








目录
本篇我们一起聊一下如何借助当下最热的开源推理模型 DeepSeek R1 和轻量级本地 AI 模型运行框架 Ollama,构建功能强大的 RAG 系统。
Ollama:本地模型运行的理想框架

比较早之前我们整理过一篇关于通过部署Ollama和Open WebUI来搭建本地的问答系统,后续也基于Ollama、Dify来复刻一套私有化部署的智能问答系统。大家可以再跳转《本地问答系统-部署Ollama、Open WebUI》、《加速AI应用开发:Dify——从构思到生产的一站式解决方案》、《Ollama、Dify和RAG:企业智能问答系统的黄金配方》来阅读内容。
Ollama 作为一款轻量级开源框架,为在本地运行 AI 模型提供了便捷高效的解决方案,是构建本地 RAG 系统的关键一环。它的出现,让开发者能够摆脱对云端计算资源的过度依赖,在本地设备上轻松部署和运行模型,大大降低了开发和部署成本,同时提升了系统的自主性和隐私性。
使用 Ollama 下载和安装模型非常简单。以运行 DeepSeek R1 模型为例,开发者只需在终端中执行简单的命令即可完成操作。如果希望使用默认的 7B 模型,运行 “ollama run deepseek-r1” 命令即可;若想尝试 1.5B 模型以适配轻量级 RAG 应用场景,运行 “ollama run deepseek-r1:1.5b” 命令就能轻松实现。这种便捷的操作方式,使得即使是技术经验相对较少的开发者,也能快速上手,开启 RAG 系统的开发之旅。
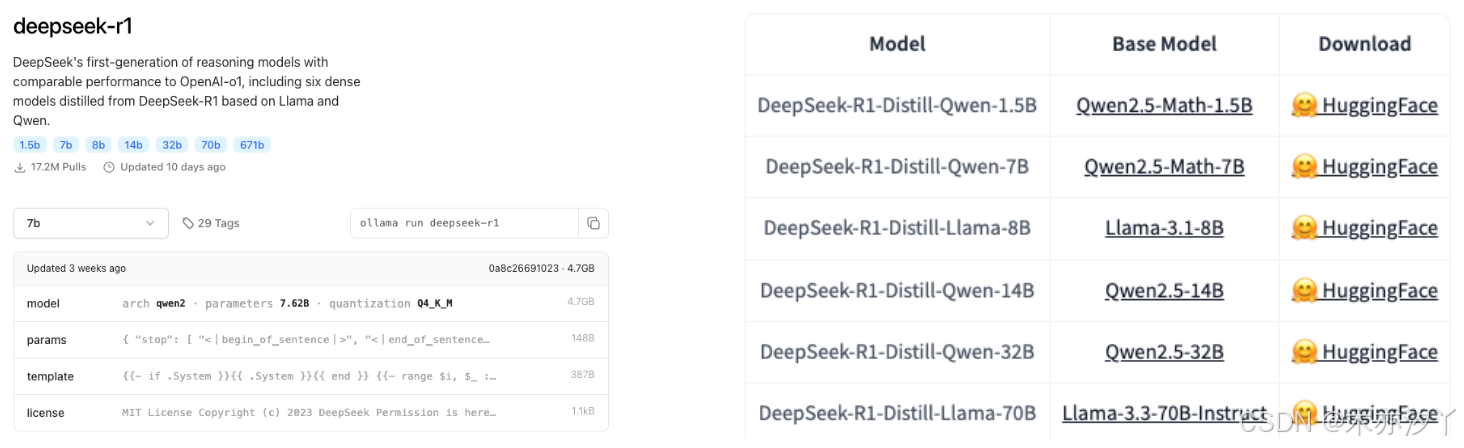
Ollama 支持多种模型,这为开发者提供了丰富的选择空间。不同的模型在性能、应用场景和资源需求等方面各有差异,开发者可以根据项目的具体需求,灵活挑选最适合的模型,从而实现系统性能的优化和资源的合理利用。无论是追求更高的推理能力,还是注重资源的高效利用,Ollama 都能满足开发者的多样化需求。
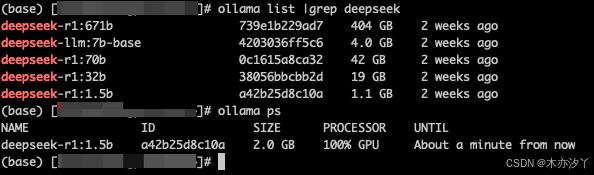
DeepSeek R1:RAG 系统的卓越之选

DeepSeek R1 在 RAG 系统构建领域脱颖而出,有着诸多令人瞩目的优势,堪称开发者的得力助手。性能比肩OpenAI o1,但其成本却大幅降低,仅为 o1 的 5%,这使得更多开发者和企业能够轻松负担,加速了 RAG 技术的广泛应用。
在检索环节,DeepSeek R1 展现出了极高的专注度。它在生成答案时,仅需使用 3 个文档块,就能精准地提取关键信息,避免了无关信息的干扰,显著提升了检索效率和回答的针对性。这一特性使得系统在处理大规模文档时,依然能够快速定位核心内容,为用户提供简洁而有效的答案。
在应对复杂问题或缺乏明确答案的情况时,DeepSeek R1 的严格提示机制发挥了重要作用。它不会像一些模型那样随意 “编造” 答案,而是在不确定时诚实地回复 “我不知道”,这种严谨的态度有效避免了幻觉现象,确保了回答的可靠性和真实性,让用户能够获得可信的信息。
对于许多开发者来说,数据安全和响应速度是至关重要的因素。DeepSeek R1 支持本地执行,无需依赖云端 API,这不仅消除了因网络延迟带来的困扰,还能让用户在本地环境中更加安全地处理敏感数据,无需担忧数据泄露风险,为特定行业和场景的应用提供了坚实的保障。
构建基于DeepSeek R1的本地 RAG 系统
1. 导入必要的依赖库
构建 RAG 系统需要借助多个强大的库来实现不同的功能。
- LangChain 库在文档处理和检索方面表现出色,它提供了丰富的工具和接口,能够简化文档加载、文本分割、嵌入生成以及检索等复杂操作;
- Streamlit 库则专注于打造用户友好的 Web 界面,让用户能够轻松地与系统进行交互,输入问题并获取答案;
- PDFPlumberLoader 来高效地从 PDF 文件中提取文本;
- SemanticChunker 用于智能地将文本分割成语义块;
- HuggingFaceEmbeddings 生成文本的向量嵌入,需要设置代理环境变量;
export HF_ENDPOINT=https://hf-mirror.com
或
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'- FAISS 创建可搜索的向量数据库;
- Ollama 与本地运行的 DeepSeek R1 模型进行交互。
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama安装依赖
pip install langchain-community
pip install langchain
pip install langchain_experimental
pip install streamlit
pip install pdfplumber
pip install semantic-chunkers
pip install open-text-embeddings
pip install ollama
pip install prompt-template
pip install sentence-transformers
pip install faiss
pip install faiss-cpu2. 上传与处理 PDF 文件
利用 Streamlit 提供的文件上传器功能,用户可以方便地选择本地的 PDF 文件进行上传。上传后,系统会将文件内容保存为临时文件 “tmp.pdf”,以便后续处理。接着,借助 PDFPlumberLoader 库,能够快速准确地提取 PDF 文件中的文本内容,无需开发者手动进行复杂的文本解析工作。这一过程高效且准确,确保了系统能够获取到完整的文档信息,为后续的文本处理和分析提供了可靠的数据来源。
# Streamlit file uploader
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file:
# Save PDF temporarily
with open("tmp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load PDF text
loader = PDFPlumberLoader("tmp.pdf")
docs = loader.load()3. 策略性地分割文档
将提取的文本分割成合适的语义块是提高检索效率和回答准确性的关键步骤。通过 SemanticChunker 结合 HuggingFaceEmbeddings,能够根据文本的语义信息进行智能分割。这种分割方式不仅考虑了文本的长度,更重要的是能够将语义相关的内容划分到同一个块中,使得后续在检索和生成回答时,模型能够更好地理解上下文,提供更符合逻辑和语义的答案。例如,在处理技术文档时,能够将同一技术概念相关的段落划分到一起,便于模型准确地获取和利用相关信息。这里需要下载使用sentence-transformers/all-mpnet-base-v2模型。
# Split text into semantic chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)4. 创建可搜索的知识库
为了实现快速准确的检索,需要为分割后的文本块生成向量嵌入,并将其存储在 FAISS 索引中。向量嵌入能够将文本转换为计算机易于处理的数值向量形式,使得文本之间的相似度计算更加高效。HuggingFaceEmbeddings 提供了强大的嵌入生成功能,能够生成高质量的向量表示。FAISS 则是一款高效的向量数据库,它支持快速的相似性搜索,能够在大量向量中快速找到与查询向量最相似的文本块。通过设置检索参数 “k=3”,系统会在搜索时返回最相关的 3 个文本块,这与 DeepSeek R1 专注检索的特性相匹配,确保了系统能够快速获取关键信息,为生成准确的回答提供有力支持。
# Generate embeddings
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Connect retriever
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Fetch top 3 chunks5. 配置 DeepSeek R1 模型
在使用 DeepSeek R1 模型时,首先要通过 Ollama 实例化一个 1.5B 参数的模型实例。然后,精心设计一个提示模板,用于引导模型生成回答。提示模板明确规定了模型的回答规则:仅依据提供的上下文信息进行回答;在不确定答案时,回复 “我不知道”;并且将回答控制在 3、4 句话。这样的提示模板能够确保模型的回答既准确又简洁,避免了无关信息的干扰和冗长的回答,提高了用户体验。通过配置这个提示模板,让模型在生成回答时能够紧密围绕文档内容,充分发挥 RAG 系统的优势。
llm = Ollama(model="deepseek-r1:1.5b") # Our 1.5B parameter model
# Craft the prompt template
prompt = """
1. Use the following pieces of context to answer the question at the end.
2. If you don't know the answer, just say that "I don't know" but don't make up an answer on your own.\n
3. Keep the answer crisp and limited to 3,4 sentences.
Context: {context}
Question: {question}
Helpful Answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)6. 组装 RAG 链
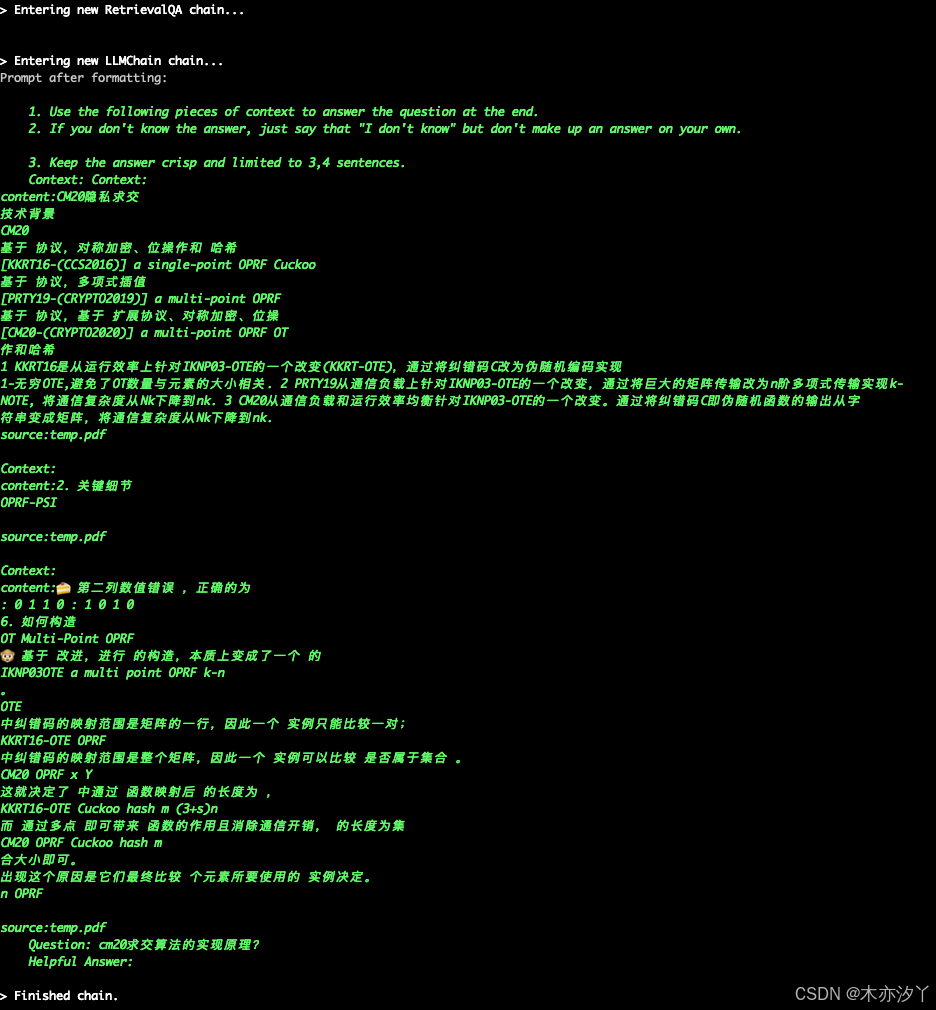
将文档上传、文本分割、检索以及模型回答等各个环节整合起来,形成一个完整的 RAG 链。通过 LLMChain 和 StuffDocumentsChain 的组合,将检索到的文档块与提示模板相结合,让模型能够根据上下文生成回答。RetrievalQA 则将检索和回答功能集成在一起,构建出最终的 RAG 管道。这样的架构设计使得系统能够自动完成从用户提问到检索相关文档块,再到生成回答的一系列操作,实现了信息处理的自动化和智能化,为用户提供了流畅的问答体验。
# Chain 1: Generate answers
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Chain 2: Combine document chunks
document_prompt = PromptTemplate(
template="Context:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Final RAG pipeline
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)7. 启动 Web 界面
借助 Streamlit 搭建的 Web 界面,用户可以直接在输入框中输入问题,与系统进行交互。当用户提交问题后,系统会迅速检索匹配的文本块,并将其输入到 DeepSeek R1 模型中进行分析和生成回答。回答结果会实时显示在页面上,让用户能够快速获取所需信息。在用户等待回答的过程中,Streamlit 的加载提示功能会显示 “Thinking...”,告知用户系统正在处理请求,提升了用户体验的友好性和交互性。通过这个 Web 界面,RAG 系统变得更加易用,即使是非技术人员也能轻松使用,大大拓宽了系统的应用范围。
# Streamlit UI
user_input = st.text_input("Ask your PDF a question:")
if user_input:
with st.spinner("Thinking..."):
response = qa(user_input)["result"]
st.write(response)8. 执行 streamlit run app.py

添加PDF文件,进行知识库的创建,创建完成后进入问答阶段。
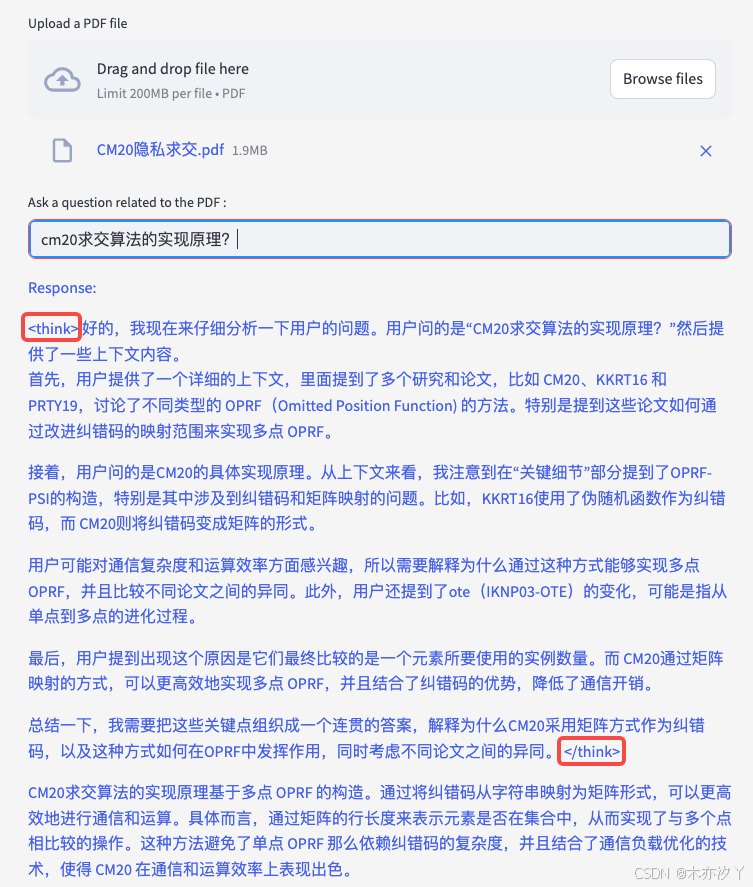
借助 DeepSeek R1 和 Ollama , 我们构建一套简单的RAG系统,为开发者提供了一种高效、低成本且安全可靠的解决方案。通过详细的步骤指导和丰富的技术支持,开发者能够快速搭建起满足自身需求的智能问答系统,充分挖掘文档数据的价值。虽然仅使用了1.5b的模型,但是依赖高质量的知识库和提示词模板,让结果看上去还不错。
完整代码 app.py
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
from langchain.prompts import PromptTemplate
from langchain.chains.llm import LLMChain
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import RetrievalQA
import os
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com' # 使用国内镜像
# color palette
primary_color = "#1E90FF"
secondary_color = "#FF6347"
background_color = "#F5F5F5"
text_color = "#4561e9"
# Custom CSS
st.markdown(f"""
<style>
.stApp {{
background-color: {background_color};
color: {text_color};
}}
.stButton>button {{
background-color: {primary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
.stTextInput>div>div>input {{
border: 2px solid {primary_color};
border-radius: 5px;
padding: 10px;
font-size: 16px;
}}
.stFileUploader>div>div>div>button {{
background-color: {secondary_color};
color: white;
border-radius: 5px;
border: none;
padding: 10px 20px;
font-size: 16px;
}}
</style>
""", unsafe_allow_html=True)
# Streamlit app title
st.title("Build a RAG System with DeepSeek R1 & Ollama")
# Load the PDF
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file is not None:
# Save the uploaded file to a temporary location
with open("tmp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load the PDF
loader = PDFPlumberLoader("tmp.pdf")
docs = loader.load()
# Split into chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
# Instantiate the embedding model
embedder = HuggingFaceEmbeddings()
# Create the vector store and fill it with embeddings
vector = FAISS.from_documents(documents, embedder)
retriever = vector.as_retriever(search_type="similarity", search_kwargs={"k": 3})
# Define llm
llm = Ollama(model="deepseek-r1:1.5b")
# Define the prompt
prompt = """
1. Use the following pieces of context to answer the question at the end.
2. If you don't know the answer, just say that "I don't know" but don't make up an answer on your own.\n
3. Keep the answer crisp and limited to 3,4 sentences.
Context: {context}
Question: {question}
Helpful Answer:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
llm_chain = LLMChain(
llm=llm,
prompt=QA_CHAIN_PROMPT,
callbacks=None,
verbose=True)
document_prompt = PromptTemplate(
input_variables=["page_content", "source"],
template="Context:\ncontent:{page_content}\nsource:{source}",
)
combine_documents_chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_variable_name="context",
document_prompt=document_prompt,
callbacks=None)
qa = RetrievalQA(
combine_documents_chain=combine_documents_chain,
verbose=True,
retriever=retriever,
return_source_documents=True)
# User input
user_input = st.text_input("Ask a question related to the PDF :")
# Process user input
if user_input:
with st.spinner("Processing..."):
response = qa(user_input)["result"]
st.write("Response:")
st.write(response)
else:
st.write("Please upload a PDF file to proceed.")


















 1309
1309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









