 解决Slurm节点登录问题:NVIDIAGPU配置错误与恢复,
解决Slurm节点登录问题:NVIDIAGPU配置错误与恢复,




 文章讲述了在节点上遇到登录问题,发现gres.conf文件中引用的/dev/nvidia0不存在。通过执行nvidia-smi显示GPU信息并创建/dev/nvidia0,修复了Slurm服务并更新节点状态的过程,参考了SimpleLinuxUtilityforResourceManagement文档。
文章讲述了在节点上遇到登录问题,发现gres.conf文件中引用的/dev/nvidia0不存在。通过执行nvidia-smi显示GPU信息并创建/dev/nvidia0,修复了Slurm服务并更新节点状态的过程,参考了SimpleLinuxUtilityforResourceManagement文档。
1. 节点是可以ping通,也可以登录上去
2. 登录有问题节点后,
service slurmd status显示信息里有报错提示:
fatal: can't stat gres.conf file /dev/nvidia0: No such file or directory
gres.conf 文件(/opt/slurm/etc/gres.conf)里表明该节点有个tesla的GPU卡,它引用了/dev/nvidia0文件
NodeName=节点名 Type=tesla Name=gpu File=/dev/nvidia0
在该节点ls /dev 确实是没有看到/dev/nvidia0文件
3. 在该节点执行以下命令后,确实是显示了GPU卡的信息
nvidia-smi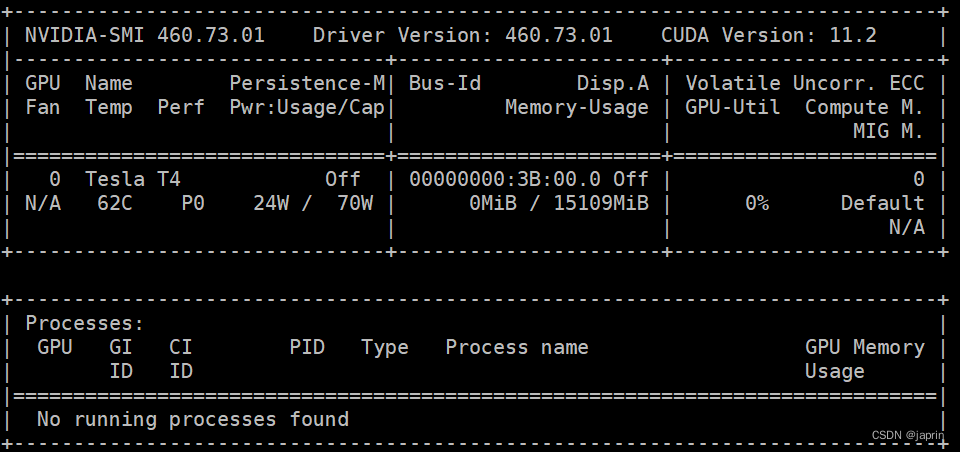
4. 神奇的是,执行完这个nvidia-smi后,/dev/里有nvidia0了。于是启动该节点的slurmd服务
service slurmd start清除该节点的down状态
scontrol update NodeName=节点名 State=idle5. 问题解决
解决问题过程参考了以下文档的提示: Simple Linux Utility for Resource Management

















 751
751

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









