),⋯,(x(m),y(m))}
其中 x(i)∈Rn,i=1,2,⋯ ,mx^{(i)}\in \mathbb{R}^n, i =1,2,\cdots,mx(i)∈Rn,i=1,2,⋯,m, 表示数据集有 nnn 个 features. y(i)∈{0,1},i=1,2,⋯ ,my^{(i)}\in \{0,1\}, i =1,2,\cdots,my(i)∈{0,1},i=1,2,⋯,m,代表0-1分类。
Logistic 回归的目的就是,已知 xxx,预测 xxx 对应的类别标签 yyy .
1.1 Logistic 回归模型结构
下面例子假设数据集有2个features n=2,则x(i)∈{x(1),x(2)}x^{(i)} \in \{x^{(1)},x^{(2)}\}x(i)∈{x(1),x(2)}
则模型结构如下
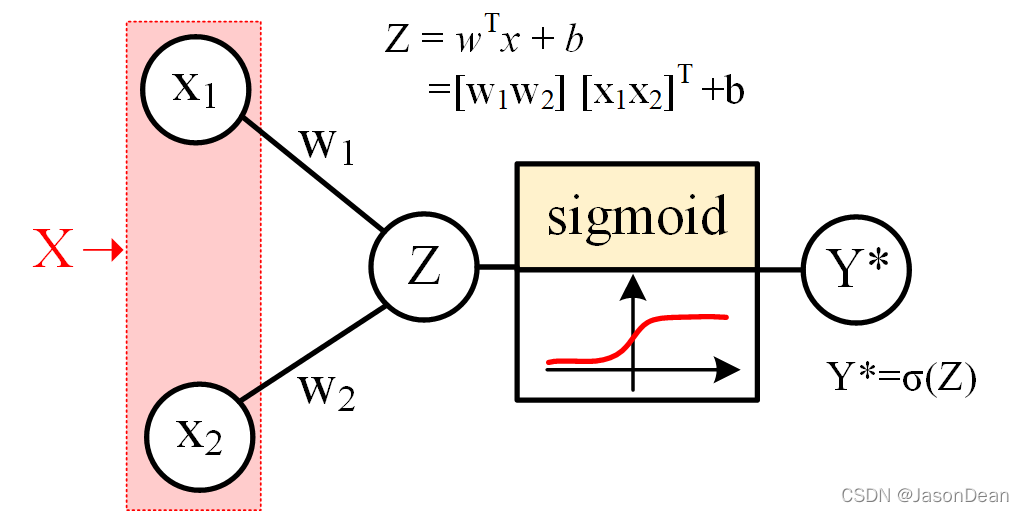
即为:
Y∗=σ(WTX+b)
Y^*=\sigma(W^{\rm T}X+b)
Y∗=σ(WTX+b)
利用数据集理解该公式,即已知 xxx,得到 y=1y=1y=1 的条件概率为 :
P(𝑦=1∣𝒙)=Y∗=σ(WTX+b)∈(0,1)
P(𝑦 = 1|𝒙)=Y^*=\sigma(W^{\rm T}X+b) \in (0,1)
P(y=1∣x)=Y∗=σ(WTX+b)∈(0,1)
则 Logistic回归的分类判别标准为:
P(y(i)=1∣x(i))=11+e(−w⊤x(i)−b)P(y(i)=0∣x(i))=e(−w⊤x(i)−b)1+e(−w⊤x(i)−b)
P(y^{(i)}=1| x^{(i)})=\frac{1}{1+e^ {\left(-\boldsymbol{w}^{\top} \boldsymbol{x^{(i)}}-b\right)}} \\
P(y^{(i)}=0| x^{(i)})=\frac{e^ {\left(-\boldsymbol{w}^{\top} \boldsymbol{x^{(i)}}-b\right)}}{1+e^ {\left(-\boldsymbol{w}^{\top} \boldsymbol{x^{(i)}}-b\right)}}
P(y(i)=1∣x(i))=1+e(−w⊤x(i)−b)1P(y(i)=0∣x(i))=1+e(−w⊤x(i)−b)e(−w⊤x(i)−b)
选取概率最大的作为分类结果即可。
值得一提的是, Logistic 回归中,W1,W2W_1,W_2W1,W2 对应着X1,X2X_1,X_2X1,X2 的乘子 ,但是bbb对于X1,X2X_1,X_2X1,X2 是一个相等的实数,即 Z=[W1W2][X1X2]T+bZ = [W_1 W_2][X_1X_2]^T+bZ=[W1W2][X1X2]T+b
- bbb 仅仅为一个实数,而 WWW 是一个(2×1)(2\times 1)(2×1)的向量
- 对于参数可更新的模型,我们可以利用梯度下降算法优化参数 WWW 和 bbb从而提升模型性能。
2. 为何说Logistic 回归为一个线性回归模型
判断一个模型是否线性,及判断其决策边界(decision boundary)是否为直线
Logistic 回归的决策边界定义为:
P(y=1∣x)P(y=0∣x)=1e(−w⊤x(i)−b)=1
\frac{P(y=1|x)}{P(y=0|x)}=\frac{1}{e^ {\left(-\boldsymbol{w}^{\top} \boldsymbol{x^{(i)}}-b\right)}}=1
P(y=0∣x)P(y=1∣x)=e(−w⊤x(i)−b)1=1
则边界为:
−w⊤x(i)−b=0
-\boldsymbol{w}^{\top} \boldsymbol{x^{(i)}}-b = 0
−w⊤x(i)−b=0
对于一个二分类 2 features 模型而言,其数据集分类图如下,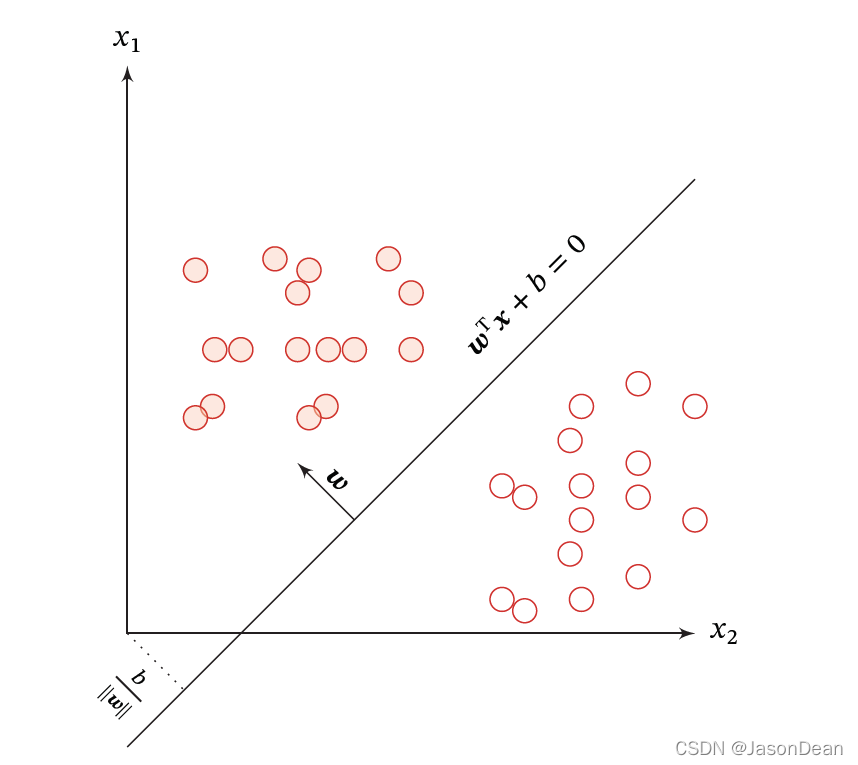
可见其决策边界为线性,其模型是线性模型。
可以看出,当数据集线性可分时,Logistic 回归结果可能不错,但是数据集不可线性分割时,Logistic 回归可能不是最佳模型


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











